之前介绍的预训练模型都是将预训练过程和下游特定任务分成两阶段进行训练, Cross-View Training 将着来年各个阶段合并成一个统一的半监督学习过程:bi-LSTM 编码器通过有标注数据的监督学习和无标注数据的无监督学习同时训练。
之前介绍的预训练模型都是将预训练过程和下游特定任务分成两阶段进行训练, Cross-View Training 将着来年各个阶段合并成一个统一的半监督学习过程:bi-LSTM 编码器通过有标注数据的监督学习和无标注数据的无监督学习同时训练。
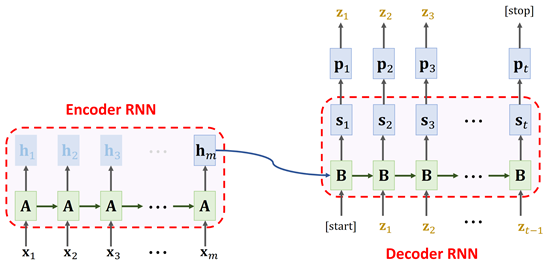
之前我们介绍过 seq2seq 模型,通常用作机器翻译,通过编码器(encoder)对源语言进行编码,然后通过解码器(decoder)对编码器的结果进行解码,得到目标语言。原始的 seq2seq 模型是使用平行语料对模型从头开始进行训练,这种训练方式需要大量的平行语料。Prajit Ramachandran 提出一种方法,可以大幅降低平行语料的需求量:先分别使用源语言和目标语言预训练两个语言模型,然后将语言模型的权重用来分别初始化编码器和解码器,最终取得了 SOTA 的结果。

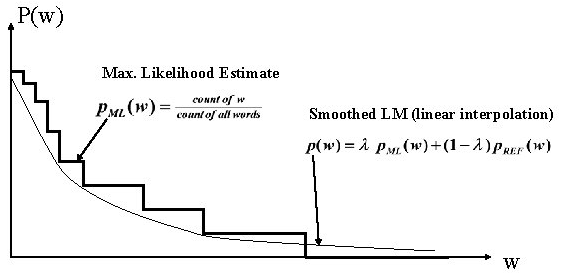
数据噪化(data noising)是一种非常有效的神经网络正则化的有段,通常被用在语音和视觉领域,但是在离散序列化数据(比如语言模型)上很少应用。本文尝试探讨给神经网络语言模型加噪声与 n-gram 语言模型中的平滑之间的联系,然后利用这种联系设计出一种噪声机制,帮助我们对语言进行建模。
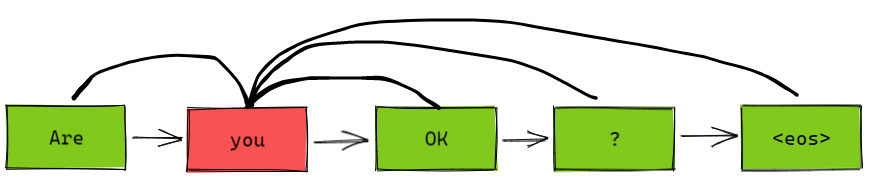
上下文的向量表示在许多 NLP 任务中都有至关重要的作用,比如词义消歧、命名实体识别、指代消解等等。以前的方法多是直接用离散上下文词向量组合,缺乏对上下文整体的优化表示方法。本文提出一种双向 LSTM 模型,有效学习句子上下文表征。
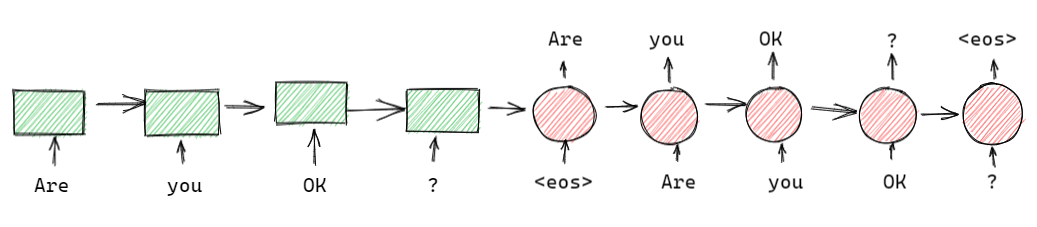
之前我们介绍了 Word Embedding,将词转换成稠密向量。词向量中包含了大量的自然语言中的先验知识,word2vec 的成功证明了我们可以通过无监督学习获得这些先验知识。随后很多工作试图将句子、段落甚至文档也表示成稠密向量。其中比较有代表性的,比如:
上一篇文章我们介绍了预训练词向量,它的缺点很明显:一旦训练完,每个词的词向量都固定下来了。而我们平时生活中面临的情况却复杂的多,一个最重要的问题就是一词多义,即同一个词在不同语境下有不同的含义。CoVe(Contextual Word Vectors)同样是用来表示词向量的模型,但不同于 word emebdding,它是将整个序列作为输入,根据不同序列得到不同的词向量输出的函数。也就是说,CoVe 会根据不同的上下文得到不同的词向量表示。
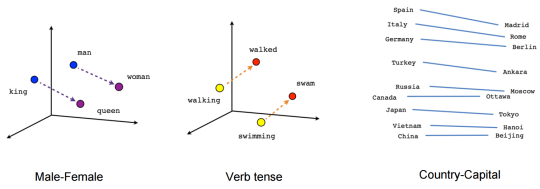
词嵌入(word embedding)是一种用稠密向量来表示词义的方法,其中每个词对应的向量叫做词向量(word vector)。词嵌入通常是从语言模型中学习得来的,其中蕴含着词与词之间的语义关系,比如 “猫” 和 “狗” 的语义相似性大于 “猫” 和 “计算机” 。这种语义相似性就是通过向量距离来计算的。

接下来,我们介绍 Schema、Identity 和 Context。在上一章,我们将以节点和边组成的数据集合称之为“Data graph”,而真正意义上的知识图谱(knowledge graph)是经过了 Schema(数据模式)、Identity(数据一致性)、Context(上下文)、ontology(本体)和 rules(规则)等表示方法增强过的 data graph。本章我们讨论 Schema、Identity 和 Context。Ontology 和 rules 在后面章节讨论。
目前,知识图谱在学术界和工业界都引起了重视。本人目前也开始负责知识图谱项目,因此从本文开始对知识图谱进行系统性的介绍。首先从综述入手可以使我们对知识图谱有一个整体的概念,然后对其中的每个细节进行深入介绍。本文来自论文《Knowledge Graphs》,是一篇长达 132 页(558篇引用)的综述,可谓干货满满,所以以这篇综述作为切入点。因为内容过长,所以我们将论文的每一章作为一篇博文,一共大概会有十几篇博文。
神经网络三大神器:DNN、CNN、RNN。其中 DNN 和 RNN 都已经被用来构建语言模型了,而 CNN 一直在图像领域大展神威,它是否也可以用来构建语言模型呢?如果要用 CNN 构建语言模型应该怎么做?接下来我们从四篇论文看 CNN 构建语言模型的三种方法。
统计语言模型中,无论是 n-gram 还是对数线性语言模型都面临一个非常严重的问题——维度爆炸。为了解决维度爆炸问题,Bengio & Bengio 2000 年提出了一种使用分布式词特征表示的方法,也就是后来所说的词向量。
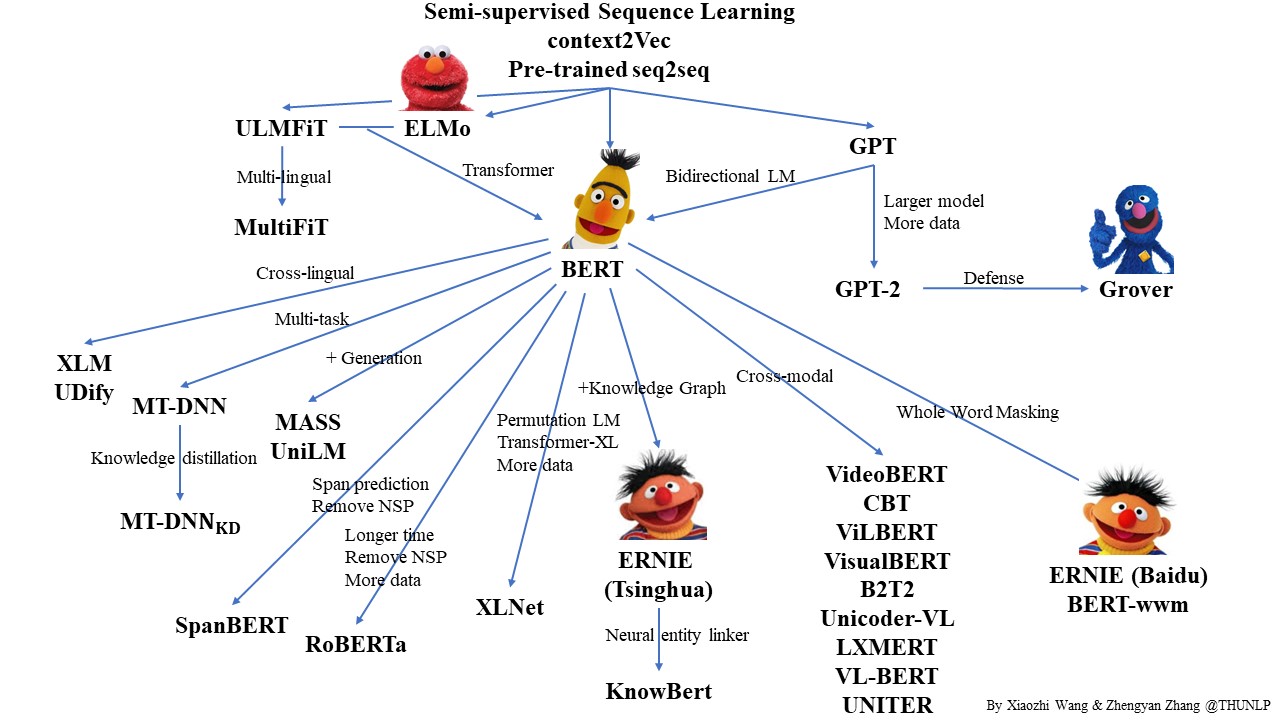
自从 2017 年 Vaswani 等人提出 Transformer 模型以后 NLP 开启了一个新的时代——预训练语言模型。而 2018 年的 BERT 横空出世则宣告着 NLP 的王者降临。那么,什么是预训练?什么是语言模型?它为什么有效?

Transformer 的功能强大已经是学术界的共识,但是它难以训练也是有目共睹的。本身的巨大参数量已经给训练带来了挑战,如果我们想再加深深度可谓难上加难。这篇文章将会介绍几篇就如何加深 Transformer 的展开研究论文。从目前的研究来看 Transformer 之所以难训是由于梯度消失的问题,要对 Transformer 进行加深就必须要解决这个问题,今天我们介绍三种方法:
我们仔细回想一下 Transformer 在计算自注意力的过程, 我们会发现,序列中每个词在与其他词计算注意力权重的时候是无差别计算的。也就是说,这里隐藏着一个假设:词与词之间的距离对语义依赖是没有影响的(抛开位置编码的影响)。然而,根据我们的直觉,距离越近的词可能依赖关系会更强一些。那么事实是怎样的呢?Guo 等人 2019 对这个问题进行了研究,并提出 Gaussian Transformer 模型。
Levenshtein Transformer 不仅具有序列生成的能力,还具有了序列修改的能力。然而我们会发现,整个模型实际上是很复杂的。从模型结构上讲,除了基础的 Transformer 结构,还额外增加了三个分类器:删除分类器、占位符分类器和插入分类器。从训练过程来讲,LevT 需要一个参考策略(expert policy),这个参考策略需要用到动态规划来最小化编辑距离。这样无论从训练还是才能够推理角度,我们都很难保证模型的效率。那么有没有一个既有 LevT 这样的强大的能力,又保持高效简洁的模型呢?Insertion-Deletion Transformer 就这样应运而生了(内心 os:你永远可以相信宋义进:joy:)。
之前我们介绍了几个 Insertion-based 的序列生成的方法,使我们跳出传统的从左到右的生成顺序的思维定式。既然有 Insertion 操作,那么一个很自然的想法就是,我们能不能再加入一个 deletion 操作呢?这样我们不仅能生成序列,还可以修改生成的序列,岂不美哉?Gu et al. (2019) 就针对这种想法提出了 Levenshtein Transformer 的模型。Levenshtein Distance 我们不陌生,也就是编辑距离,这里面涉及到三种操作:insertion、deletion、replace,严格意义上来讲 replace 实际上就是 insertion 和 deletion 的组合,所以 LevT 模型只用到了插入和删除操作。
之前我们介绍的 insertion-based 生成模型实际上都是人为预先定义了生成顺序或者策略,那么我们能不能让模型自己决定要以怎样的顺序生成呢?这就是本文将要讨论的一种解决方案:Insertion-based Decoding with automatically Inferred Generation Order,将序列的生成顺序当成一种隐变量,让模型在预测下一个词的时候自动推理这个词应该所处的位置。
之前我们介绍的两种 insertion-based 文本生成方法预先规定了每次生成最中间的词,这样一来我们虽然利用树实现了并行,但是却丢失了其中的生成模式,我们不知道模型在生成的时候经历了什么。那么我们能不能让模型自动生成一棵树呢?比如,现在生成了一个根节点,然后再生成左右子节点,然后再生成子节点的子节点,以此类推,但不同的是,这棵树不一定平衡,甚至可能退化成一条链,但我们获得了模型的生成模式,如下图所示:
我们注意到 Insertion Transformer 提出一种很有意思的文本生成框架:Insertion-based 。但是它仍然使用的是Encoder-Decoder 框架,这种框架有一个缺陷,就是 $(x, y)$ 无法对 联合概率 $p(x, y)$ 进行建模。对此 William Chan 等人于 2019 年提出一种新的架构:KERMIT,该模型抛弃了传统的 Encoder-Decoder 架构,使得我们能对 $p(x, y)$ 联合概率进行建模。训练阶段可以通过句子对 $(x, y)$ 获得联合概率 $p(x, y)$,也可以通过非句子对分别获得边缘概率 $p(x)$ 或者 $p(y)$。推理阶段我们可以获得条件概率 $p(x|y)$ 和 $p(y|x)$。
传统的文本生成,比如机器翻译无论是自回归或者半自回归的推理方式,都有一个特点:通常是自左向右依次生成文本序列。本文将介绍一篇文章,打破思维定式,突破自左向右的顺序生成。Insertion Transformer采用随机插入式序列生成:
Insertion Transformer不仅在效果上远超非自回归模型,而且能以$log(n)$的推理速度,效果上达到原始Transformer的水平。
目前来看,自注意力机制有一统NLP的趋势,其凭借能够捕捉序列中任意两个元素的关联信息,且易于并行等优势,在与传统的NLP武林盟主RNN的较量中,几乎是全方位碾压。但是它也并不是没有弱点,之前我们介绍过在机器翻译过程中,它的推理过程是auto-regression的,严重制约了它的推理效率。因此,很多研究人员对它做了一定程度上的改善。今天我们继续来对它进行其他方面的优化,也就是变形金刚家族的另一成员 —— Sparse Transformer。
本文将继续介绍关于transformer在 non-auto regression方面的研究,今天要介绍的是Google Brain的工作Blockwise Parallel Decoding for Deep Autoregressive Models。
接下来我们介绍一下Sharing Attention Weights for Fast Transformer这篇文章。实际上这篇文章之前还有两个关于加速Transformer推理的文章,一个类似Latent Transformer的引入离散隐变量的类VAE的方法,另一个是引入语法结构达到non-auto regression的方法。个人感觉没什么意思,就直接跳过了。本文要介绍的这篇文章比较有意思,引入共享权重的概念。从近期关于Bert小型化的研究(比如DistilBERT,ALBERT,TinyBERT等)来看,实际上Transformer中存在着大量的冗余信息,共享权重的方法应该算是剔除冗余信息的一种有效的手段,因此这篇文章还是比较有意思的。
从题目就可以看出来,本文将要介绍一种半自动回归的机器翻译解码技术。之前我们介绍了各种非自动回归的解码技术,其中有一个Latent Transformer是先用auto-regression生成一个短序列,然后用这个短序列并行生成目标序列。当时我们说这其实算是一种半自动回归的方法。今天我们要介绍另一种半自动回归的方法——SAT。
本文继续介绍关于transformer在non-auto regression方面的研究,今天要介绍的是Gu et al. 2018 发表在ICLR 2018上的文章Non-autoregressive neural machine translation 。
之前提到Auto-regression的decoding方法使得transformer在推理上的表现很慢,所以很多研究者在这方面做了很多研究,本文就介绍一个使用Non-Auto Regression的方法——Discrete Latent Variable。该方法与Auto-regression方法相比,效果上要稍差 一些,但是取得了比其他Non-auto regression方法都好的结果,而效率上也有很大的提升。
Transformer虽然在训练上比RNN和CNN快,但是在做推理(decoding)的时候由于采用的是Auto-regression不能做到并行计算,所以速度很慢(甚至可能比纯RNN还要慢),所以针对这种情况很多研究者提出了decoding时也能采用并行计算的改进方案,下面要介绍的这个transformer大家族的以为成员就是其中之一:Average Attention Network。
Transformer现在已经被广泛应用于NLP领域的各项任务中,并且都取得了非常好的效果。其核心层使用了自注意力机制,关于为什么使用自注意力机制,作者提出了三点原因:
前面介绍了Transformer的模型结构,最后也给出了pytorch版本的代码实现,但是始终觉得不够过瘾,有些话还没说清楚,因此,这篇文章专门用来讨论Transformer的代码细节。
Transformer 的模型框架我们已经介绍完了,接下来这篇文章我们讨论一下更多关于 Transformer 的模型细节。比如多头注意力的头越多越好吗?自注意力为什么要进行归一化?训练的时候 Warm-up 有什么用?