
1. 序言
1.1 什么是知识建模(语义建模)?
通过赋予数据指定的概念和数据之间的关系使数据包含语义。
本质上讲,我们是通过明确数据代表的概念以及概念之间的关系来对数据进行建模。这样一个知识模型必须同时被人类和计算机所理解。对于人类来说相对比较容易,因为我们可以通过文字和数字对任意我们想要的东西进行建模,更重要的是赋予计算机更多的思考。
1.2 我们为什么要知识建模?
对于数据来说,上下文信息非常重要。比如 “苹果”,我们是在讨论苹果电子产品还是水果?作为人类,当给定上下文的时候,我们可以很轻易的判断我们在讨论什么。当我说,“昨天买的苹果真好吃!”没有人会觉得我啃了一部手机。这就是问题的关键,没有上下文,数据所携带的信息总是不明确的。知识模型就是赋予数据以意义,避免这种歧义。
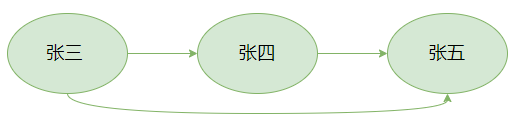
另外,还可以通过概念之间的关系帮助我们发散思维,找到数据之间的关联性。比如,“张三”是“张四”的父亲,而“张四”又是“张五”的父亲。人类可以很轻易的发现“张三”和“张五”是祖孙关系,但是如果没有知识模型构建的数据之间的关系,那么计算机是无法得知“张三”与“张五”的关系的。
1.3 Led Zeppelin 乐队知识模型
解释知识模型最好的方式就是举例子。下图展示了一个 Led Zeppelin 乐队简单的知识模型,包括一些与 Led Zeppelin 相关的概念和概念之间的关系。从图中我们可以看到, Led Zeppelin 是一个乐队,它有一张专辑叫做 “ Led Zeppelin IV”,这张专辑发布于 “1971年11月8日”,专辑中有一首歌叫做 “Black Dog”。“Jimmy Page” 是一个人,也是乐队的成员之一。当然这只是一小部分数据,我们仅仅用这部分数据作为一个例子进行介绍。
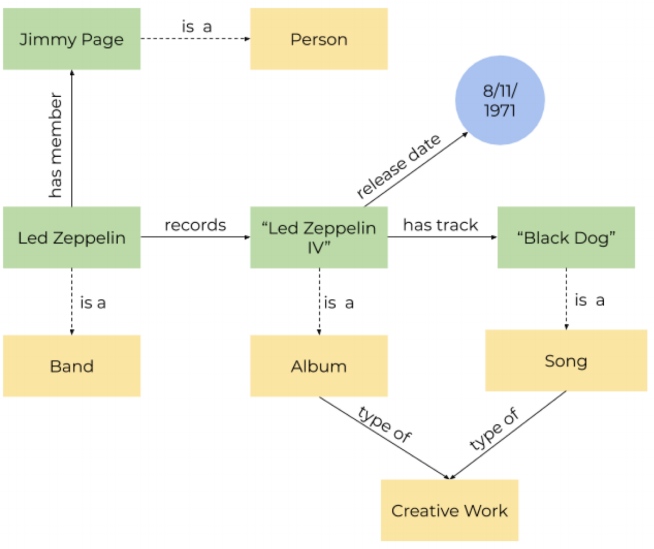
知识模型也可以将信息排列成层次结构。比如“唱片”和“歌曲”都是“具有创造性的作品”,同时“具有创造性的作品”还包括“书籍”、“电影”、“雕塑”等等。
上图中大多数的关系都是用实线箭头连接的,除了 “is a” 关系是用虚线箭头连接的。这是因为 “is a” 代表了一类特殊的关系——“rdf:type”。现在先不用管这啥,在后面的章节会介绍。
2. 知识模型基础
虽然我么现在有了一张看起来很漂亮的图,但是如果计算机不能理解这张图,再漂亮也白搭。如何让计算机从图中抽取语义信息?下面我们就来介绍一个非常有用的工具——RDF。
2.1 理解 RDF
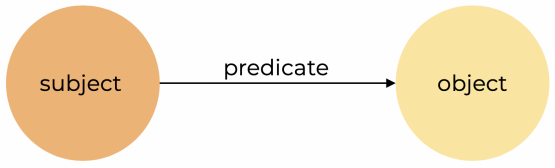
RDF(Resource Description Framework),翻译成中文:“资源描述框架”。顾名思义,它是一个用来描述数据的框架。在 RDF 数据模型中,我们用三元组来描述数据。一个三元组包含:subject、object 和 predicate,我们可以简单理解为,一个三元组就是有最简单的“主谓宾”构成的事实描述。RDF 图就是将很多三元组组合起来,其中 subject 和 object 是节点,predicate 是边。
对于 RDF 来说,节点有三种类型:
- Resources:你想要描述的概念,比如 Led Zeppelin 乐队知识模型图中的矩形框中的内容。所有的概念都必须有一个唯一的标识符。
- Literals:即字面量,所有的字面量必须是字符串、数字和日期,如 Led Zeppelin 乐队知识模型图中的圆形框中的内容。
- Blank nodes:空节点表示没有唯一标识符的数据。
2.2 URI
所有的 resources 和 predicates 都必须有机器可读的唯一标识符。
为什么标识符的唯一性这么重要?比如,我们要对一个大型组织结构的雇员进行建模,其中可能有很多同名同姓的人,不考虑每个人的昵称的话,你怎么区分到底是财务室的张三,还是技术部的张三,又或者是食堂大厨张三?解决的办法就是每个人都分配一个唯一的标识符——Uniform Resource Identififiers(URIs)。
URI 是一个字符串,用来准确的辨认特定的资源。为了保证统一性,所有的 URI 都有预定义的语法规则。
URI 与我们平时上网的时候,各个网站的 URL 很像。URI 可以是层级结构的(hierarchical URIs),也可以是不透明的(opaque URI)。Hierarchical URI 会包含不同级别的信息,它可以编码资源的位置信息,即资源存放在模型中的哪个位置,或者共享资源的上下文信息。而 opaque URI 不会编码任何信息,它的后缀通常是随机字符串。
- Hierarchical:<http://mycompany.com/people/JediDepartment/LukeSkywalker >
- Opaque:<http://mycompany.com/AE04801 >
上例中 hierarchical URI 是人类可读的。从中我们知道 Luke Skywalker 为 My Company 工作,他是 Jedi Department 部门的员工。Opaque URI 同样是代表的 Luke Skywalker,但我们很难从中读取到任何信息。这就意味着 Opaque URI 的隐私性非常强。Opaque URI 的另一个优点是,不需要经常更新。比如如果 Luke Skywalker 变更了工作,从 Jedi Department 部门调到财务部门。Opaque URI 不需要做任何变更,而 Hierarchical URI 就要跟着改变。
从上面的例子中,我们可以看到两种 URI 各有优劣势,那么什么样的 URI 是一个好的 URI 呢?对此 European Bioinformatics Institute 给出了几个性质,总结起来就是:
- 全局唯一性:一个 URI 决不能被两个不同的概念同时引用,即使两个概念是等价的。
- 持久性:在可预见的将来,URI 要保证可用性。
- 稳定性:一个 URI 决不能在不同的数据上重复使用,即使原来的版本已经删除了。
- 可解析性(不可引用性):简单来说就是,当用户在自己的浏览器上点击 URI 的时候,我们希望浏览器能重定向到合适的文档。
在介绍 Skywalker 的时候,我随便造了一个 URI,用浏览器访问的时候会返回给你“404 Page Not Found”,也就是说这个 URI 不是一个好的 URI,因为它不满足上面第四个性质:可解析性。
下面我们回到 Led Zeppelin 的例子。我们用 URI 来表示三元组:
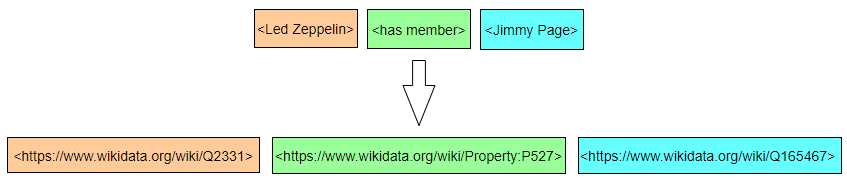
当我们点击上面的 URI 的时候,浏览器会给我们展示相关的资源页面,比如:

上面我们是将一个三元组用 URI 来表示,而我们要做的是将所有的三元组都用 URI 来表示。但是全部都用完整的 URI 的话显得多余,所以我们可以用前缀:
- 用
@prefix作为定义前缀的开始; - 选择前缀名;
- 描述前缀的命名空间;
- 以句号
.结尾.
比如:
1 | @prefix wd: <https://www.wikidata.org/wiki/>. |
现在回到上面的例子:
1 | @prefix wd: <https://www.wikidata.org/wiki/>. |
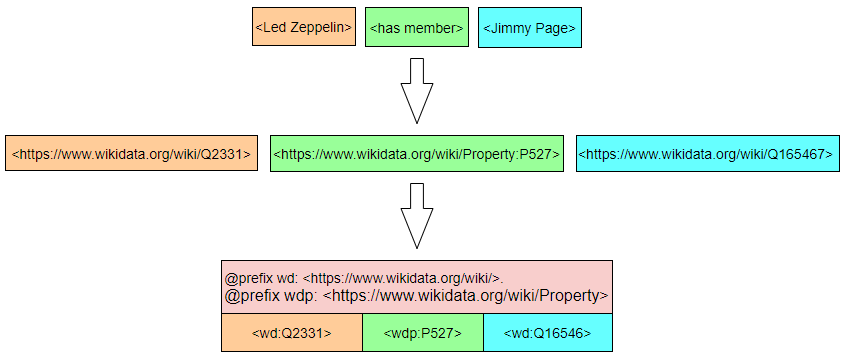
现在我们就可以将整个图用 URI 来表示了:
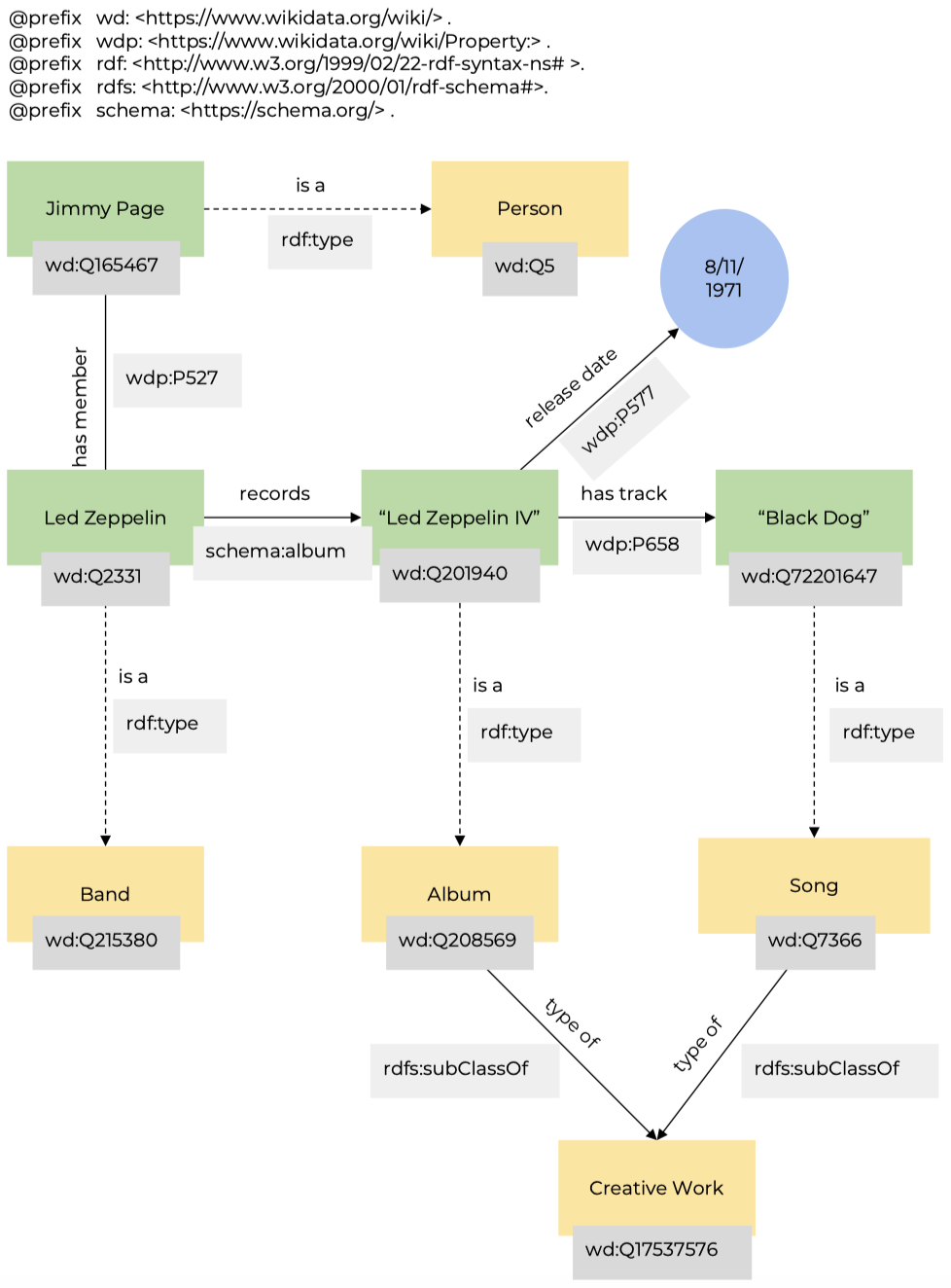
从图中我们可以看到,大多数的 URI 都是源自 Wikidata,少部分看起来有点奇怪,比如 schema、 rdf、rdfs。在介绍这几个比较奇怪的 URI 之前,我们再多说点关于空节点,即 “blank node” 的事情。
2.3 Blank node
空节点表示没有 URI 或者没有 Literal 的资源。听起来好像空节点是非法节点,但是实际上 RDF 允许这种情况的存在。必须说明的是,空节点只能出现在节点上,边是不允许的。空节点的 URI 并非是未知的,而是匿名的。当你想要表示一个复杂的资源特征,但是又不知道特征的名字,比如具体地址的街道门牌号。又或者你希望保护一些信息的隐私。类似于 “<张三>,<生日>,<*>”,我告诉你张三有一个属性叫做生日,但是我不告诉你他的生日是多少。
2.4 RDFS
RDFS 即 “RDF Schema”,本质上是一个知识建模的词表,用来表示 RDF 知识模型。RDFS 包含了一系列的属性和其他机制用于描述知识以及知识之间的关系。
在介绍 RDFS 之前需要搞清楚,我们为什么需要这样一个词表?在我们最初引入 Led Zeppelin 例子的时候,把虚线箭头以下的部分去掉似乎并不影响整体性。实际上这种知识建模的技术就是诞生于 20 世纪 60 年代的语义网络。语义网络有一定的优点,比如容易理解、相关概念容易聚类等。如上面例子展示的,对我们人类来说,整张图的概念很清晰,关系也很明确。但是这样一个图有一个非常严重的问题:
没有标准!
- 节点和边的值没有标准,完全由用户自己定义。
- 多源数据融合困难。比如三元组1(鱼,住在,水里),三元组2(鱼,生活在,水里),对于我们人类来说,两个三元组描述的是同一个事实,应该融合成一个三元组。但是对于计算机来说,它无法理解“住在”和“生活在”是同一概念,所以就没有办法自动融合在一起。
- 无法区分概念和实例。比如在语义网络中(鱼,是,动物)中,“鱼”和“动物”是同级的概念。而我们很清楚,他们是有上下位关系的。
为了解决语义网络存在的各种缺点,所以 W3C 制定了统一的标准,而这些标准就是相当于是由权威机构发布一些词汇,用来标准化常见的概念。比如,语义网络中
鱼,是,动物
羊,是一种,动物
我们将 “是”、“是一种”统一成 rdf:type,其中 rdf 表示前缀,完整的 URI 为 http://www.w3.org/1999/02/22-rdf-syntax-ns#type。这样既完成了标准化,也实现了 URI。
2.4.1 RDFS 常用词汇
下面我们就来介绍,RDFS 是如何构建标准化词表的。首先先介绍 “类” 的概念:
知识可以被分成很多组,这些组称之为“类(class)”,这些类的成员就是“实例(instance)”。类和实例可以通过 URI 加以区分,也可以通过 RDF 属性加以描述。比如
rdf:type就是用来描述是个实例属于某个类别:鱼,
rdf:type,动物类也可以有子类 “subclass”,所有子类的实例也是类的实例。
属性(property) 表示连接 subject 和 object 的边,即 predicate。
用 RDFS 中一些重要的 Schema:
rdf:Class:定义类节点。比如 “Led Zeppelin”,“Led Zeppelin IV”,“Black Dog”,“Jimmy Page” 都是类。rdfs:Literal:用于定义节点的字面量,即字符串或者数字等。比如 “1971/8/11”。• NOTErdfs:Literal本身是一个类,同时也是rdf:Class的实例。rdf:Property:属性,即连接节点的边,还可以通过rdfs:subPropertyOf定义子属性。有一个很特殊而又常用的属性rdf:type用来描述一个实体是一个类别的实例,特殊在于我们经常缩写成a。rdfs:domain和rdfs:range:用来指定rdf:Property的定义域和值域。1
2
3
4
5
6
7
8
9<hasMember> a rdf:Property .
<hasMember> rdfs:domain <Band> .
<hasMember> rdfs:range <Person> .
# 用自然语言描述就是:
# <hasMember> 是一条边
# 定义域(subject)是<Band>
# 值域(object)是<Person>
# 等效于: <Band> <hasMember> <Person>rdfs:subClassOf:定义类的子类,可以用来构建层级关系。比如,1
<musician> <rdfsLsubClassOf> <Person>
rdfs:label和rdfs:comments:之前介绍的 RDFS 词汇使数据变成计算机可读,但是我们还是希望对人类也可读。rdfs:label是给一个节点人类可读的名字,帮助我们理解该节点,对 opaque URI 尤其有用。rdfs:comment给节点添加文本描述,有点类似于给代码加注释。比如:1
2<hasMember> rdfs:label “has member” .
<hasMember> rdfs:comment “Property relating a band to one of its band members” .
2.5 OWL
RDFS 是节点和关系的标准化词汇表。随着技术的发展,人们发现 RDFS 的表达能力相当有限,因此提出了OWL。我们可以把 OWL 当做是 RDFS 的一个扩展,其添加了额外的预定义词汇。
OWL 也定义了类、属性和实例。不同于 RDFS,OWL 有更丰富,更严格的词汇表。这里可能会有一个疑问:既然 OWL 覆盖了 RDFS 大部分词汇,而且比 RDFS 表达能力更强,那我们为什么还要用 RDFS?
这就有点像牛刀可以用来杀鸡,但是不提倡,道理是一样的。虽然 OWL 表达能力更强,但是同时要求也更严格。当我们构建的知识模型本身就比较简单的时候, RDFS 就足够了。
OWL 的好处是,它支持和集成了 RDFS 的元素。比如 在OWL 里你仍可以用 rdf:type、rdfs:range、rdfs:subPropertyOf 等。
另外, OWL 也定义了自己的词汇,这些词汇比 RDFS 更细致。可以对一些属性添加约束,比如 owl:allValuesFrom 可以定义类的取值范围。
1 | <hasParent> owl:allValuesFrom <Human> . |
OWL 也支持用一系列操作来描述知识。比如,owl:unionOf 可以用来表示类,比如水果,包含甜水果和不甜的水果。owl:unionOf 的 subject 也可以是空节点。
1 | <Fruit> owl:unionOf ( <SweetFruit> <NonSweetFruit ) . |
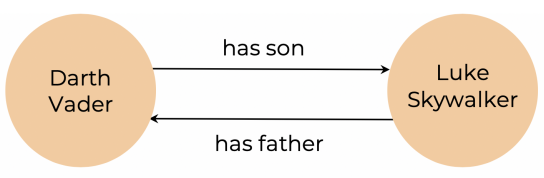
我们还可以用 OWL 定义反向关系。还记得上面 Darth Vader 和 Luke 的例子吗?我们可以通过 owl:inverseOf 来定义 “
1 | <hasSon> owl:inverseOf <hasFather> . |
OWL 中另一个重要的词汇是 owl:sameAs,它用来表示两个实体是相同的。比如:
1 | <BillClinton> owl:sameAs <WilliamJeffersonClinton> . |
另一个用来表示两个类是等价的词汇是 owl:equivalentClass:
1 | <USPresident> owl:equivalentClass <PrincipalResidentOfWhiteHouse> . |
说两个事情是等价的看起来有点多余,但是这确实是 OWL 的一大优势。用“等价”描述可以很轻松的引用外部知识模型和本体。比如,你可以说 wikidata 中的 Al Pacino 和 IMDB 中的 Al Pacino 是等价的。这个在帮助你构建知识模型的时候省掉很多工作。
最后, WOL 还可以定义两种不同的 property:
- Object property:实体与实体之间的关系(<hasMember >)
- Data propery:实体与属性的关系(<birthDay >)
3. 知识建模的步骤
前面我们介绍了关于知识模型的理论,接下来就是如何用上面的理论一步一步从头构建一个知识模型。在实际的项目当中,不建议自己从头构建知识模型。现在有很多领域已经有专家、工程师构建好的知识模型,我们可以以此为基础进行开发。本文是为了介绍相关知识,所以介绍从头构建知识模型的内容。
这里我们主要介绍两点:
- RDF 知识模型的语法,或者更正式一点的说法——RDF 数据的序列化。
- 帮助我们进行知识建模的工具——Protege。
3.1 RDF 序列化
RDF 是一种知识描述框架,本质上也是一种模型。而序列化就是要讲这种描述框架落到实处。就像算法本身只是一种数学模型,而要如何实现算法就具体依赖你使用什么编程语言。RDF 三元组的序列化就是使用“编程语言”把它实现出来。RDF 序列化方法有多种:
RDF/XML:就是用XML的格式来表示 RDF 数据。之所以提出这个方法,是因为 XML 的技术比较成熟,有许多现成的工具来存储和解析 XML。然而,对于 RDF 来说,XML 的格式太冗长,也不便于阅读,通常我们不会使用这种方式来处理 RDF 数据。
N-Triples:即用多个三元组来表示 RDF 数据集,是最直观的表示方法。在文件中,每一行表示一个三元组,方便机器解析和处理。
- Turtle:应该是使用得最多的一种 RDF 序列化方式了。它比 RDF/XML 紧凑,且可读性比 N-Triples 好。
- RDFa:即“The Resource Description Framework in Attributes”,是 HTML5 的一个扩展,在不改变任何显示效果的情况下,让网站构建者能够在页面中标记实体,像人物、地点、时间、评论等等。也就是说,将 RDF 数据嵌入到网页中,搜索引擎能够更好的解析非结构化页面,获取一些有用的结构化信息。
- Json-LD:即“JSON for Linking Data”,用键值对的方式来存储 RDF 数据。
我们以 Turtle 为例进行介绍,因为如上所述,它是目前用的最多的一种序列方法。Turtle 简称 TTL,表示 Time To Live。
Turtle
为了解释 TTL,我们从 TTL 的官网 借来一个例子:
1 | @base <http://example.org/> . |
下面我们详细介绍这个例子。
1-5 行:定义前缀。任何好的 TTL 文件都是先定义前缀。其中 2-3 行是我们之前介绍的
rdf和rdfs,4-5 行是两个新词foaf和rel。第 1 行base是比较特殊的前缀,它表示一个基础的 URI,所有 “<>” 内的内容都是属于它的命名空间。需要注意的是,每一行都必须有 “.” 作为结束。7-9 行:描述了一条关于“<#green-goblin>”的知识。
<#green-goblin>就是以@base为前缀的节点,等价于<http://example.org/#green-goblin>。rel:enemyOf表示以rel为前缀的关系,等价于<http://www.perceive.net/schemas/relationship/enemyOf>。后面的<#spiderman>和<#green-goblin>类似。a表示rdf:type,后面的表示法都与之前类似。- 这三行描述的信息是:Green Goblin 有一个敌人叫做 Spiderman,Green Goblin 是一个人,Green Goblin 的名字叫做 Green Goblin。
- 字符串用双引号表示。
- 注释用 “#” 。
- 每一个三元组都以 “空格 .” 结尾。
每一个三元组都写 <#green-goblin> 有点重复,显得笨重又耗时。我们可以用 predicate list 的方法,将有相同 subject 的描述组合在一起,每条 predicate-object 描述用 “;” 分割。然后最后一条 predicate list 用空格和句号结束。我们将 7-9 行和11-13 行改造如下:
1
2
3
4
5
6
7
8
9<#green-goblin>
rel:enemyOf <#spiderman> ;
a foaf:Person ; # in the context of the Marvel universe
foaf:name "Green Goblin" .
<#spiderman>
rel:enemyOf <#green-goblin> ;
a foaf:Person ;
foaf:name "Spiderman", "Человек-паук"@ru .我们来看改造后的第 9 行。Spiderman 有两个名字,一个是英文名,另一个是俄文名。两个英文名之间用 “,” 分割。在俄文名的引号后面有一个语言标签
@ru。语言标签有两部分组成@和 语言关键词。
除了上面的例子展示的一些语法,Turtle 还有一些其他语法。比如可以使用 xsd 里指定数据类型,比如日期、字符串、数字等。更详细内容可查看官网。
另外,如果你之前已经用一种序列化方法实现了一个知识模型,现在处于某种原因,你想换成另一种序列化方法。不要紧,可以试试这个小工具。
3.2 知识建模工具
在我看来,有两种方法构建知识模型:
- 在文本编辑器中写三元组(手动或者自动)。
- 用工具创建三元组。
就个人而言,我更喜欢前者。因为这样我们可以完全掌控我们要构建的知识模型。更重要的是,不需要从头学习一个工具的使用。当然,这纯属是个人原因。如果你找到一款趁手的工具,完全没必要手写三元组。如果你要手写三元组的话,这里推荐一个 python 包 —— rdflib。
考虑使用工具的话,现在市面上的开源而又实用的工具只有 Protégé。
Protégé 是斯坦福大学开发的一款本体(本文提到的“本体”等效于“知识模型”)建模工具。包括网页版和桌面版。
基本上,Protégé 允许用户添加类、对象和数据属性和实例,不需要手写三元组。用过给类添加子类来构建层级结构。知识建模完成以后可以将文件保存成 OWL 文件。
3.3 按步骤构建知识模型
斯坦福大学不仅开发了知识建模工具,还发表了一篇文章叫我们怎样进行知识建模——《Ontology Development 101 guide》。更详细的内容可以看另一篇文章:知识图谱:知识建模(二)构建本体的方法论,或者去看原文。
总的来说,知识建模有三大原则:
- 对于一个领域来说,没有一个唯一正确的建模方法。我们可以用不同的方法进行建模。最好的方法依赖于实际应用和需求。
- 本体构建(知识建模)需要不断迭代。
- 本体中的概念和关系应该接近你感兴趣的领域(物理上或逻辑上)。
具体步骤如下:
- 确定知识领域及范围,即应用场景。
- 确定知识模型的重要概念。
- 本体复用。
- 定义类,类的层级结构以及关系。
- 定义限制条件。
3.4 可视化知识模型
无论你是怎么建模的,最后你都希望看下你建模出来的知识模型长什么样子。可视化工具有两种:
Protege 自带的插件 OntoGraf。
在菜单中选择 Windows -> Tabs -> OntoGraf
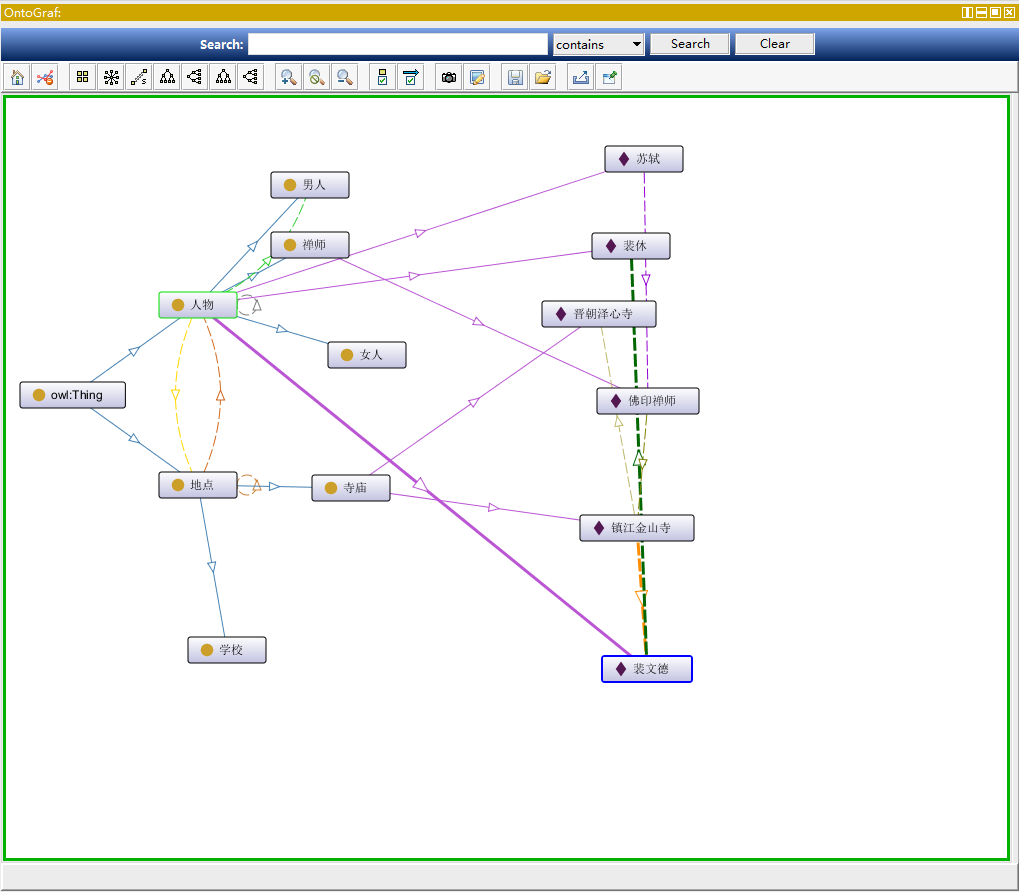
网页工具 WebVOWL。
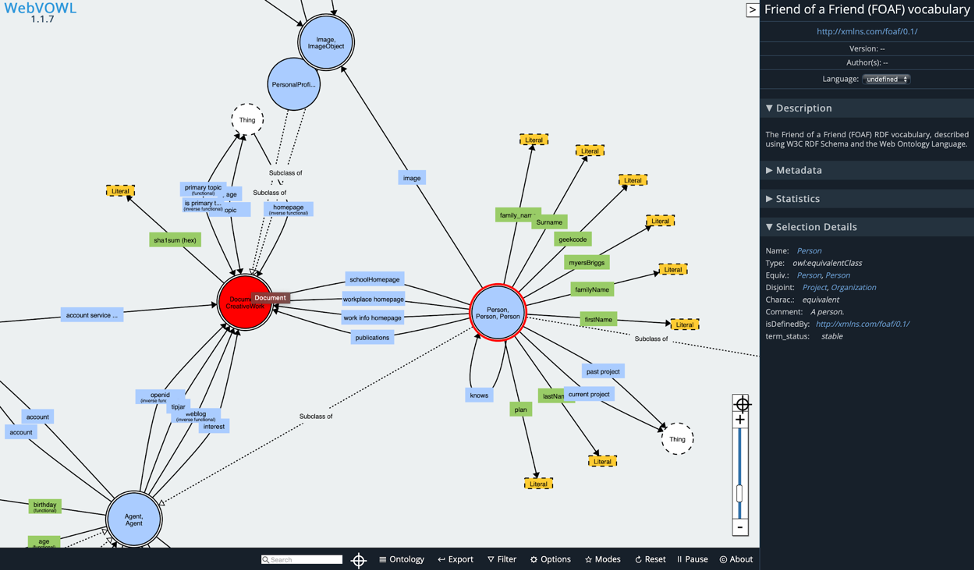
4. 知识模型查询
在知识建模的时候,我们提到知识建模的目的是希望它能回答我们一些什么问题。现在,我们就要介绍一下我们该怎么像知识模型问问题。
4.1 SPARQL
SPARQL 是 “SPARQL Protocol and RDF Query Language” 的首字母缩写。SPARQL 对 RDF 来说,就像 SQL 对关系型数据库一样。如果你会一点 SQL,那 SPARQL 学起来也会比较快。
我们用下面的例子做一个简单的介绍:
例 1:
数据:
1
2
3
4
5@prefix schemaL <http://schema.org> .
@prefix wd: <http://www.wikidata.org/wiki/> .
wd:Q2331 schema:album wd:Q201940 .
wd:Q2331 schema:album wd:Q209539 .上面这两个三元组相当于:Led Zeppelin (wd:Q2331) 有两张专辑,分别是 wd:Q201940 和 Q209539。
Query:
1
2
3
4
5
6
7@prefix schemaL <http://schema.org> .
@prefix wd: <http://www.wikidata.org/wiki/> .
SELECT ?album_name
WHRER {
wd:Q2331 schema:album ?album_name .
}这一条查询语句包括两部分:
- SELECT:定义我们要查询的变量(album_name),以 “?” 开头。
- WHERE:定义了基本的匹配模式。
上面的查询语句返回结果是:
1
2wd:Q201940
wd:Q209539例 2:
数据:
1
2
3
4
5
6@prefix schemaL <http://schema.org> .
@prefix wd: <http://www.wikidata.org/wiki/> .
@prefix wpd: <http://www.wikidata.org/wiki/Property> .
wd:Q201940 a wd:208569; # Led Zeppelin IV 是一张专辑
wd:P1449 "Led Zeppelin IV" # 有一个名字叫做 “Led Zeppelin IV”上面两条三元组的意思是:Led Zeppelin IV 是一张专辑,Led Zeppelin IV 的名字是 “Led Zeppelin IV”。现在我想查询所有叫做 “Led Zeppelin IV” 的专辑,那我可以用下面的查询语句:
Query:
1
2
3
4
5
6
7
8@prefix schemaL <http://schema.org> .
@prefix wd: <http://www.wikidata.org/wiki/> .
@prefix wpd: <http://www.wikidata.org/wiki/Property> .
SELECT ?album
WHERE {
?alubm wd:P1449 "Led Zeppelin IV" .
}同样,在 SELECT 语句中以 “?” 开头定义我们需要查询的变量,在 WHERE 中定义查询模式。最后返回结果:
1
wd:Q201940
以上两个例子都是非常基础的查询语句。Stardog tutorial 是一份非常好的 SPARQL 教程,我们可以在这里找到更详细的介绍。
4.2 SPARQL endpoint
前面我们已经将某一领域的知识建模完成了,存成了 .ttl 文件。实际上这个 .ttl 文件是一个文本文件。我们说知识查询需要用到 SPARQL 查询语言。但是对于一个文本文件来说,我们能做的似乎只有字符串匹配或者正则匹配。SPARQL 语句应该在哪里输入?又在哪里执行?在哪里输出结果?也就是说,现在我们的知识模型文件和知识查询之间形成了一个断层。填补这个断层的就是 endpoint。这里我们介绍三种 SPARQL endpoint:
- D2RQ SPARQL endpoint
- Apache jena SPARQL endpoint
- rdflib
4.2.1 D2RQ SPARQL endpoint
SPARQL endpoint 用于处理客户端的请求,可以类比web server提供用户浏览网页的服务。通过endpoint,我们可以把数据发布在网上,供用户查询。
D2RQ 是以虚拟 RDF 的方式访问关系型数据库的一个工具。也就是说,假设我们原来的数据是存储在关系型数据库中的,我们不需要把这些数据手动转成 RDF 型数据,就可以通过 D2RQ 使用 SPARQL 语句而不是 SQL 语句进行查询。
它的工作原理也很简单,就是 D2RQ 会根据关系型数据库的表结构生成一个 mapping 文件,然后 D2RQ 会根据这个 mapping 文件将 SPARQL 语句翻译成 SQL 语句,然后进行查询。这里隐藏着一个 D2RQ 很重要的一个功能:将关系型数据库的数据转化成 RDF 数据。这也是我们常用来批量生成 RDF 数据的方式。关于这个功能不是我们要介绍的,想了解更多可以去 D2RQ 的官网进行了解。
我们通过 D2RQ 中的 D2RQ server 功能来进行 SPARQL 查询。D2RQ server 架构图如下:

进入 D2RQ 目录,使用下面的命令启动 D2R Server:
1 | d2r-server.bat mapping.ttl # windows |
其中 “mapping.ttl” 就是我们上面说的 mapping 文件。
这里多说两句:
以 mysql 关系型数据库为例。生成 mapping.ttl 的方式如下:
1 | generate-mapping -u root -o mapping.ttl jdbc:mysql:///demo |
generate-mapping是转换命令-u root表示关系型数据库的用户名-o mapping.ttl表示输出 mapping 文件名,可自定义jdbc:mysql:///demo关系型数据库生成 mapping 文件之后,根据我们用 protege 知识建模的时候生成的
.owl文件对 mapping文件进行修改,得到我们最终要用的 mapping 文件。更多关于 mapping 的语法参看:The D2RQ Mapping Language。
此时,D2RQ 服务就启动的。我们有两种方式进行 RDF 查询:
- 浏览器中查询
- 命令行查询
- Python 脚本查询
4.2.1.1 浏览器查询
在浏览器中输入 “http://localhost:2020/ ”,可以看到如下页面:
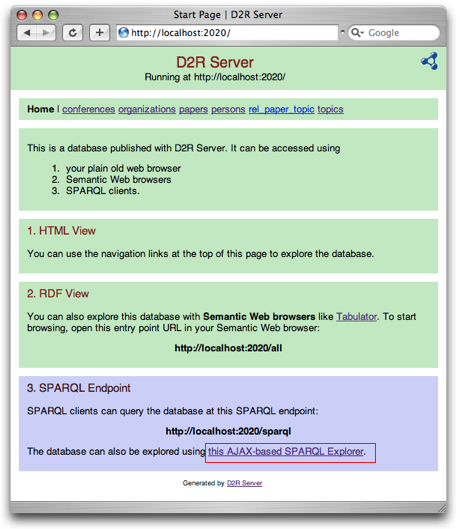
点击页面右下角红框地方的链接,进入 endpoint。然后就可以进行查询了,如下图:
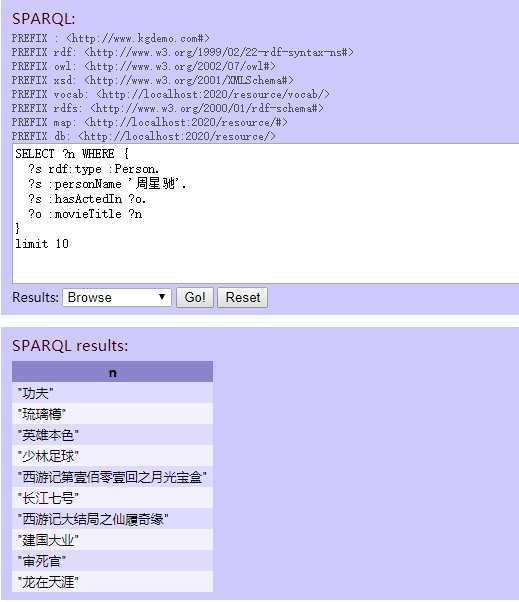
4.2.1.2 命令行查询
使用 d2rq-query 工具进行命令行查询:
1 | d2r-query mapping.ttl "SELECT * { ?s ?p ?o } LIMIT 10" |
或者加载一个查询文件,比如 query.sparql:
1 | d2r-query mapping.ttl @query.sparql |
4.2.1.3 Python 脚本查询
通常情况下,我们对 RDF 的查询是集成在代码中的。为了能在代码中进行查询,人们就开发了一个 python 库—— SPARQLWrapper。这是一个Python下的包装器,可以让我们十分方便地和endpoint进行交互。下面是通过SPARQLWrapper,向 D2RQ endpoint发送查询“巩俐参演的评分大于 7 的电影有哪些”,得到结果的代码:
1 | from SPARQLWrapper import SPARQLWrapper, JSON |
运行结果:
1 | 2046 |
4.2.2 Apache jena SPARQL endpoint
Apache jena 严格来说是语义网框架,包括存储、查询和推理组件,架构图如下:
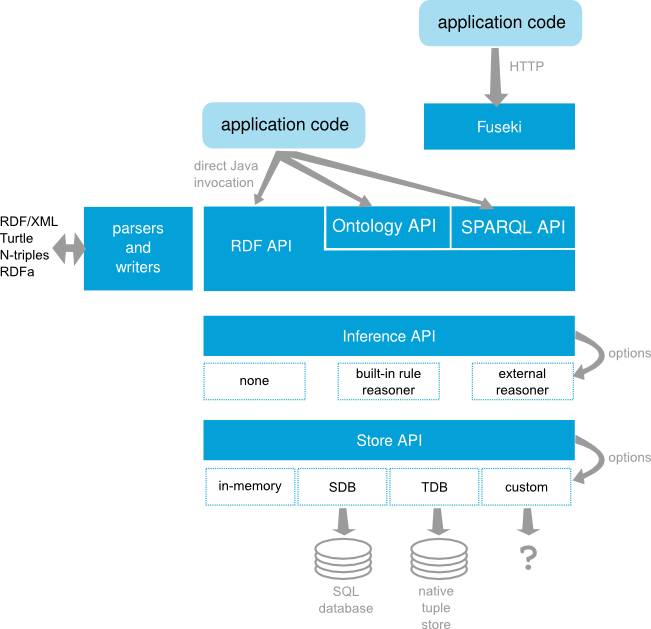
我们可以将 .ttl 数据存储到 jena 数据库中,然后通过 Fuseki 查询组件进行查询。操作流程同样是可以在浏览器端和命令行和通过调用 api 在代码里进行操作。这里我们不再详细介绍,在接下来的知识存储相关文章中进行详细介绍。
4.2.3 RDFLib
RDFLib 是一个 python 包:
1 | import rdflib |
4.2.4 Wikidata Query Service
如果你想快速体验 SPARQL 的话,wikidata 提供了一个服务——Wikidata Query Service:
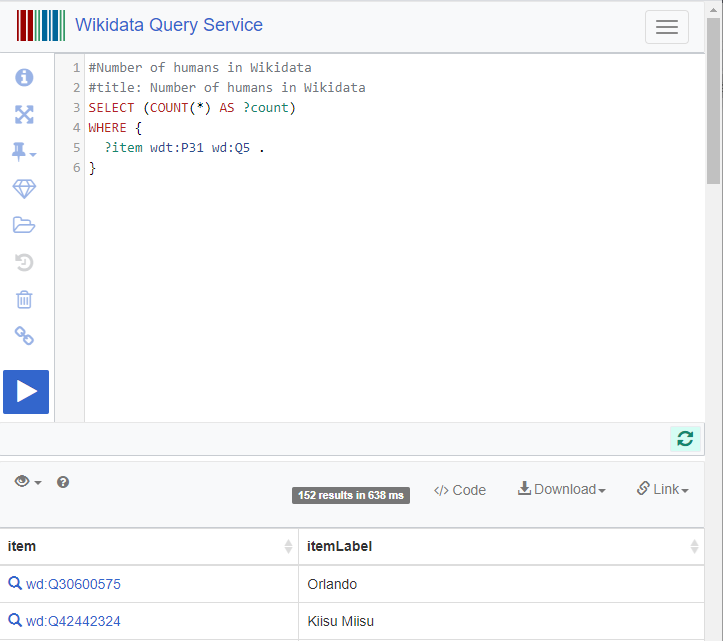
4.3 更多 SPARQL 语法
接下来,我们再介绍一些比较常用的 SPARQL 语法。
4.3.1 DISTINCT
用于数据去重。
数据:
1 | @prefix foaf: <http://xmlns.com/foaf/0.1/> . |
Query:
1 | PREFIX foaf: <http://xmlns.com/foaf/0.1/> |
返回结果:
1 | "Alice" |
4.3.2 OPTIONAL
通常的 query 语句只会返回匹配到的数据,OPTIONAL 可以返回一些匹配到的数据包含的额外信息:
数据:
1 | @prefix foaf: <http://xmlns.com/foaf/0.1/> . |
Query:
1 | PREFIX foaf: <http://xmlns.com/foaf/0.1/> |
返回结果:
1 | "Alice" <mailto:alice@example.com> |
4.3.3 UNION
求并集。
数据:
1 | @prefix dc10: <http://purl.org/dc/elements/1.0/> . |
Query:
1 | PREFIX dc10: <http://purl.org/dc/elements/1.0/> |
返回结果:
1 | "SPARQL Protocol Tutorial" |
4.3.4 FILTER
过滤器。
数据:
1 | @prefix dc: <http://purl.org/dc/elements/1.1/> . |
Query:
1 | PREFIX dc: <http://purl.org/dc/elements/1.1/> |
返回结果:
1 | "SPARQL Tutorial" |
4.3.5 ORDER BY
排序。
数据:
1 | @prefix dc: <http://purl.org/dc/elements/1.1/> . |
Query:
1 | PREFIX dc: <http://purl.org/dc/elements/1.1/> |
返回结果:
1 | "A data engineer's guide to semantic models" |
4.3.6 LIMIT
数据:
1 | @prefix dc: <http://purl.org/dc/elements/1.1/> . |
Query:
1 | PREFIX dc: <http://purl.org/dc/elements/1.1/> |
返回结果:
1 | "A data engineer's guide to semantic models" |
更详细的 SPARQL 语法可参考之前提到的资源。
5. 结语
到这里,我们的知识建模简介就结束了。但是对于我们来说,它才刚刚开始。学习这个理论是一个很好的开始,但最好的学习方法是将理论付诸实践。注意建议:当您决定构建一个模型时,尝试与一个团队一起构建模型。由于建模是如此的主观,所以把一群不同的思想家聚集在一起总是一个好主意。语义建模并不一定需要以语义模型开始和结束。
不管怎样,无论你可能读了多少。我希望我能让你对知识建模领域更了解一点,最重要的是,我希望你能对链接数据感到最小兴奋。毕竟,我们不需要更多的数据,我们需要更多有意义的数据。
Reference
A DATA ENGINEER’S GUIDE TO SEMANTIC MODELLING, Ilaria Maresi, 2020
知识图谱基础之RDF,RDFS与OWL, SimmerChan
- 实践篇(三):D2RQ SPARQL endpoint与两种交互方式, SimmerChan
- 实践篇(四):Apache jena SPARQL endpoint及推理, SimmerChan