上下文的向量表示在许多 NLP 任务中都有至关重要的作用,比如词义消歧、命名实体识别、指代消解等等。以前的方法多是直接用离散上下文词向量组合,缺乏对上下文整体的优化表示方法。本文提出一种双向 LSTM 模型,有效学习句子上下文表征。
1. 简介
通常词向量能获得单个词的语义语法信息,在训练词向量的时候是通过优化与任务无关的目标函数。为了推理出一个具体的词,好的上下文向量表示也是必须的。比如:
我找不到【星期五】了。
其中【星期五】可能是个人,可能是一个宠物等等。我们必须借助“我找不到【】了”才能确定“星期五”并不是一个表示日期的词。
通常上下文的表示有两种方式:
- 无监督。使用上下文的词向量组成一个序列输入到模型,或者直接使用上下文词向量相加求平均。这种方式缺乏对上下文整体表征的优化。
- 监督学习。通过标注数据根据具体的任务训练上下文表征。这种方式有两个缺点:① 依赖标注数据,通常标注数据是很难得的;② 训练出来的上下文表征依赖具体的任务,很可能并没有学习到目标词与上下文的依赖关系。
context2vec 通过在大规模的无标注数据上训练神经网络模型,直接对整个上下文和目标词进行编码,能够获得他们的依赖关系。将训练好的模型应用于下游的任务也获得了很好的表现。
2. Context2vec 模型
 |
 |
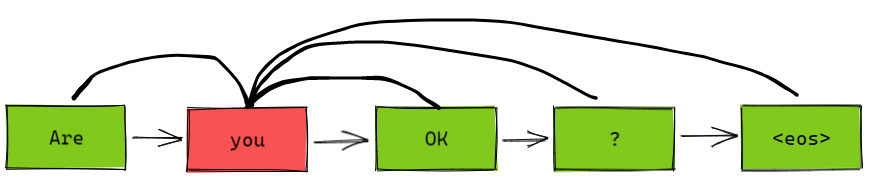
Context2vec 的主要目标是学习一个通用的与任务无关嵌入模型,用来表示目标词上下文的变长序列向量表示。我们借鉴了 word2vec 的 CBOW 模型,利用上下文来预测目标词。与 CBOW 不同的是,我们将原来的上下文向量求平均操作替换成了双向 LSTM 模型,如上右图所示。
John [submitted] a paper
用双向 LSTM 作为特征抽取器;
一个 LSTM 输入句子序列是从左向右;另一个 LSTM 输入序列是从右向左;

将目标词左侧(“John”)的 left-to-right 特征与目标词右侧(“a paper”)的 right-to-left 特征拼接起来;

将拼接后的特征输入到 MLP 中,我们的目标是让 MLP 的输出等于 [submitted] 的向量。
采用 Word2vec 中的负采样方法训练神经网络参数,这样就能学到上下文向量和目标词向量。
3. 形式化分析
定义:lLS 表示 left-to-right LSTM,rLS 表示 right-to-left LSTM。给定句子 $w_{1:n}$ 和目标词 $w_i$,那么双向 LSTM 的输出为:
其中 $l$ 和 $r$ 分别表示句子中从左到右和从右到左的词向量。注意在本模型中句子的第 $0$ 个位置和第 $n+1$ 个位置分别表示 $\text{BOS}$ 和 $\text{EOS}$。我们并没有将目标词传入到 LSTM 中去。接下来:
其中 $\text{ReLU}$ 表示激活函数,$L_i$ 表示线性变换。令 $c=(w_1, …, w_{i-1}, w_{i+1}, …, w_n)$ 表示句子的上下文词向量。
令目标词 $w_i$ 的词向量为 $\vec{t}$:
其中 $\sum_{c,t}$ 表示对训练语料中的每个 $(t,c)$ 对求和,$t_1, …, t_k$ 表示负采样的样本。负采样的概率分布为:
$0\le\alpha\le1$ 表示一个平滑系数,$\alpha$ 越大越容易采样到罕见词。$#$ 表示统计个数。
Levy & Goldberg (2014) 证明了将上式用于单字上下文时是可以优化的,当
其中 $\text{PMI}(t,c)=\log\frac{p(t,c)}{p_\alpha(t)p(c)}$ 表示目标词 $t$ 与 上下文 $c$ 的点互信息。 Levy & Goldberg (2014) 的分析适用于两个随机变量的共现矩阵。在我们这里,上下文不是单字而是一个目标词的完整句子表达。据此,我们可以将模型得到的上下文向量视作所有可能的目标词与可能句子上下文的 $\text{PMI}$ 的矩阵分解。
最终我们注意到 $\alpha$ 越大,则目标词越偏向罕见词。
4. 模型验证
为了验证模型的质量,我们提出三种相似度矩阵:
- target-to-context
- context-to-context
- target-to-target
所有的相似度都用 $\cos(\cdot)$ 计算。
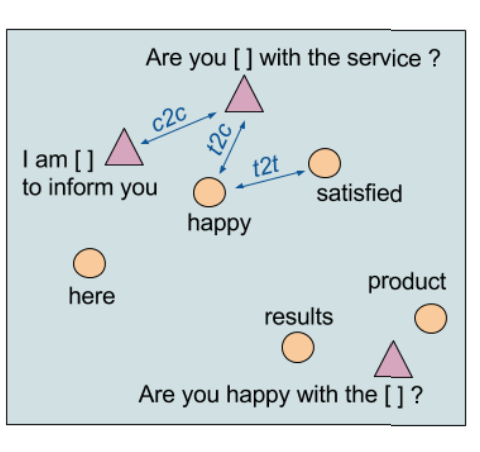
4.1 target-to-context
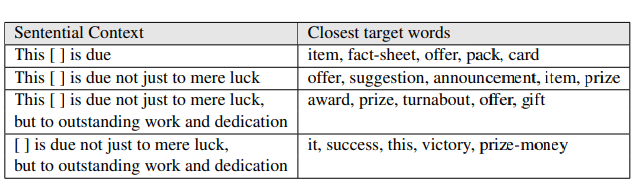
当 $\alpha$ 取不同的值的时候,目标词的结果:

4.2 context-to-context

4.3 target-to-target
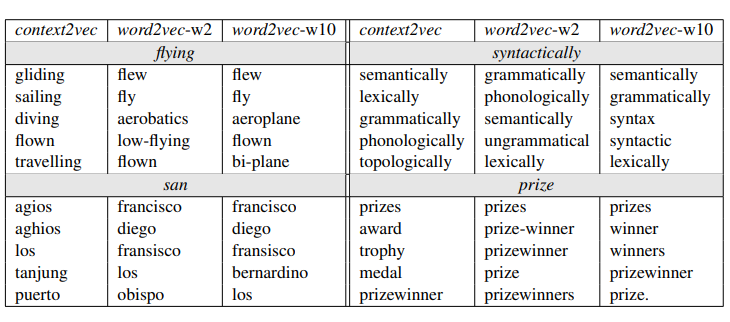
5. 与语言模型的关系
从我们对模型的介绍,以及 target-to-context 实验结果的分析可以看出,我们的模型和基于 LSTM 的语言模型很像。主要的区别在于 LSTM 语言模型给定目标词,优化模型的联合概率。然而 context2vec 的目标是学习通用的向量表示。我们采用了 Word2vec 的学习框架,但是我们利用 $\vec{t}\cdot\vec{v}$ 近似点互信息,而不是 $\log p(t|c)$。
Reference
- context2vec: Learning Generic Context Embedding with Bidirectional LSTM, Oren Melamud, Jacob Goldberger, Ido Dagan. 2016
- Neural Word Embedding as Implicit Matrix Factorization, Omer Levy, Yoav Goldberg. 2014