本文继续介绍关于transformer在non-auto regression方面的研究,今天要介绍的是Gu et al. 2018 发表在ICLR 2018上的文章Non-autoregressive neural machine translation 。
1. 简介
之前我们介绍了由于transformer的auto-regression机制,导致模型在做推理的时候会变得非常慢。针对这个问题很多研究者都做了探索,之前介绍的几篇论文都没有真正做到non-auto regression,而今天我们要介绍的这篇文章则从根本上做到了non-auto regression。
1.1 Auto-Regressive Decoding
给定一个源序列$X=\{x_1, x_2, …, x_{T’}\}$,翻译模型通过链式条件概率的方式预测输出序列$Y = \{ y_1, y_2, …, y_T\}$:
其中$y_0$表示句子开始符,比如$BOS$;$y_{T+1}$表示句子结束符,比如$EOS$ 。
1.2 Maximum Likelihood training
训练的时候直接使用Maximum Likelihood training方法对模型进行训练:
1.3 Non-Auto regressive Decoding
从上面的$p_{AR}(Y|X;\theta)$中可以看出,实际上要预测$Y=\{y_t\}$需要两个条件:
- 知道$Y$的长度$T$,虽然对于auto-regression来说,解码过程并不知道$T$显示的值,但是由于编码的开始和结束可以通过句子开始符($< BOS>$)和句子结束符($< EOS>$)来控制,编码过程是一个词一个词的生成 ,知道遇到结束符,则编码过程结束。因此,模型可以隐式的知道$T$的值。但是对于并行生成句子序列,我们必须提前知道句子的长度,才能一次性生成一个长度为$T$的序列,所以对于Non-auto reregression来说$T$必须是显式的;
- 第二点当然就是$Y$序列本身了,当知道了需要预测的序列长度,就可以根据输入预测输出了。
因此,我们可以把预测$Y=\{y_t\}$任务分为两部分,第一部分预测$T$的大小,第二部分生成长度为$T$的序列:
这样我们就可以分别独立的训练这两部分,而在推理的时候 能并行计算。
1.4 多模态问题
这种简单的方法虽然看起来合理,但是实际上有一个很大的问题:多模态问题 。具体来说就是同一句话有多种翻译方式,比如Thank you可以翻译成谢谢、感谢等。由于$p(y_t)$只与$X$有关,所以无法获得训练数据中谢谢、感谢 等不同翻译方式的分布。
当A B既可以翻译成1 2 3,又可以翻译成4 5 6时,实际上相当于
的一个映射,而最佳的映射组合是$\{1,2,3\}$和$\{4,5,6\}$,但是由于non-auto regression每个词都是独立的,所以无法获取到词与词之间的依赖关系,每种序列组合称为mode。
另外使用Maxium Likelihood进行训练的时候,模型倾向于使用在训练集中出现概率最大的mode覆盖掉其他小概率mode,这实际上是有一定问题的。
要解决多模态问题,一般有三种方法:
- 增强模型处理多模态的能力;
- 在训练集中减少mode的数量;
- 改变学习目标
实际上最有效的还是第一种方法,这篇论文提出了一种训练技术用来解决多模态问题。
2. Non-Autoregressive Transformer
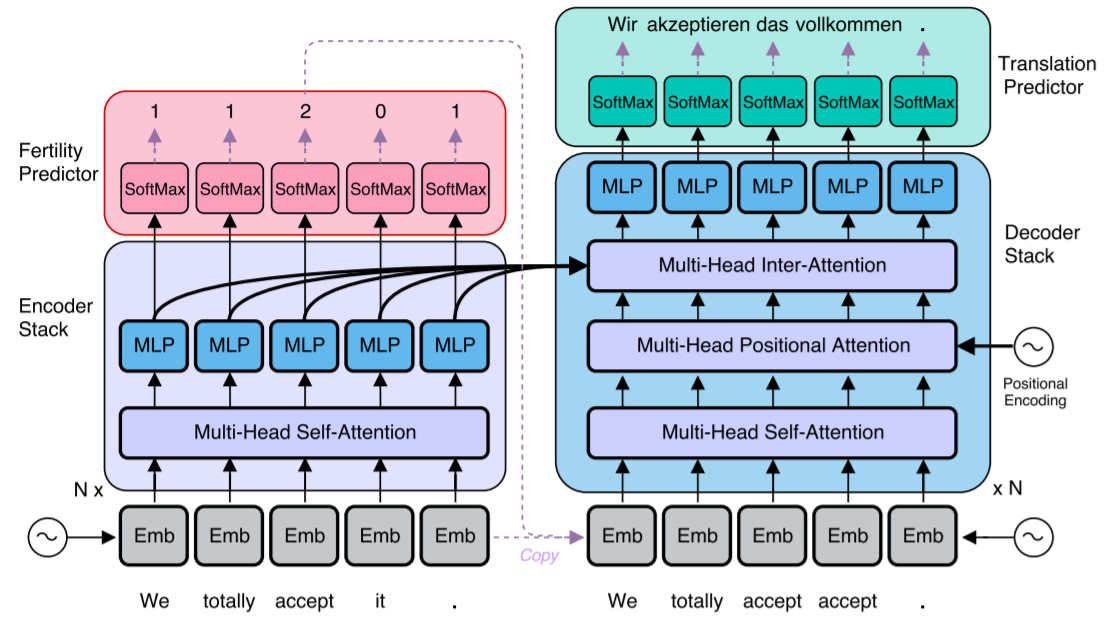
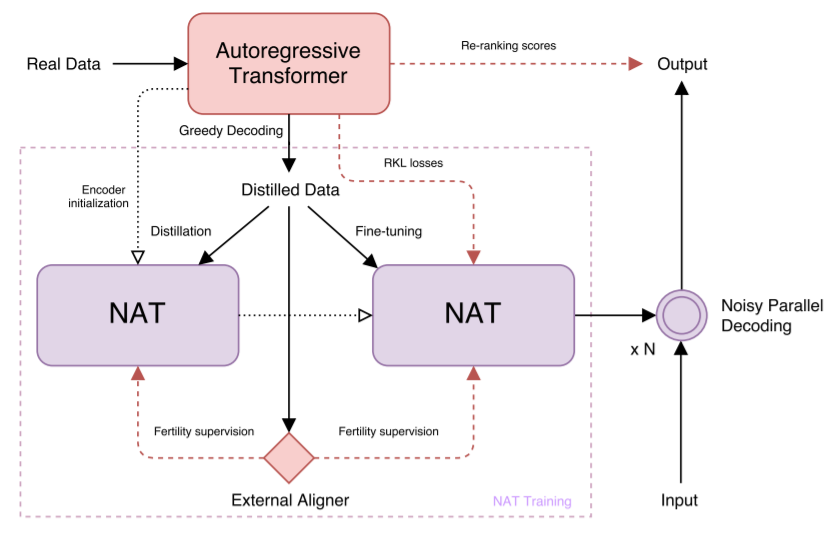
模型结构图如上。模型包含四个部分:Encoder、Fertility predictor、Decoder和Translation Predictor。其中黑色实线箭头表示可微分操作,浅色虚线表示不可微分操作,每个sublayer也都包含LayerNorm和残差连接。
Encoder部分作者并没有做什么变化,与Transformer保持一致,因此这里我们不做介绍,主要介绍其他几部分,以及训练技巧。
2.1 Decoder Stack
从图中可以看到,Decoder Stack包含了四部分:
- Multi-Head Self-Attention
- Multi-Head Positional Attention
- Multi-Head Inter-Attention
- MLP
其中MLP就是transformer中的position wise feed forward层。Multi-Head Inter-Attention就是transformer中decoder block的第二个multi-head attention层。这两个相比原来的transformer没有什么变化,这里就跳过不讲。下面主要介绍其余两个模块以及Decoder Stack的输入。
2.1.1 Decoder Inputs
在进行解码之前,Non-Autoregressive Transformer(NAT)需要知道要生成的序列的长度。另一方面如果只输入位置编码的话最后的效果会很差,因此解码器的输入也是非常重要的。为此,作者设计了两种解码器的输入:
- Copy source inputs uniformly:根据下面的规则从源序列中拷贝一个序列出来作为解码器的输入
假设源序列长度是$T’$,目标序列长度是$T$,那么解码器的输入序列中第$t$个位置的元素为源序列中第$Round(T’t/T)$个元素。举个例子:
源序列:[Thank, you, !]
目标序列:[谢谢, !]
源序列的长度是3,目标序列的长度是2。那么解码器的输入第0个位置的元素应该对应源序列中第 $3 \times 0/2=0$,个元素,即Thank;解码器的输入序列的第1个元素,应该对应源序列中第$3 \times 1/2=1.5$,四舍五入得2,即!。那么解码器的输入序列应该为$\{Thank , !\}$。
- Copy source inputs using fertilities:同样是从源序列中拷贝一个序列出来作为解码器的输入,但是拷贝规则有了变化。如同结构图中显示的,编码器会在编码结束后除了输出注意力状态,还会输出一个长度与源序列长度相同的序列,序列中每个元素都是一个整数。将源序列中的每个位置上的元素拷贝相应的整数倍之后作为解码器的输入,而解码器的输入长度$T$则是编码器输出的整数序列之和。举个例子:
源序列:[Thank, you, !]
encoder output: [1, 0, 1]
那么解码器的输入序列为: $\{Thank \times 1, you \times 0, ! \times 1 \}$,即$\{Thank, !\}$为解码器的输入。
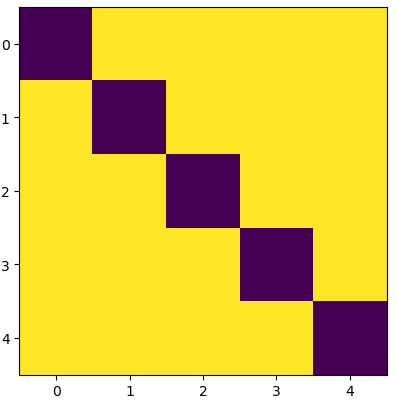
2.1.2 Non-causal self-attention
由于这里是并行生成目标序列,因此不需要对注意力权重矩阵进行mask。但是在实际的测试过程中作者发现把元素自身所在的位置mask掉后会取得更好的结果,即(深色部分表示被mask掉的):
2.1.3 Positional Attention
作者还在每个decoder layer中加入了positional attention,使得模型获得序列位置向量的能力更强了。而所谓的positional attention顾名思义就是positional encoding + attention,分别对应transformer中的positional encoding和multi-head attention:
2.2 Modeling Fertility 解决多模态问题
本文提出使用隐变量(Latent Variable)方法来解决这一问题。具体的想法如下图
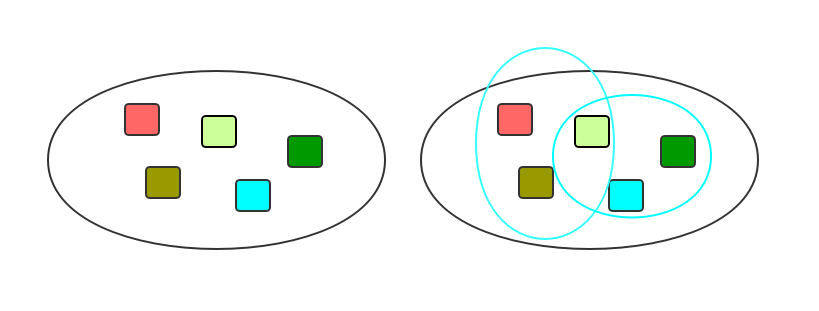
左边代表可能的各种可能的组合元素,所有元素可以两两组合,也可以三三组合等等可以以任意方式组合,因为对于NA来说词与词之间存在一个独立假设。我们可以从大的组合集中进行采样得到小的组合集(如图中蓝色圈圈画出来的小样本集合),这样模型就相当于在一个小的样本空间中进行建模,这样就可以强化模型的多模态处理能力。而我们把采样得到的样本空间称之为隐变量$z$,引入$z$后多模态的翻译分布则变成了:
$z$需要满足以下条件:
- 需要比较简单的从端到端的训练中获得;
- $z$要尽可能的考虑到不同说出之间的关系,使得其余位置的输出尽可能条件独立性;
- $z$要很容易从平行语料中推理得到,又不能信息量过于丰富让$p$显得无关紧要。
所以,模型的关键是对$z$建模。本文中$z$就是decoder的输入——利用Fertility的思想从encoder输入中拷贝元素。所谓fertility指的是,源序列中每个元素会被翻译多少次。这种思想源于早期的统计机器翻译中,每个词被翻译的次数不同,则输出序列会不,比如Thank被翻译一次可能是谢谢,而如果翻译两次的话可能会输出多谢。每个词的翻译次数实际上是个隐藏的含义,并不具有显式意义,因此它是一种Latent Variable,可以用来表示一种translation mode。
因此根据fertitlity我们可以把方程写成:
其中$F=\{f_1, …, f_{T’} | \sum_{t’=1}^{T’}f_{t’}=T, f_{t’}\in \mathbb{Z^*}\}$。
Fertility序列中每个词重复的次数通过一个softmax层预测。
3. 训练
由于模型中引入了离散的隐变量,是的整个模型不能直接使用后向传播进行训练。作者引入了一个外部的对齐函数——Fast-align。Fast-align能够将输入输出进行词对齐,即目标序列中的每个词对应源序列中的相应的词。这样我们就可以得到一个外部的Fertility序列。我们可以用这个外部的fertility序列当成fertility的监督项,这样整个模型的损失项来源于两部分:decoding和fertility:
其中$q$表示外部对齐函数估计的Fertility序列分布。
这样的话整个模型就相当于由两部分监督学习组成,就可以直接使用后向传播进行训练了。
3.1 知识蒸馏
之前我们提到解决多模态问题有三种方法:增强模型处理多模态的能力,减少mode数,改变学习目标。其中增强模型处理多模态的能力是核心,前面我们已经介绍过了。下面我们介绍一下后两种方法,注意这几种方法结合使用,而不是分别使用,也就是说是在同一个模型中一起使用者三种方法,fertility是核心。
知识蒸馏其实蒸馏的就是mode,通过减少mode数,从而提升模型的学习效果。这里使用的方法是先用一个标准的Transformer学习一个模型,将这个标准Transformer的推理结果作为NAT的目标序列。
3.2 Fune Tuning
前面我们提到使用Maximum Likelihood本身更倾向于学习概率更大的mode,因此作者在这里引入一个微调项,用来做目标纠正——reverse K-L divergence:
其中$\hat{y}_{1:T}=G(x_{1:T’}, f_{1:T’};\theta)$,所以最终的损失函数为:
4. 推理
推理阶段主要的任务是获取fertility序列,作者提出三种方法:
- Argmax decoding
由于在模型训练阶段,fertility序列随着模型的训练一起呗训练了 ,因此我们可以直接使用$\mathrm{arg~max}$来得到fertility序列:
- Average decoding
也可以通过求对应的softmax的期望来得到fertility序列:
- Noisy parallel decoding (NPD)
最后使用一个之前在做知识蒸馏的时候训练好的Transformer对输出的句子进行re-ranking,得到一个最佳的翻译结果:
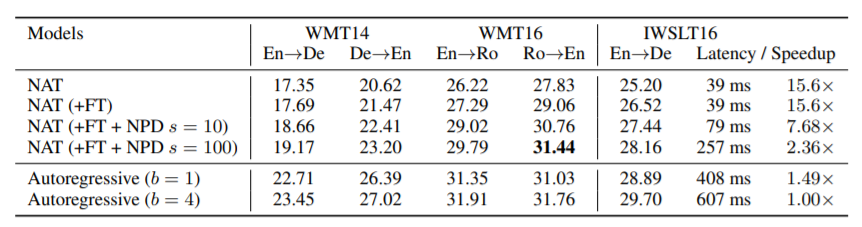
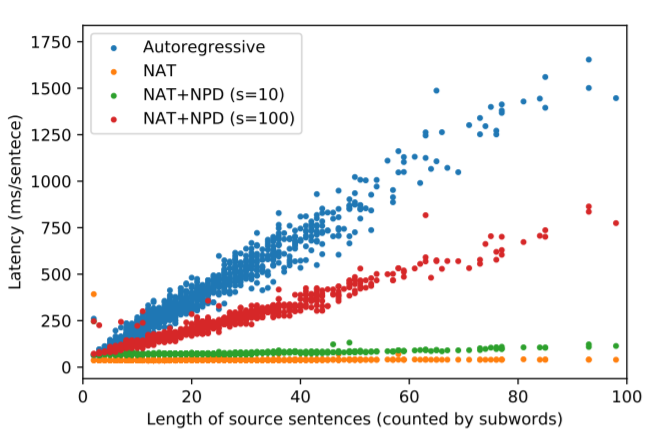
5. 实验结果