
任何知识图谱的基础是首先将图应用于数据,从而产生初始数据图。我们现在讨论一些在实践中常用来表示数据图的图结构数据模型。 然后,我们讨论构成用于查询此类数据图的图查询语言基础的查询语言。
2. Data Graphs
2.1 Models
抛开图数据不谈,假设现在旅游局还没有确定怎样对数据建模。他们首先会考虑的是关系型数据库来展示所需的数据,尽管还不知道具体需要获取什么数据,但是他们可以设计一个初始的数据模式(schema),比如活动表:
其中 name 和 start 一起作为主键。当他们开始往表格填充数据的时候会遇到各种各样的问题:
- 活动可能有多个名字(多语言);
- 活动可能在多个场地举办;
- 活动举办的起始和结束时间未定;
- 活动可能包含多种类型等等。
随着数据变得更加多样化,他们需要增量式的解决建模问题,比如给活动添加 id,调整关系模式:
通过上面这种模式,旅游局可以给活动 0-n 个名字、场所和类型以及 0-1 个起始和结束时间(不需要在表格中用 null 或者空值表示)。这种方法要求旅游局不断的重新建模,重新加载数据,重建索引以适应新的数据源。
如果一开始就采用下面这种数据建模方式,我们会发现当有新的数据需要建模的时候,只需要很小的改动就可以实现多关系映射。我们仔细观察上面这种模式,实际上就可以认为是一种图数据结构:id 和 name 是实体,EventName 是关系,下面类似。
下面我们介绍三种常见的图数据模型。
2.1.1 Directed edge-labelled graphs
有向边标记图(DELG)是一系列节点和连接节点的带标记的有向边组成的图,如下图所示。
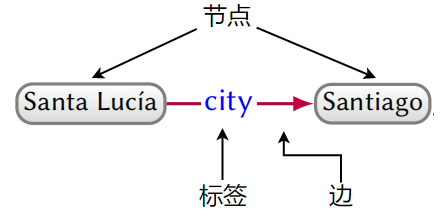
在知识图谱中,节点用来表示实体,边用来表示实体之间的关系。
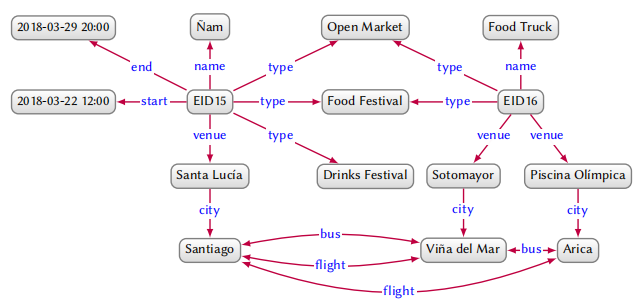
上图是关于 Events 的图数据信息,包含了两个 event:EID5 和 EID6,并分别展示了两个活动的 name,type,venue,start 和 end。如果我们想要添加信息,只需要添加节点和边;对于不完整的信息,只需要忽略特定节点和边即可,比如 EID6 并没有 start 和 end 信息。
用图对数据进行建模可以使集成新数据源更加流畅,不需要像关系型数据库那样需要提前设计对数据模式,一旦新数据结构不符合之前设计的数据模式又要重新建表。虽然其他的数据结构也可以方便添加新数据,比如树,但是树需要一个层级结构,而且图支持循环表示,如上图中的 Santiago, Arica 和 Viña del Mar 三个节点。
W3C 制定了一个标准的有向边标记图——RDF(Resource Description Framework)。RDF 定义了不同的节点类型,包括:
- IRIs:国际化资源标识符(Internationalized Resource Identifiers),允许对 Web 上的实体进行全局识别。
- literals:字面量,允许表示字符串和其他数据类型,比如整数,日期等。
- blank nodes:表示未分配标识符的匿名节点。
2.1.2 Graph dataset
尽管我们可以通过对多个图取并集的方式将多图合并,但是通常管理多个图更符合实际需求,比如更新和细化单一来源的数据;区分可信数据和不可信数据等。一个图数据集由一系列命名图和一个默认图组成,每个命名图包括图本身和其对应的 ID,默认图不需要 ID。
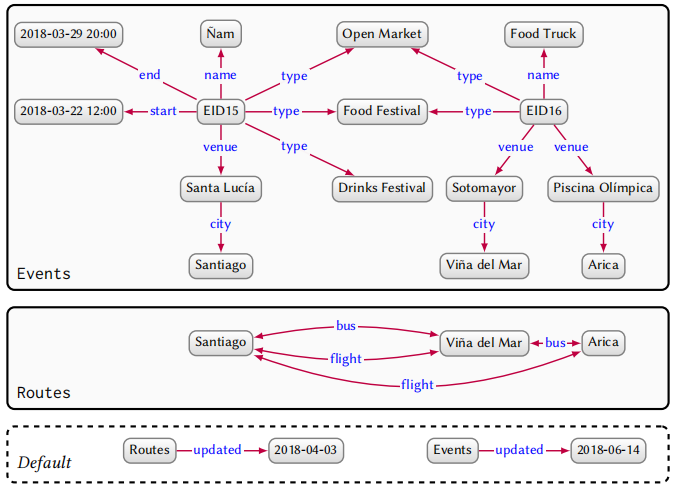
上图给出一个例子,Events 和 Routes 表示两个命名图,默认图用来管理命名图中的元数据。需要指出的是命名图的名字可以作为图的节点,节点和边是可重复的,即不同图中的节点表示同一个实体,在进行图合并的时候可以利用这些节点。
2.1.3 Property graphs
当我们对更加复杂的关系进行建模的时候可以引入属性图。比如如果我们的数据中包含了哪些公司提供了哪些航班的票价信息,可以使我们更好的了解城市之间的交通信息。这种情况下,我们就不能直接用:

而是需要添加新的航班节点,如下所示:
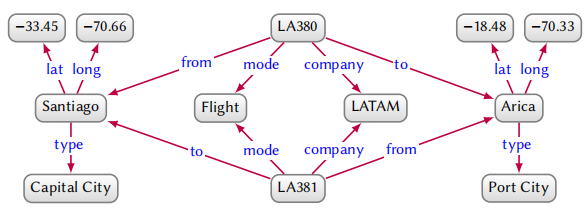
但是这样的话,我们就需要对原始的图进行大改。另一种方法就是将不同公司的航班信息用命名图的方式表示出来,但是如果命名图已经被用作他途,这种方式也会变得很麻烦。
属性图简单来说就是,节点和边都可以带标签,如下图所示:
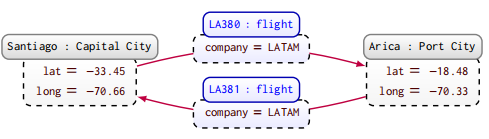
属性图在常见的图数据库中是最常用的,比如 Neo4j。属性图可以在没有任何信息损失的情况下与有向边标记图和图数据集相互转化。
- 有向边标记图是更小巧的图数据模型;
- 属性图是更加灵活的图数据模型。
2.1.4 Other graph data models
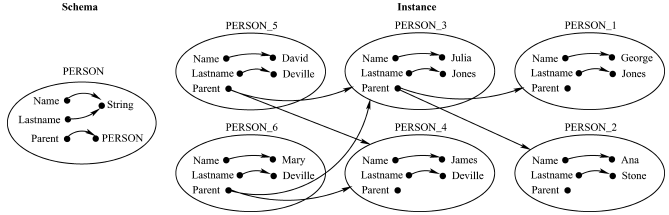
前面我们介绍了最常见的三种图数据模型,还有一些更加复杂的模型,比如有些复杂节点包含孤立边或者嵌套图等。还有一些复杂边连接的是一个集合而不是节点对。在我们看来,知识图谱可以应用任意的图数据模型:通常情况下数据可以从一个模型转化为另一个模型,比如上面两图所示的例子。
近些年来,最流行的图数据模型就是前面介绍的三种模型,后面我们会详细介绍。
2.2 Querying
就像关系型数据库需要 SQL 语言对数据进行检索一样,图数据同样需要检索语言。目前的图数据语言有很多,比如 SPAEQL 用于检索 RDF 数据,Cypher、Gremlin、G-CORE 等语言用于检索属性图。虽然不同语言的具体语法不尽相同,但是却存在一些共通性,包括(基本的)图模式(graph patterns)、关系运算符(relational operators)、路径表达式(path expressions)等等。
2.2.1 graph patterns
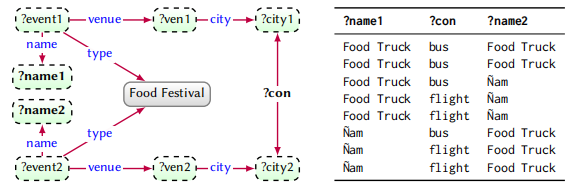
每一种图数据的结构化查询语言核心都是图模式,它遵循与被查询的图数据相同的模型,另外还支持变量项。因此图数据模式中的术语分成两类:常量和变量。常量如 “Arica”,变量通常使用问号做前缀,比如 “?event”。

上图展示的是变量术语情况的例子。现在我们要查找 Food Festival 的举办地点,图模式通过将变量映射到图数据库中的常量,上图右侧展示可能的映射。
注意上图右表最后两行,同一个 event 对应两个相同的 venue,这种情况在有些应用中是可取的,但是有些情况确实不可取的。因此,为了评估图模式,人们提出一些语义标准,其中最重要的有两个:
- 基于同态的语义(homomorphism-based semantics),即不同的变量可以映射到相同的常量上。
- 基于同构的语义(isomorphism based semantics),即要求变量映射的节点或者边必须是唯一项。
不同的查询语言使用不同的语义标准,比如 SPARQL 基于同态语义,而 Cypher 在边上则基于同构语义。
2.2.2 Complex graph patterns
图模式是将输入的图转化成表格,如上面的例子所示。因此,我们可以考虑使用关系代数实现这种转化,这样可以形成更复杂的检索。
关系代数由一元操作符和二元操作符组成,一元操作符接收一个输入表,二元操作符接收两个输入表。
一元操作符包括:
- 映射($\pi$):输出表格的列;
- 筛选($\sigma$):根据匹配条件输出行;
- 重命名列($\rho$)。
二元操作符包括:
- 并集($\cup$):合并两个表的行成一个一个表;
- 差集($-$):从第一个表中移除出现在第二个表中的行;
- 合集($\Join$):将其他表中满足联合条件的行扩充到第一个表中;
筛选和合集条件基本包含:等于($=$)、小于等于($\le$)、非($\neg$)、析取($\lor$)等。
根据这些操作符,我们可以进一步定义一些操作符:
- 交集($\cap$):输出两张表;
- 反合集($\rhd$,即不存在):输出第一个表中不满足与第二个表的联合条件的行;
- 左联合($\lhd$,即可选):输出合集但是保持第一个表中与第二个表没有冲突的行。
假设 $G(s, p,o)$ 表示一个图,那么上图的检索可以用关系代数表示:
其中 $\text{conditipon}= [p=\text{type},o=\text{Food Festival},p1=p2=\text{venue}]$。
上图中,我们给出一个例子,其中加粗字体表示我们想要的最终结果,这个检索相当于连词查询。从右表中我们可以看到,前两行的结果是重复的,说明复杂图模式也会给出重复结果。针对这个问题,查询语言提供了两种语义:
- bag semantic:根据地层映射的多重性来保留副本;
- set semantic:移除结果中的重复项(DISTINCT)。

另一个例子,查找不在 Santiago 举办的 Food Festival 或者 Drinks Festival,若存在则返回它们的 name 和 start date。这条语句相当于一个一阶查询(first-order queries)。
2.2.3 Navigational graph patterns
区分不同图查询语言的一个关键特性是:在查询语句中包含路径表达式的能力。路径表达式就是两个节点之间任意长度的路径。$\text{query}(x,r,y)$,其中 $x,y$ 表示变量或者常量(甚至可以是相同的项),$r$ 表示路径。基础的路径表达式中 $r$ 是常量(边的标签),如果 $r$ 是一个表达式,那么 $r^-$(反转),$r^\star$(0-$\infty$)等等同样也是路径表达式。最后,如果 $r_1$ 和 $r_2$ 都是表达式,那么 $r_1 | r_2$ (析取) ,$r_1\cdot r_2$(拼接)也是路径表达式。

通常情况下,我们么可以直接在查询语句中使用路径表达式,比如(Arica, bus*, ?city)。但是由于图是可循环的,所以路径也有可能是循环的,这就会造成有无数种路径的可能性。所以,通常只会返回最短路径或者没有重复节点或边的路径。

上图的例子表示,从 Arica 出发通过 bus 或者 flight 能够到达的举办 food festival 的城市。
当查询语句中包含多个路径时,可以使用我们在关系代数中介绍的那些操作符。
2.2.4 Other features
到目前为止,我们介绍了一些查询语言的实践或者理论基础。但是在实际生产中,特定的查询语言还支持其他特性,比如聚合(GROUP BY, COUNT 等),更复杂的过滤器、数据类型操作符、远程查询、图数据更新、语义约束机制等等。
2.3 小结
- 图数据模型:有向边标记图、图数据集、属性图以及复杂图模型等;
- 图数据查询语言特性:图模式、复杂图模式、可导航图模式以及其他特性。