1. 简介
Mikolov 等人提出的 RNN 语言模型解决了前馈神经网络语言模型的语序问题。但是由于 RNN 神经网络本身存在着长程依赖问题,导致 RNN 语言模型很难学到距离较远的信息。
比如:“我的家乡是广东,广东有很多好吃的,我最喜欢的是海鲜,我们的方言是粤语…” 假设有这样一个句子,我们想通过前文去预测 “粤语” 这个词,显然它是和 “广东” 相关联的信息。但是我们会发现 “广东” 在句子中距离 “粤语” 很远。RNN 很难学到这样远距离的信息,关于为什么会出现这样的情况可以参考 Hochreiter & German (1991) 和 Bengio, et al. (1994) 两篇文章,简单来说就是因为 RNN 循环过程中时间步之间是连乘的关系,一旦出现较大或者较小的值,经过连乘就会发生梯度爆炸或者梯度消失的情况。出现这种情况以后模型就学不到什么东西了。
为了解决这个问题,Hochreiter & Schmidhuber (1997) 提出了长短期记忆网络(Long Short Term Memory networks,即所谓的 LSTM 网络)。使用 LSTM 来构建语言模型可以避免由 RNN 带来的长程依赖问题。
2. LSTM 语言模型
2.1 LSTM 神经网络简介
长短期记忆网络(Long Short Term Memory networks),通常简称为“LSTM”,是一种特殊的RNN,它能够规避掉长期依赖学习问题。它是由 Hochreiter & Schmidhuber (1997) 提出的,并且经过很多人的改进。
LSTM被设计出来用以解决长期依赖问题。长时间记住信息实际上是他们的默认行为,而不是他们努力学习的东西!(Remembering information for long periods of time is practically their default behavior, not something they struggle to learn!)
所有的循环神经网络都有着重复模块的链式神经网络结构。标准的RNN的重复模块有非常简单的结构,比如单个 tanh 层。LSTM 也有这种类似的链式结构,但是重复模块却有着不同的结构,不同于单一网络层结构,LSTM 的基本结构如下图。
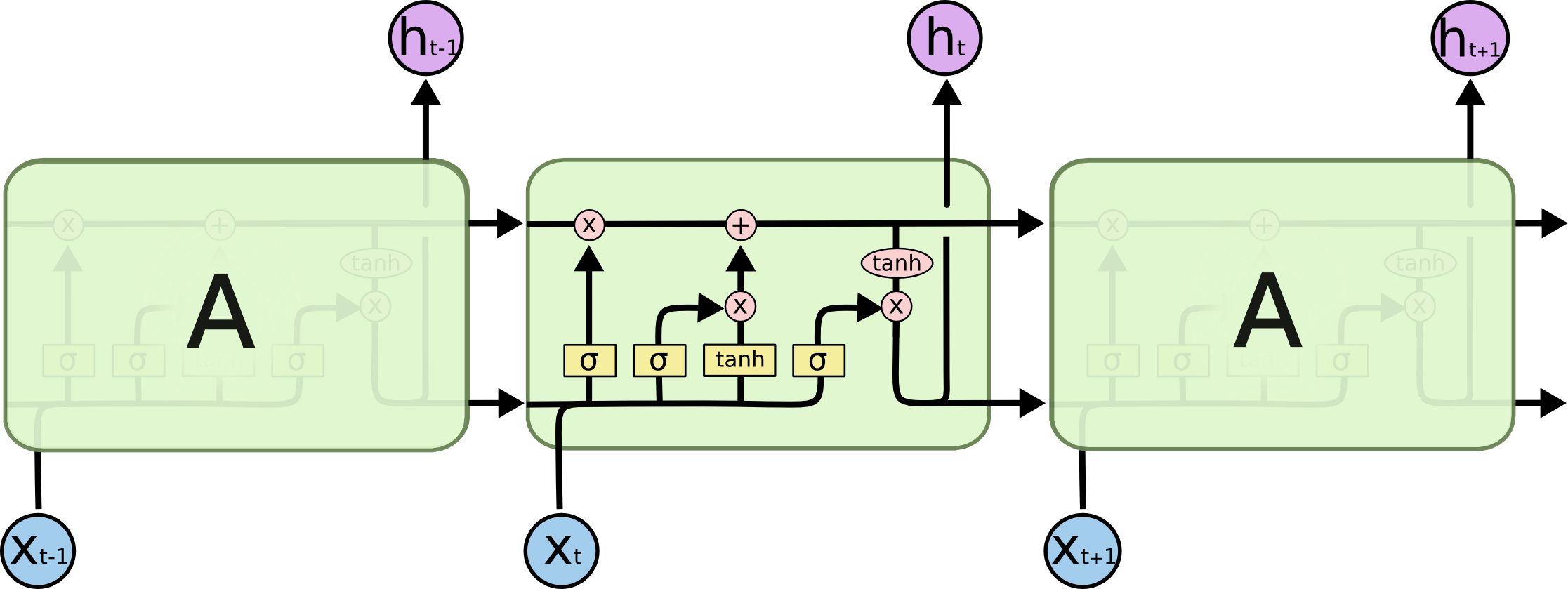
对比 RNN 的结构,我们会发现,LSTM 要复杂得多。简单来说,LSTM 通过三个门控来调节当前神经元中学习到的信息,避免梯度消失或者爆炸。
图中 $\sigma$ 表示 sigmoid 函数:
$\tanh$ 表示 tanh 函数:
cell 状态:LSTM 最重要的就是 cell 状态 $\vec{C}_t$,表示当前时间神经网络学习到的信息;
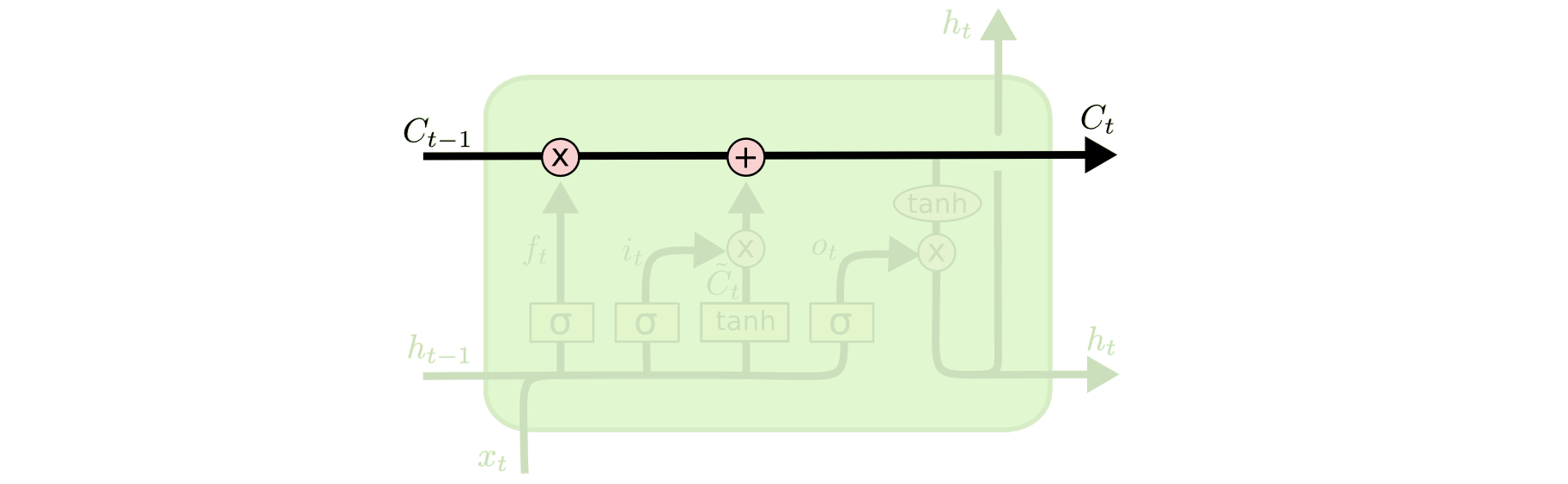
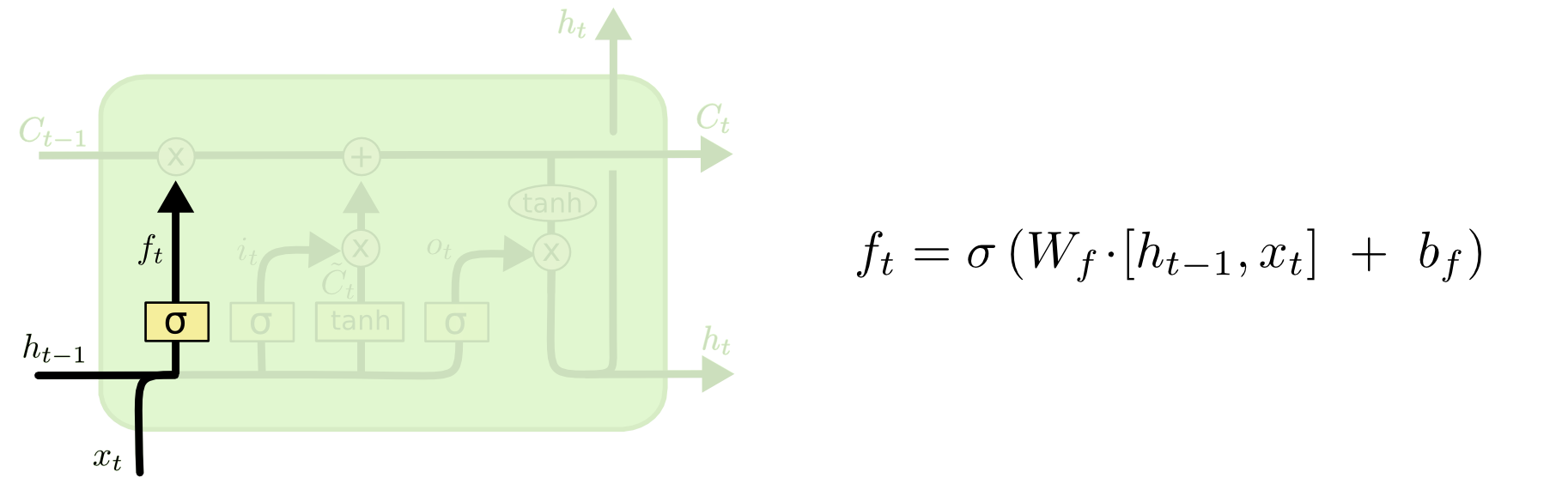
遗忘门:控制上一个 cell 中有多少信息会进入到当前的 cell;
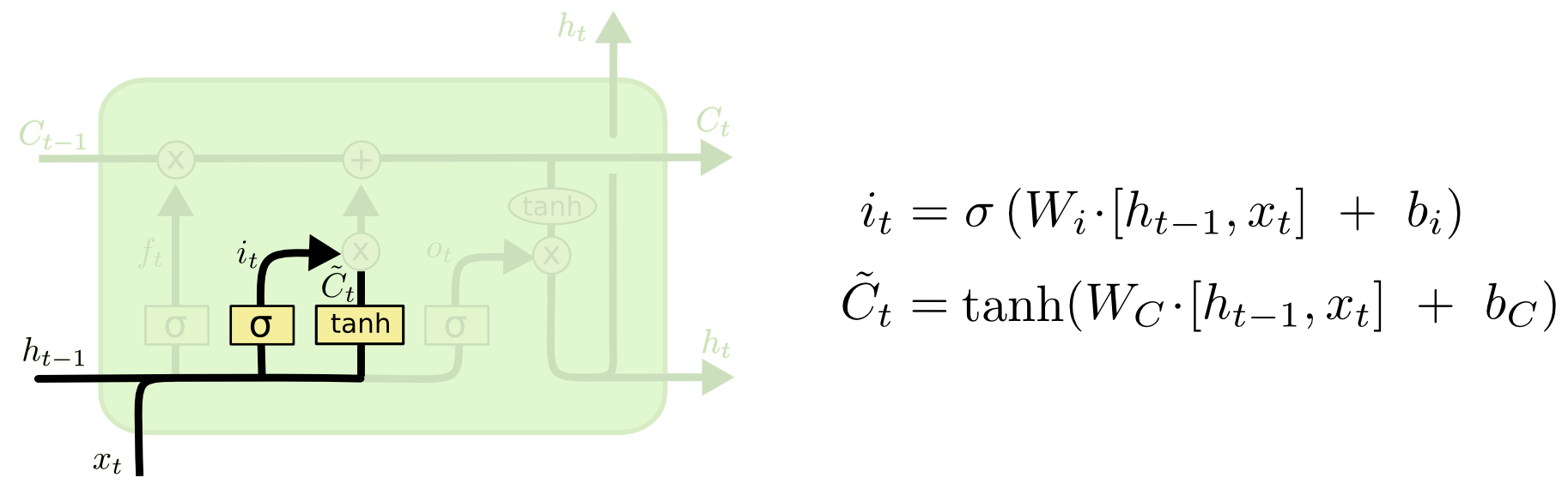
输入门:控制输入层有多少信息会进入到当前 cell 中;
输出门:控制当前 cell 有多少信息可以用于输出。
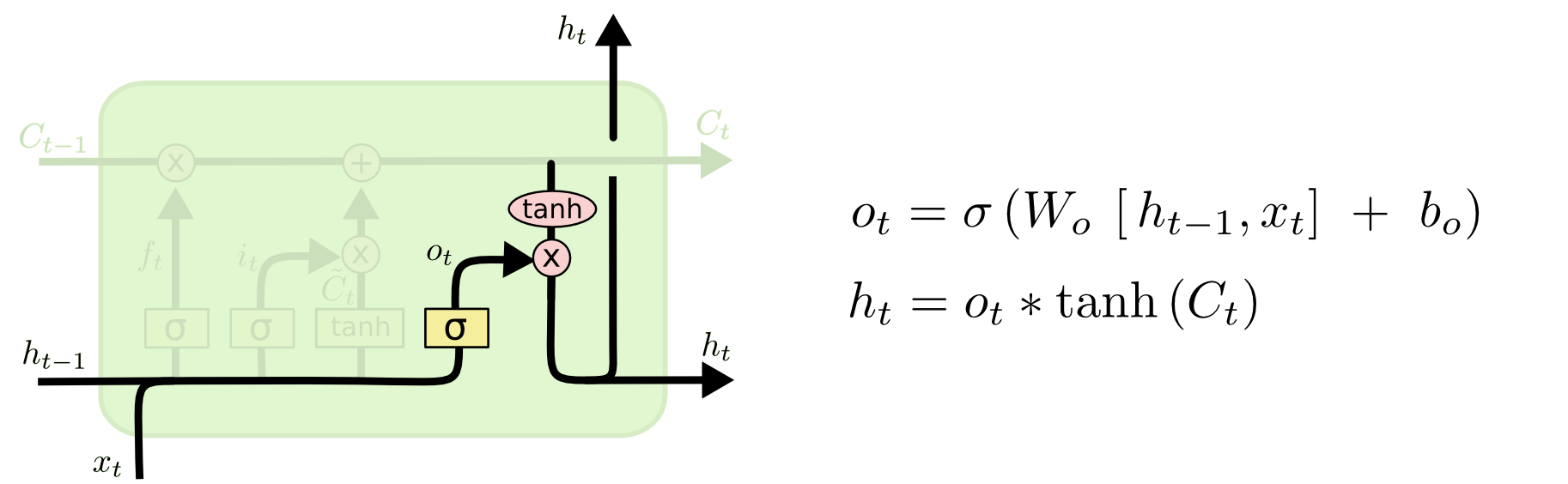
2.2 LSTM 语言模型
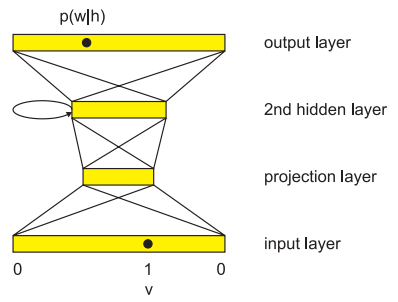
从之前的神经网络语言模型中,我们会发现一些规律:
- 输入词是通过 1-of-K 编码的,其中 $K$ 是词表大小;
- 输出层通过 softmax 得到一个归一化的概率分布;
- 训练过程使用交叉熵损失函数,等价于最大似然估计。
Sundermeyer 等人也使用了相同的方法,用来你构建 LSTM 语言模型。首先将输入层的词经过一个投影层,转化成词嵌入(实际上就是 Embedding 过程),然后传递给 LSTM,最后经过 softmax 进行输出。
对于大规模的语言模型训练来说,softmax 层的计算消耗了大量的时间:
其中 $J$ 表示 LSTM 隐层节点数,$\omega_{ij}$ 表示 LSTM 层与输出层的权重,$i=1,…,V$ ,其中 $V$ 表示词表大小。
为了降低计算时间,Morin & Bengio 、Goodman 提出将词进行分类,然后预测下一个词所在的类别,然后再预测具体的词:
其中 $w_m \in c(w_m)$,$c(w_m)$ 表示 $w_m$ 所在的类别。
2.3 AWD-LSTM 语言模型
LSTM 作为 RNN 最优秀的变种之一,在进行语言建模的时候也有着相当优秀的表现。但是 作为神经网络,LSTM 也存在着泛化性问题。通常为了提高神经网络的泛化性,人们提出了各种各样的正则化策略。
AWD-LSTM 提出了一些正则化和优化策略,这些策略不仅高效,而且可以在不改变 LSTM 结构的条件下实现。它在语言建模上的优异表现使得它一度成为最优秀的语言模型。下面我们就介绍一下这个模型。
LSTM 数学公式:
2.3.1 weight-dropped LSTM
Dropout 是神经网络中常用的防止过拟合的方法,但是用在 RNN 型的网络中通常效果不佳。这与 Dropout 的原理有关,见下图中间:
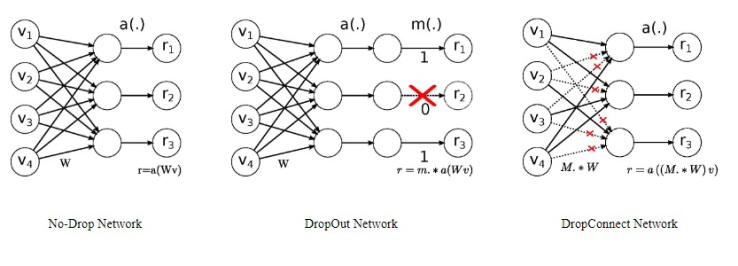
Dropout 会随机丢掉一些神经元,即将神经元节点置为零。这样 $h_t$ 接收到的 $h_{t-1}$ 就不完整了,会干扰 RNN 的长程依赖能力。为了解决这一问题,Wan 等人提出 DropConnect 技术,如上图右侧。不同于 Dropout 的丢掉神经元,DropConnect 是随机丢掉一些权重,完整的保留了神经元。用伪代码来说明如下:
1 | # Dropout |
这样就不会影响到 RNN 的长程依赖能力了。
LSTM 的权重参数包括 $[W_f, W_i, W_C, W_o, U_f, U_i, U_C, U_o]$,其中 $W^{*}$ 是与输入 $x_t$ 相关的, $U^{*}$ 是与隐状态相关的。LSTM 的梯度问题通常与隐状态有关(循环连乘带来的梯度消失或者爆炸),因此将 DropConnect 应用于 $U^{*}$ 上效果更好(当然,$W^{*}$ 和 $U^{*}$ 都用也行,只是考虑到以牺牲效率为代价换来的效果提升并不明显)。
2.3.2 Non-monotonically Triggered ASGD
对于语言建模任务来说,传统的 SGD 优化算法比带动量的 SGD 变体效果更好。因此,作者在调研了一些传统 SGD 算法之后选定了 ASGD 算法。
所谓 ASGD 算法指的是 Averaged SGD 算法,它是 Polyak & Juditsky 等人 1992 年提出的一种优化算法,经过了二十多年的研究发展,ASGD 已经非常成熟,无论是理论研究还是实际表现都非常出色。
ASGD 采取和 SGD 相同的更新步骤 ,不同的是传统 SGD 在更新权重的时候只考虑当前的轮次,而 ASGD 不仅考虑当前的的轮次还考虑之前的轮次,然后计算平均值。用伪代码来表示如下:
1 | # 传统 SGD |
其中 $K$ 表示在计算权重平均值之前权重更新的迭代的次数,也就是说,前 $K$ 轮的 ASGD 与 SGD 是完全相同的。
但是作者认为这种方法有两处不足:
- 学习率的调整原则不明确;
- 参数 $K$ 作为超参,其取值原则也不明确。$K$ 值太小会对效果产生负面影响;取值太大可能需要更多的迭代才能收敛。
因此,作者提出了 ASGD 的一种变体—— NT-ASGD,即非单调触发 ASGD(Non-monotonically Triggered ASGD),算法如下:

- 当模型评估指标多轮训练($n$)后都没有提升的时候 ASGD 就会触发,实验发现 $n=5$ 的效果最好;
- 整个实验使用恒定的学习率。
2.3.3 其他正则化方法
除了上面讨论到的两种技术,论文作者还使用了其他预防过拟合、提升数据效率的正则化技术。
2.3.3.1 可变长度反向传播序列
一般在训练语言模型的时候,将整个语料看成一个连续的超长的句子,在预处理的时候会将句子截断成固定长度的 batch size 个序列。这样由于句子被截断,在后向传播的过程中神经网络学到的信息就不玩完整了。比如:
1 | 原始语料:“我是中国人。我爱北京天安门。” |
“我爱北京天安门。”这句话中的 “我” 就无法学到任何信息,因为它后面的内容被截断了。
为了解决这个问题,作者提出了使用可变长度的反向传播序列。首先以概率 $p$ 选取长度为 $bptt$ 的序列,然后以概率 $1-p$ 选取长度度为 $bptt/2$ 的序列。($p$ 是个超参数,实验中作者选用的 $p=0.95$)。
1 | base_bptt = bptt if np.random.random() < 0.95 else bptt / 2 |
然后根据 $N(base\_bptt, s)$ 得到序列长度,其中 $s$ 表示标准差,$N$ 表示正态分布。代码如下:
1 | seq_len = max(5, int(np.random.normal(base_bptt, 5))) |
然后再根据 seq_len 改变学习率。因为当学习速率固定时,会更倾向于对短序列,所以需要进行缩放。
1 | lr2 = lr * seq_len / bptt |
作者的这种做法其实还是引入了很多超参。其实还有一种更好的方法,可以在固定长度的 BPTT 下,不影响效果。
上面的例子中,“我是中国人。我爱北京天安门。”被分成了 [“我是中国人。我”, “爱北京天安门。”]。这是通常的做法。我们还可以用下面的这种方法:
原始语料:“我是中国人。我爱北京天安门。”
预处理后:[ “我是中国人。我”,
“是中国人。我爱”,
“中国人。我爱北”,
…
“爱北京天安门。”
]
2.3.3.2 变分 Dropout
通常情况下,每次调用 Dropout 时取样一个新的 dropout mask。但是在 LSTM 中参数是共享的,作者希望在不同的时刻共享的参数也共享同一套 dropout mask,这就是 variational dropout,在隐层作者使用了共享mask 的 dropConnect,而在输入和输出中,作者使用共享 mask 的 variational dropout。但是请注意在不同的 mini-batch 中,mask 是不共享的,所以 mask 的共享和参数共享还是有区别的,dropout mask 的共享是在每一个迭代中发生的,不同的迭代输入的数据不同,为了体现数据的差异性,要保证 dropout mask 不一致。
2.3.3.3 嵌入 Dropout
对嵌入层引入 Dropout,实际上是在词级上操作的,即随机将一些词给去掉,这些被去掉的词的向量值就全为 0,并且在前向和反向传播中都保持这样的操作。对其余没有丢掉的词,用 $\frac{1}{1-p_e}$ 缩放其向量值,$p_e$ 为 Dropout 的比例。
2.3.3.4 权重绑定
共享 embedding 层和 softmax 层,可以降低模型总参数。语言模型的最后输出也是 $|\mathcal{V}|$ 维,是预测词表中每个词的概率,从模型设计上来看嵌入层和最后输出层的参数矩阵的维度是很容易保证一致的,而从语言模型的特性上来看两个矩阵之间也是有一定的联系,所以作者选择共享嵌入层和输出层的权重矩阵,这种方法在 seq2seq 中也经常用到。
2.3.3.5 减小嵌入尺寸
减少语言模型的总参数量的最简单方法是降低词向量的尺寸,尽管这无助于缓解过拟合。论文作者修改了第一个和最后一个 LSTM 层的输入和输出维度,以和降低了的嵌入尺寸保持一致。
2.3.3.6 激活正则化和时域激活正则化
常见的正则化技术除了 Dropout 以外还有 $L_2$ 正则化。坐着在模型中不仅用了 Dropout 还用了 $L_2$ 正则化,$L_2$ 正则化分成两部分:
对每个单独的 $h_t$ ,用于惩罚明显过大的值。这部分称之为 Activation Regularization:
其中 $m$ 为 dropout mask,$\alpha$ 为缩放系数。
对 $h_t$ 和 $h_{t+1}$ 之间的差值,用于惩罚隐状态变动过大,称之为 Temporal Activation Regularization。这一步很容易理解,$h_{t}$ 包含了之前的所有信息,$h_{t+1}$ 不仅包含了之前的所有信息,还包含了当前信息。一个通顺的句子包含的信息应该是平滑的,不会因为某个词的出现大规模改变隐状态。如果两个连续的隐状态之间出现了较大的差别很可能是训练过程出现了问题,所以通过 $L_2$ 正则化进行修正:
3. 总结
本文介绍了 LSTM 语言模型,尤其着重介绍了 AWD-LSTM 语言模型。LSTM 作为在 Transformer 出现之前最优秀的序列建模的模型一直是 NLP 中的王者,实际上即使是 Transformer 在众多任务中的表现强于 LSTM,但是 LSTM 在序列位置捕捉能力上还是强于 Transformer。本文不仅包含了 LSTM 语言建模的思路 ,也介绍了多种非常有用的序列建模的优化方法。
4. Reference
Morin, F., Bengio, Y.,Hierarchical Probabilistic Neural Network Language Model
Goodman, J., Classes for fast maximum entropy training
Martin Sundermeyer, Ralf Schluter, and Hermann Ney,LSTM Neural Networks for Language Modeling
Stephen Merity, Nitish Shirish Keskar, Richard Socher,Regularizing and Optimizing LSTM Language Models
Li Wan, Matthew Zeiler, Sixin Zhang, Yann Le Cun, Rob Fergus,Regularization of Neural Networks using DropConnect
Yashu Seth, What makes the AWD-LSTM great?