
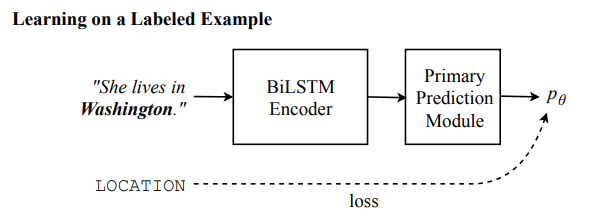
之前介绍的预训练模型都是将预训练过程和下游特定任务分成两阶段进行训练, Cross-View Training 将着来年各个阶段合并成一个统一的半监督学习过程:bi-LSTM 编码器通过有标注数据的监督学习和无标注数据的无监督学习同时训练。
1. 前言
同时使用标注数据和无标注数据进行模型训练,这种训练方式是典型的半监督学习。CVT 引入半监督学习中的自学习机制(self-training)用于神经网络序列建模。
假设标注数据集和无标注数据集分别为 $D_{l}$ 和 $D_u$,经典的自学习机制过程如下:
- 首先从 $D_l$ 中训练一个模型 $M$;
- 然后将从 $D_u$ 中抽取部分数据 $D’_u$ 出来,用 $M$ 进行预测:$y’=M(D’_u)$;
- 将 $M$ 的预测结果 $y’$ 与 $D’_u$ 视为新的标注数据 $(D’_u, y’)$ 放进 $D_l$ 中;
- 重复上面的步骤,知道所有数据都变成 $D_l$。
自学习机制的缺点也很明显:一旦在第二步中出错,在以后的训练中错误会越来越深。在 CV 领域人们提出给无标注数据加噪声的方法,使模型泛化性得到了有效的提升。但是对于 NLP 这种离散序列数据来说,如何加噪声就变得很棘手了。
受多视角学习(multi-view learning) 的启发,CVT 增加了额外的预测模块用来对无标注数据进行预测。
2. Cross-View Training
2.1 Method
- $D_l = \{(x_1, y_1), (x_2, y_2),…,(x_N, y_N)\}$ 表示标注数据;
- $D_u = \{x_1, x_2,…,x_M\}$ 表示无标注数据;
$p_\theta(y|x_i)$ 表示模型参数为 $\theta$ 时,输入 $x_i$ 模型的输出结果。
在有标注的数据上,所有的模型参数都以标准的监督学习方式进行更新,模型的损失函数是标准的交叉熵损失函数:
在无标注的数据上:
① 首先用原始预测模块(primary prediction models)对无标注数据进行预测得:$p_\theta(y|x_i)$;
② 然后用 $k$ 个附加预测模块(auxiliary prediction modules)将 $p_\theta(y|x_i)$ 作为 ground truth,用加噪声的无标注数据进行预测,然后计算损失:
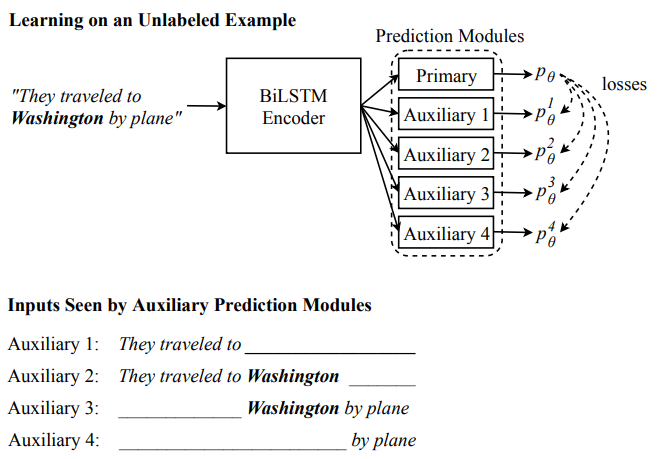
- 最后,整个模型的损失为:
2.2 Multi-Task Learning
对多任务同时进行训练时,CVT 增加了几个相应的原始预测模块。所有原始预测模块共享句子表示编码器。进行监督学习时,模型随机选择一个任务进行训练。此时,模型的句子表示编码器和任务预测器的参数会随着训练更新,与选定任务无关的预测器的参数不会更新。比如,同时训练分类和序列标注时,当模型随机选择分类任务进行训练时,序列标注的预测器参数不会随训练更新。
当进行 CVT 学习时,模型的所有参数都会更新。比如训练分类任务和序列标注任务时,首先用原始预测模块分别预测类别 $c_1$ 和输出序列 $s_1$,然后以此为 ground truth,对 $x_i$ 进行加噪声,利用加噪声后的 $x_i^j$ 再分别预测类别 $c_1^j$ 和输出序列 $s_i^j$,然后分别计算 $(c_1, c_1^j)$ 和 $(s_1, s_1^j)$ 的损失,然后利用后向传播,对参数进行更新。
多任务学习可以使模型泛化能力得到加强,同时可以得到一个副产物:将所有无标注数据进行标注得到标注数据。
3. Cross-View Training Models
由于 CVT 依赖的附加预测模块需要对输入进行加噪声,即限制输入的“视角”。下面我们介绍一些特定任务下,加噪声的方法。
需要注意的是:当原始预测模块有 dropout 的时候,在进行监督学习时可以让 dropout 正常工作,但是在进行无监督训练时 dropout 需要关闭。
3.1 Bi-LSTM 句子编码
- 输入: $x_i = [x_i^1, x_i^2, …, x_i^T]$;
- 词向量:$v = \text{word embedding}(x_i) + \text{CNN}(\text{char}(x_i))$:
- $\text{layer}-1 \text{bi-LSTM}$:$h_1=\text{bi-LSTM}(v)=[\overrightarrow{h}{_1^1} \oplus \overleftarrow{h}{_1^1}, \overrightarrow{h}{_1^2} \oplus \overleftarrow{h}{_1^2} …, \overrightarrow{h}{_1^T} \oplus \overleftarrow{h}{_1^T}]$ ;
- $\text{layer}-2 \text{bi-LSTM}$:$h_2=\text{bi-LSTM}(h_1)=[\overrightarrow{h}_2^1 \oplus \overleftarrow{h}{_2^1}, \overrightarrow{h}_2^2 \oplus \overleftarrow{h}{_2^2} …, \overrightarrow{h}{_2^T} \oplus \overleftarrow{h}{_2^T}]$;
3.2 序列标注
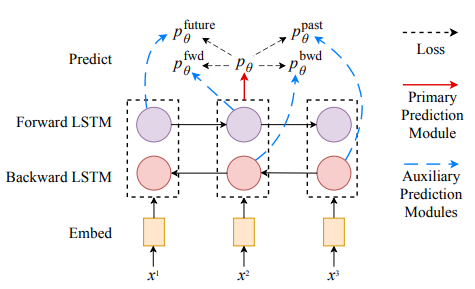
序列标注任务(比如词性标注、命名实体识别)中,模型对序列中的每个词进行分类,预测模块包含一个全连接层和一个 softmax 层:
在进行额外预测任务时,只给第一层 bi-LSTM 输入单向序列。因为这样的话,模型只观察到部分序列,就必须像语言模型那样对“未来”词进行预测:
其中 forward 表示模型还没看到右侧的信息做出的预测,future 表示该词没有右侧或者该词本身信息做出的预测,两者的区别在于 forward 表示待预测的词右侧是有下文的,而 future 表示的是待预测的词右侧没有下文。
3.3 Dependency Parsing
依存句法分析任务中,句子中的词被当做是图的节点。词与词之间用有向边进行连接,形成一棵用来描述语法结构的树。$y_i^t = (u, t, r)$ 表示 $x_i^u$ 与 $x_i^t$ 相连,他们的关系是 $r$。
其中
额外预测任务:
每一个句子都会丢失一部分上下文。
3.4 Sequence-to-Sequence Learning
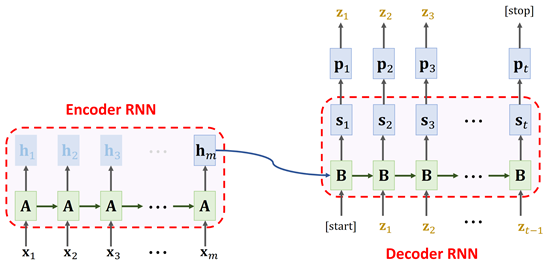
- 源序列:$x_i = x_i^1,…x_i^T$;
- 目标序列:$y_i=y_i^1,…,y_i^K$;
- 注意力得分:$\alpha_j \propto e^{h^jW_\alpha h^t}$;
- 注意力加权的源序列编码:$c_t = \sum_j\alpha_jh^j$;
- 隐状态:$a_t=\tanh(W_a[c_t, h_t])$;
- 预测输出:$p(y_i^t|y_i^{<t}, x_i)=\text{softmax}(W_sa_t)$。
两个附加预测解码器,LSTM 权重共享,但是注意力权重和 softmax 权重是不同的:
对第一个解码器的注意力权重采用 dropout;
让第二个解码器预测目标序列的下一个词,而不是当前词:
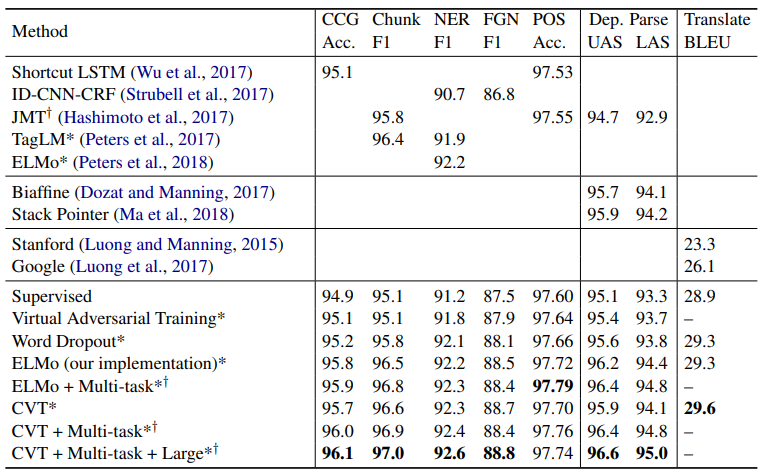
4. Experiments
Reference
- Semi-Supervised Sequence Modeling with Cross-View Training, Kevin Clark, Minh-Thang Luong, Christopher D. Manning, Quoc V. Le. 2018. arxiv: 1809.08370
- Generalized Language Models,Lil’Log
- Lecture13 - Semi-Supervised Learning, 幻想家皮霸霸丶
- Combining labeled and unlabeled data with co-training. Avrim Blum and Tom Mitchell. 1998. In COLT. ACM.
- A survey on multi-view learning. Chang Xu, Dacheng Tao, and Chao Xu. 2013. arXiv preprint arXiv:1304.5634.