
我们仔细回想一下 Transformer 在计算自注意力的过程, 我们会发现,序列中每个词在与其他词计算注意力权重的时候是无差别计算的。也就是说,这里隐藏着一个假设:词与词之间的距离对语义依赖是没有影响的(抛开位置编码的影响)。然而,根据我们的直觉,距离越近的词可能依赖关系会更强一些。那么事实是怎样的呢?Guo 等人 2019 对这个问题进行了研究,并提出 Gaussian Transformer 模型。
1. Motivation
在我们日常生活经验中,句子中的一个词通常会与其周围的词关系更为紧密。传统的自注意力计算中,并没有考虑距离的影响。虽然在 Transformer 中使用了位置编码,但实际上自注意力对此并不敏感,这一点我们在最后讨论,这里简单考虑没有添加位置编码的情况。举个例子:I bought a new book yesterday with a new friend in New York.
句子中一共出现 3 次 “new”。对于 “book” 来说,只有第一个 “new” 是有意义的,其他两个对它没有任何影响,但是从下图 (a)我们可以看到,普通自注意力分配给了 3 个 “new” 以相同的注意力权重。
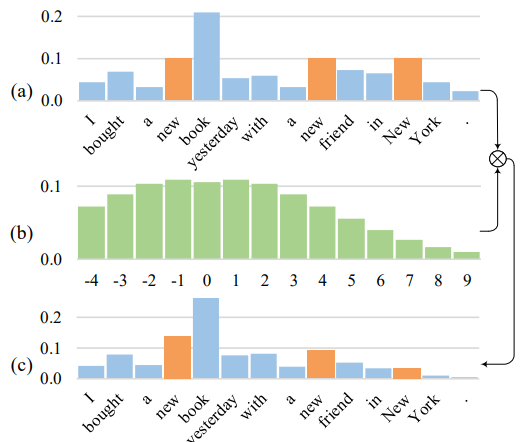
(b)是我c们考虑距离权重,距离越近权重越大,将这个先验的权重加入到自注意力计算过程,我们得到(c)的自注意力分布,从而更有效的对句子内部结构进行建模。
2. Gaussian Self-Attention
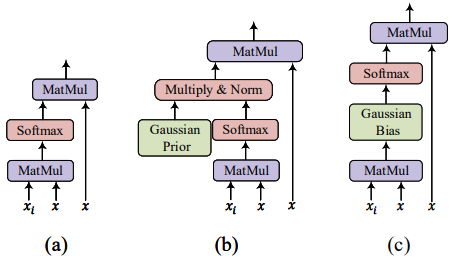
假设 $x_i$ 表示句子 $x$ 中的第 $i$ 个词,普通的注意力计算如上图(a)所示:
为了考虑词与词之间的距离对词义依赖关系的影响,作者考虑加入先验的高斯分布。由于我们很难去真实地统计到底什么样的分布最符合实际情况,所以作者对比了多种不同的分布,最后发现高斯分布的效果最好,所以选择了高斯分布。
为了简单起见,定义标准正态分布:$\sigma^2=1/(2\pi)$,概率密度函数:$\phi(d) = e^{-\pi d^2}$,其中 $d$ 表示词与词之间的距离。将 $\phi(d_{i,j})$ 加入到上式当中:
上式第一步中分母 $\sum_k \phi(d_{i, k}^2)$ 是为了归一化。上式第一个公式是我们直接将高斯分布插入到注意力计算的方式,如上图(b)所示,然后我们发现该式可以通过后续的一系列约化,转化成最后一行公式的形式,如上图(c)所示。这样的约化的好处是将高斯项从因子项转化成偏置项,省去了乘法操作,只需要加法操作即可,这样可以省去很大的计算开销。
由于上面我们假设了高斯的方差为 $1/(2\pi)$,但实际情况不一定是这样的,所以引入一个 $w$ 因子用于弱化这个限制:
通过实验发现,我们再额外加入一个惩罚项 $b$ 用以减弱 $x_i$ 自身的影响效果会更好:
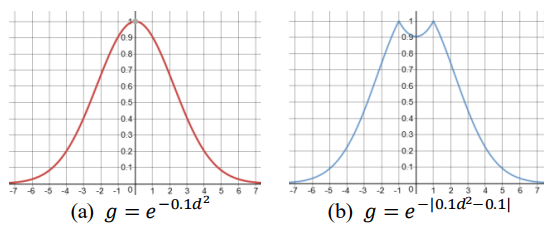
其中 $w>0, b \le 0$ 是标量。加入了二者的高斯分布分别如下图所示:
3. Gaussian Transformer
Gaussian Transformer 模型面向的任务不是机器翻译,甚至不是序列生成任务,而是判别任务。具体来说是为了自然语言推断任务设计的模型。所谓自然语言推断(Natural Language Inference, NLI)又叫文本蕴含识别(Recognizing Textual Entailment, RTE),是研究文本之间的语义关系,含括蕴含(entailment)、矛盾(contradiction)和中性(neutral)。形式上,NLI 是一个文本分类的问题。
形式化描述为:输入一个句子对:$(\{p_i\}^{l_p}_{i=1}, \{h_j\}^{l_h}_{j=1})$ 分别表示前提(premise)和假设(hypothesis),其中 $p_i, h_j \in \mathbb{R}^V$,分别表示两个句子中第 $i$ 和第 $j$ 个词的 one-hot 向量,$l_p, l_h$ 分别表示两个句子的长度, $V$ 表示词表的大小。模型输出 $\{entailment, contradiction, neutral\}$ 代表的标签。
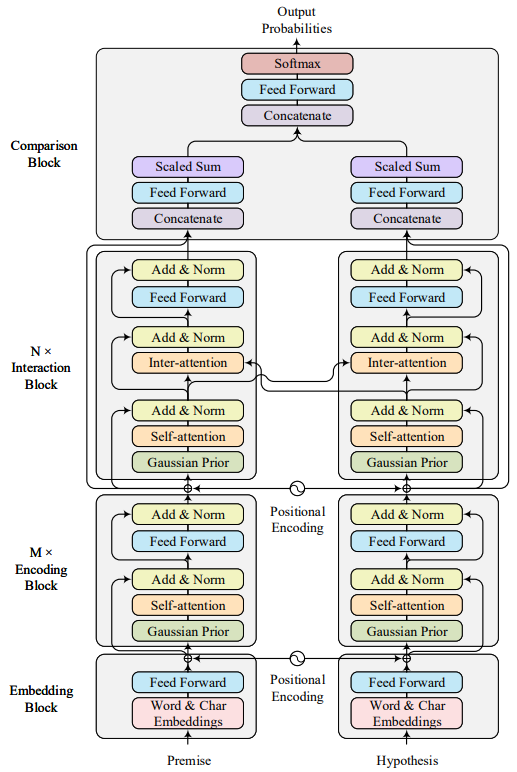
上图展示了 Gaussian Transformer 的整体结构。主要分为:Embedding Block、Encoding Block、Interaction Block 和 Comparison Block 四大部分,下面我们就详细介绍一下每一部分。
3.1 Embedding Block
Embedding Block 的目的是将句子中的每个词转化成高维向量,主要包含三部分:字向量、词向量和位置向量。
字向量
字向量使用随机初始化的 $n-grams$ 字向量进行映射,然后对每个 token 进行 max-over-time pooling:
词向量
词向量就使用预训练的词向量矩阵进行映射:
位置向量
位置向量使用 Transformer 中的位置向量:
有了三个向量之后,将字向量和词向量拼接在一起,然后经过投影矩阵将拼接后的向量投影成 $d_{model}$ 维矩阵,然后与位置向量相加得到最终的 Embedding Block 输出。
位置向量是不需要训练的,字向量和词向量在映射成高维矩阵之后还会经过一个投影矩阵 $W_e$ 将其维度变换成模型需要的 $d_{model}$ 维。字向量和词向量在模型训练过程是固定的,即不需要训练,需要训练的只是投影矩阵。
词向量不训练可以理解,但是字向量是随机初始化的,也不训练这样真的合适吗?
3.2 Encoding Block
在 Encoding Block 中包含了 $M$ 个子模块用来抽取句子特征,每个子模块都有相同的结构,除了计算多注意力的时候引入了高斯分布以外,其他都与 Transformer 保持一致。
因此,每个子模块包含两部分:
- 多头高斯自注意力层
- FFN 层
层与层之间使用残差网络和 LayerNorm 连接。
这部分的核心是高斯自注意力,我们在上一章已经详细介绍过了,其他的和 Transformer 一致,因此不再赘述。
3.3 Interaction Block
Interaction Block 的作用是将两个句子进行信息交互。这一部分与原始的 Transformer 的 Decoder 部分类似, 区别是我们去掉了 Positional Mask 和解码的部分。 通过堆叠 $N$ 个 Interaction 模块,我们可以捕获高阶交互的信息。
3.4 Comparison Block
Comparison Block 的作用就是模型最后的输出预测了。这个模块包含两部分:
聚合层
在聚合层,作者将 Encoding Block 以及 Interaction Block 的输出拼接到了一起,然后经过了两层带 relu 函数的全连接将维度从 $2d_{model}$ 变为 $d_{model }$。然后又经过了一个缩放的加法,后面就输入到了预测层:
预测层
我们使用经典的 MLP 分类器对输出进行分预测:
4. Experiment
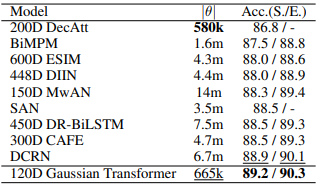
从实验结果可以看出,Gaussian Transformer 相比其他模型不仅参数量上非常少,而且效果也达到了最佳。另外在效率上,作者对比了 ESIM 模型,发现 GT 不仅准确率更高,而且训练速度提升了近 4 倍,推理效率提升了近8 倍。
5. 高斯假设的有效性问题
之前我们在最开始讨论的时候,假设在计算自注意力的时候不考虑位置编码。那么高斯假设和加上位置编码后的自注意力相比究竟是不是有效呢?这里作者进行了讨论。
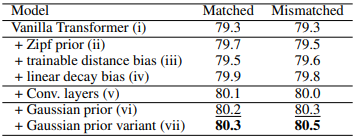
作者对比了原始 Transformer 与 GT 在 MultiNLI 数据集上的表现,发现 GT 的效果更优。另外,作者也对比了不同的分布假设以及 GT 的各种变种,最终发现上面的方法是最优的。
Reference
Gaussian Transformer: A Lightweight Approach for Natural Language Inference, Maosheng Guo, Yu Zhang, Ting Liu. 2019. AAAI
Gaussian Transformer论文解读, 宋青原,知乎