1. 简介
1.1 词表/语料
词表表示语言中包含的所有的词,比如对于中文来说:
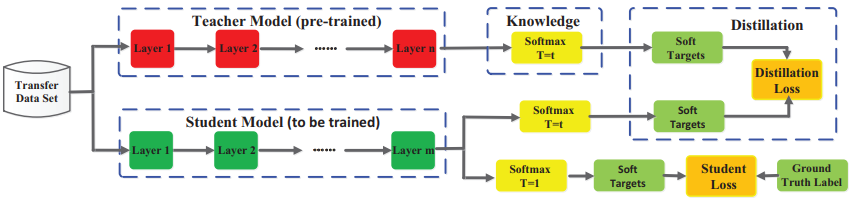
文章转载自:模型压缩 | 知识蒸馏经典解读。
知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方法,由于其简单,有效,在工业界被广泛应用。这一技术的理论来自于2015年Hinton发表的一篇神作:Distilling the Knowledge in a Neural Network
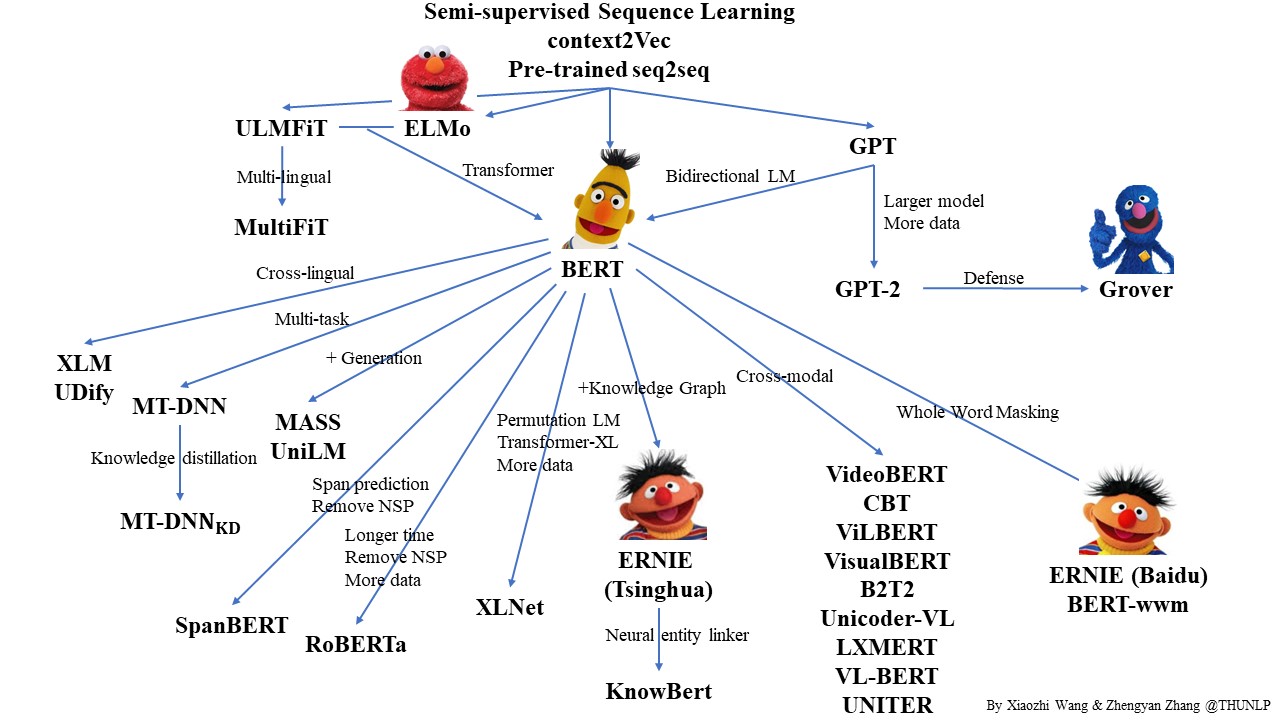
自从 2017 年 Vaswani 等人提出 Transformer 模型以后 NLP 开启了一个新的时代——预训练语言模型。而 2018 年的 BERT 横空出世则宣告着 NLP 的王者降临。那么,什么是预训练?什么是语言模型?它为什么有效?

Transformer 的功能强大已经是学术界的共识,但是它难以训练也是有目共睹的。本身的巨大参数量已经给训练带来了挑战,如果我们想再加深深度可谓难上加难。这篇文章将会介绍几篇就如何加深 Transformer 的展开研究论文。从目前的研究来看 Transformer 之所以难训是由于梯度消失的问题,要对 Transformer 进行加深就必须要解决这个问题,今天我们介绍三种方法:
我们仔细回想一下 Transformer 在计算自注意力的过程, 我们会发现,序列中每个词在与其他词计算注意力权重的时候是无差别计算的。也就是说,这里隐藏着一个假设:词与词之间的距离对语义依赖是没有影响的(抛开位置编码的影响)。然而,根据我们的直觉,距离越近的词可能依赖关系会更强一些。那么事实是怎样的呢?Guo 等人 2019 对这个问题进行了研究,并提出 Gaussian Transformer 模型。
Levenshtein Transformer 不仅具有序列生成的能力,还具有了序列修改的能力。然而我们会发现,整个模型实际上是很复杂的。从模型结构上讲,除了基础的 Transformer 结构,还额外增加了三个分类器:删除分类器、占位符分类器和插入分类器。从训练过程来讲,LevT 需要一个参考策略(expert policy),这个参考策略需要用到动态规划来最小化编辑距离。这样无论从训练还是才能够推理角度,我们都很难保证模型的效率。那么有没有一个既有 LevT 这样的强大的能力,又保持高效简洁的模型呢?Insertion-Deletion Transformer 就这样应运而生了(内心 os:你永远可以相信宋义进:joy:)。