
之前介绍的预训练模型都是将预训练过程和下游特定任务分成两阶段进行训练, Cross-View Training 将着来年各个阶段合并成一个统一的半监督学习过程:bi-LSTM 编码器通过有标注数据的监督学习和无标注数据的无监督学习同时训练。
之前介绍的预训练模型都是将预训练过程和下游特定任务分成两阶段进行训练, Cross-View Training 将着来年各个阶段合并成一个统一的半监督学习过程:bi-LSTM 编码器通过有标注数据的监督学习和无标注数据的无监督学习同时训练。
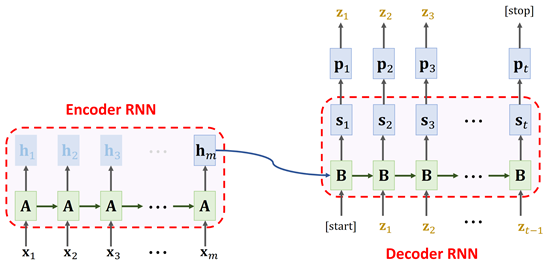
之前我们介绍过 seq2seq 模型,通常用作机器翻译,通过编码器(encoder)对源语言进行编码,然后通过解码器(decoder)对编码器的结果进行解码,得到目标语言。原始的 seq2seq 模型是使用平行语料对模型从头开始进行训练,这种训练方式需要大量的平行语料。Prajit Ramachandran 提出一种方法,可以大幅降低平行语料的需求量:先分别使用源语言和目标语言预训练两个语言模型,然后将语言模型的权重用来分别初始化编码器和解码器,最终取得了 SOTA 的结果。

数据噪化(data noising)是一种非常有效的神经网络正则化的有段,通常被用在语音和视觉领域,但是在离散序列化数据(比如语言模型)上很少应用。本文尝试探讨给神经网络语言模型加噪声与 n-gram 语言模型中的平滑之间的联系,然后利用这种联系设计出一种噪声机制,帮助我们对语言进行建模。
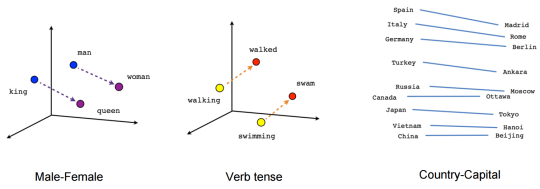
上一篇文章我们介绍了预训练词向量,它的缺点很明显:一旦训练完,每个词的词向量都固定下来了。而我们平时生活中面临的情况却复杂的多,一个最重要的问题就是一词多义,即同一个词在不同语境下有不同的含义。CoVe(Contextual Word Vectors)同样是用来表示词向量的模型,但不同于 word emebdding,它是将整个序列作为输入,根据不同序列得到不同的词向量输出的函数。也就是说,CoVe 会根据不同的上下文得到不同的词向量表示。
神经网络三大神器:DNN、CNN、RNN。其中 DNN 和 RNN 都已经被用来构建语言模型了,而 CNN 一直在图像领域大展神威,它是否也可以用来构建语言模型呢?如果要用 CNN 构建语言模型应该怎么做?接下来我们从四篇论文看 CNN 构建语言模型的三种方法。
统计语言模型中,无论是 n-gram 还是对数线性语言模型都面临一个非常严重的问题——维度爆炸。为了解决维度爆炸问题,Bengio & Bengio 2000 年提出了一种使用分布式词特征表示的方法,也就是后来所说的词向量。
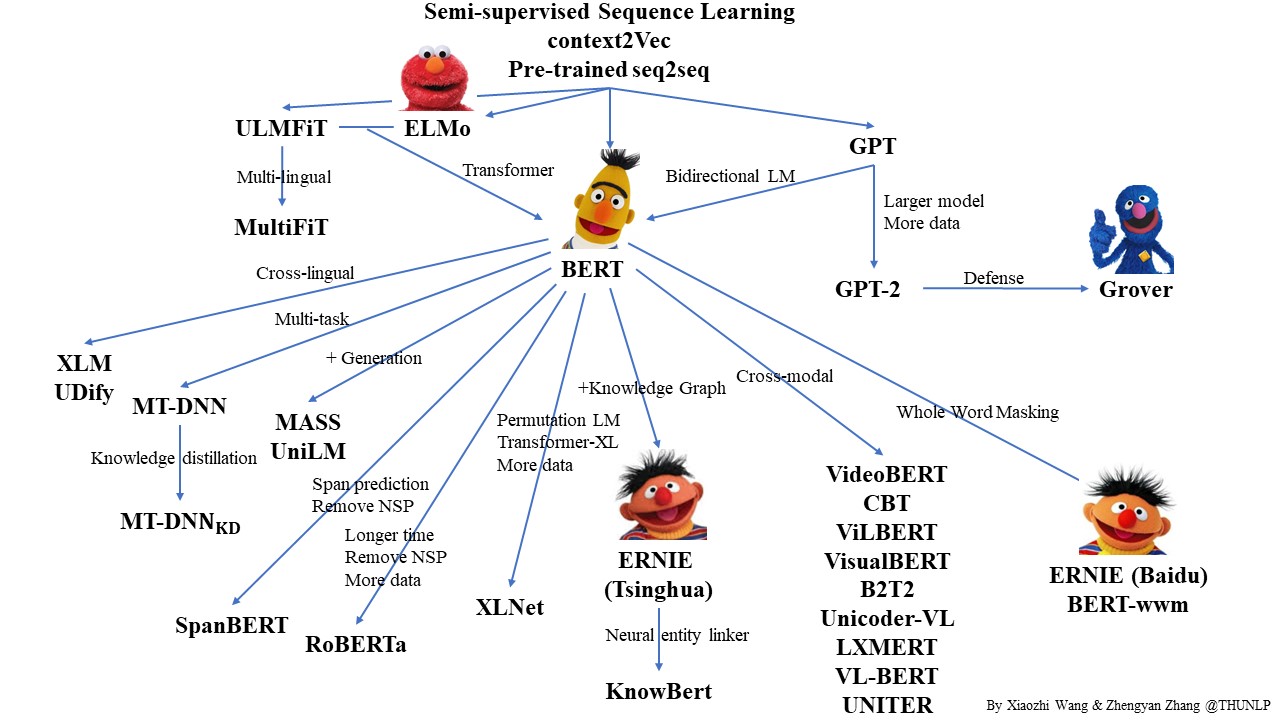
自从 2017 年 Vaswani 等人提出 Transformer 模型以后 NLP 开启了一个新的时代——预训练语言模型。而 2018 年的 BERT 横空出世则宣告着 NLP 的王者降临。那么,什么是预训练?什么是语言模型?它为什么有效?