
本文介绍队列数据结构,并用 Python 代码实现。
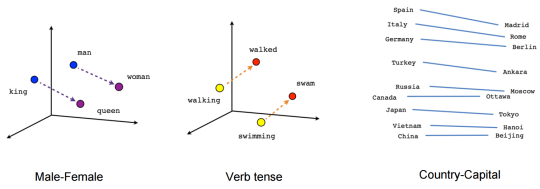
上一篇文章我们介绍了预训练词向量,它的缺点很明显:一旦训练完,每个词的词向量都固定下来了。而我们平时生活中面临的情况却复杂的多,一个最重要的问题就是一词多义,即同一个词在不同语境下有不同的含义。CoVe(Contextual Word Vectors)同样是用来表示词向量的模型,但不同于 word emebdding,它是将整个序列作为输入,根据不同序列得到不同的词向量输出的函数。也就是说,CoVe 会根据不同的上下文得到不同的词向量表示。
前缀树(trie)又叫字典树,顾名思义通过字符串的前缀进行查找、匹配的数据结构。Trie 树的应用场景主要包括:分词、词频统计、字符串查询和模糊匹配、字符串排序等。Trie 树大幅降低重复字符串的比较,所以执行效率非常高。
词嵌入(word embedding)是一种用稠密向量来表示词义的方法,其中每个词对应的向量叫做词向量(word vector)。词嵌入通常是从语言模型中学习得来的,其中蕴含着词与词之间的语义关系,比如 “猫” 和 “狗” 的语义相似性大于 “猫” 和 “计算机” 。这种语义相似性就是通过向量距离来计算的。
本文转载自知乎用户码农要术的文章 衡量指标篇:ROC-AUC。
1941年,日军偷袭珍珠港,太平洋战争由此爆发。美军的雷达操作员(Radar operator)开始忙碌了起来,他们要识别出雷达屏幕上的光点是不是日本的战机。
