前缀树(trie)又叫字典树,顾名思义通过字符串的前缀进行查找、匹配的数据结构。Trie 树的应用场景主要包括:分词、词频统计、字符串查询和模糊匹配、字符串排序等。Trie 树大幅降低重复字符串的比较,所以执行效率非常高。
1. Trie 树简介
前缀树是将字符串存储在一棵树结构内,该树是将字符串的公共前缀作为父节点。以下图为例:
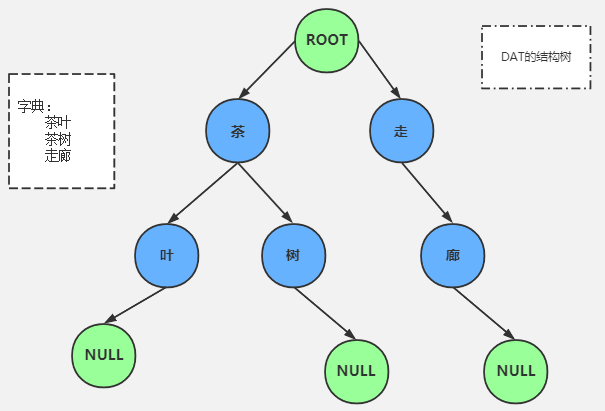
假设有三个词,分别是“茶叶”、“茶树”、“走廊”。将这三个词存储在 Trie 树里如上图所示。“茶树”和“茶叶”有公共前缀“茶”,所以“茶”作为“叶”和“树”的父节点。而“走廊”和前两个词无公共前缀,所以独立成一个分支。另外 root 节点表示根节点,所有词的匹配、查找都是从根节点开始的。而 null 为叶节点表示从根节点 root 到 叶子节点 null 的路径组成一个完整的词。Trie 树具有以下几个特点:
- 具有相同前缀的词必须位于同一个路径下。“叶”和“树”要共用一个父节点“茶”。
- Trie 树中的词只可共用前缀,不可共用词的其他部分。比如,现在有一个新词“卖茶”,虽然都有“茶”,但是它并不是“卖茶”的前缀,所以“卖茶”要与“茶叶”和“茶树”在不同的分支上。
- Trie 树中任何一个完整的词,都必须是从根节点开始至叶子节点结束,这意味着对一个词进行检索也必须从根节点开始,至叶子节点才算结束。
2. 搜索 Trie 树的时间复杂度
在 Trie 树中搜索一个字符串,会从根节点出发,沿着某条路径向下逐字比对字符串的每个字符,直到抵达底部的叶子节点才能确认字符串为该词,这种检索方式具有以下两个优点:
公共前缀的词都位于同一个串内,查词范围因此被大幅缩小(比如首字不同的字符串,都会被排除)。
Trie 树实质是一个有限状态自动机(Deterministic Finite Automaton, DFA),这就意味着从 Trie 树 的一个节点(状态)转移到另一个节点(状态)的行为完全由状态转移函数控制,而 状态转移函数本质上是一种映射,这意味着:逐字搜索 Trie 树时,从一个字符到下一个字符比对是不需要遍历该节点的所有子节点的。
确定的有限自动机 M 是一个五元组:
其中,
$\Sigma$ 是输入符号的有穷集合;
$Q$ 是状态的有限集合;
$\delta$ 是 $Q$ 与 $\Sigma$ 的直积 $Q × \Sigma$ 到 $Q$ (下一个状态) 的映射。它支配着有限状态控制的行为,有时也称为状态转移函数。
$q_0 \in Q$ 是初始状态;
$F$ 是终止状态集合,$F \subseteq Q$;
可以把 DFA 想象成一个单放机,插入一盘磁带,随着磁带的转动,DFA 读取一个符号,依靠状态转移函数改变自己的状态,同时磁带转到下一个字符。
这两个优点相结合可以最大限度地减少无谓的字符比较,使得搜索的时间复杂度理论上仅与检索词的长度有关:$O(m)$,其中 $m$ 为检索词的长度。
3. Trie 树的缺点
综上可知, Trie 树主要是利用词的公共前缀缩小查词范围、通过状态间的映射关系避免了字符的遍历,从而达到高效检索的目的。这一思想有赖于字符在词中的前后位置能够得到表达,因此其设计哲学是典型的“以信息换时间”,当然,这种优势同样是需要付出代价的:
- 由于结构需要记录更多的信息,因此 Trie 树的实现稍显复杂。好在这点在大多数情况下并非不可接受。
- Trie 型词典不仅需要记录词,还需要记录字符之间、词之间的相关信息,因此字典构建时必须对每个词和字逐一进行处理,而这无疑会减慢词典的构建速度。对于强调实时更新的词典而言,这点可能是致命的,尤其是采用双数组实现的 Trie 树,更新词典很大概率会造成词典的全部重构,词典构建过程中还需处理各种冲突,因此重构的时间非常长,这导致其大多用于离线;不过也有一些 Trie 可以实现实时更新,但也需付出一定的代价,这个缺点一定程度上影响了 Trie 树的应用范围。
- 公共前缀虽然可以减少一定的存储空间,但 Trie 树相比普通字典还需表达词、字之间的各种关系,其实现也更加复杂,因此实际空间消耗相对更大(大多少,得根据具体实现而定)。尤其是早期的“Array Trie”,属于典型的以空间换时间的实现,(其实 Trie 本身的实现思想是是以信息换时间,而非以空间换时间,这就给 Trie 树的改进提供了可能),然而 Trie 树现今已经得到了很好的改进,总体来说,对于类似词典这样的应用,Trie 是一个优秀的数据结构。
4. Trie 树的几种实现
Trie 树实现:一般的链表指针方式,三数组实现,双数组实现,HAT,burst trie 等。
链表指针方式
即每个节点对应一个字符,并有多个指针指向子节点,查找和插入从根节点按照指针的指向向下查询。这种方案,实现较为简单,但指针较多,较为浪费空间;树形结构,指针跳转,对缓存不够友好,节点数目上去之后,效率不够高。
Hash Trie 树以及 Burst trie
是将 trie 树和其他数据结构,比如 HashMap,结合起来,提高效率。但主要用于键值查找,对于给定一个字符串匹配其前缀这种场景不适用。
三数组实现
利用三个数组(分别叫做 base, next, check)来实现状态的转移,将前缀树压缩到三个数据里,能够较好的节省内存;数组的方式也能较好的利用缓存。
双数组实现
是在三数组的基础上,将 base 数组重用为 next 数组,节省了一个数组,并没有增加其他开销。与三数组相比,内存使用和效率进一步提升。
综上,双数组 trie(Double Array trie,简称为 DATrie)的实现有明显的优势,以下讨论 DATrie 的细节(只介绍构造和查询,删除节点不常用,而且比较复杂,暂时略过)。
5. Double-Array Trie 树
5.1 DATrie 构造方法
数组表示 trie 树的状态转移,父节点跳转到子节点转化为父状态跳转到子状态。
利用两个数组
base,check表示状态的转移:base数组的索引用来表示状态base数组里存的数据称为 offsetcheck数组里存的数据是父状态的索引check与base大小相同,一一对应,用于保存父状态,以及解决冲突
状态 S 接收到字符 c 后转移到状态 T:
满足:
1
2
3check[base[S] + c] = S
base[S] + c = T
base[T] = base[S]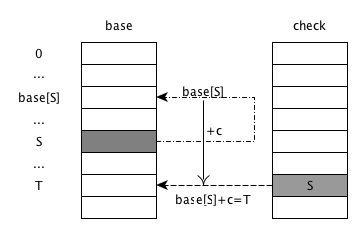
base数组的索引为 0,1,…, base[s], …, S, …, T,均表示 trie 树的状态- 从 S 状态接收到 c 跳转到 T, 则表示为 base 数组索引为 S 的内容 base[S] 为基地址,加上跳转偏移 c,得到下一个 T 状态在 base 的索引
T=base[S] + C check数组对应 T 的内容 check[T] 为跳转过来的父状态,即 S。
5.2 DATrie 查询
- 从
base数组索引 0 开始,初始状态为 S=base[0],其中偏移的基地址为 base[S] - 接受到 c,则跳转到
base数组索引 T=base[S] + c,检查此时check数组的 check[T] == S,为真跳转到 3,否则匹配失败。 - 如果
base[T] == LEAF_VALUE(这里LEAF_VALUE用来表示叶子节点的特殊值),则匹配完成;否则,令 S = T, 跳转到 2。
状态更新的伪码如下:
1 | T := base[S] + c |
5.3 举个例子
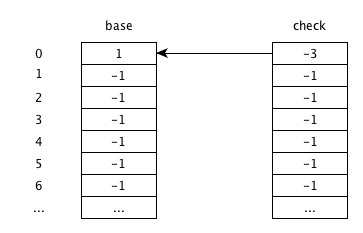
假定输入两个前缀为 ‘ab’ , ‘ad’ ,将字母 a-z 映射为数字 1,2,3,…, 26.
这里用 -1 代表数组元素为空,-2 代表叶子节点,-3 代表根节点
状态如下:
初始状态
输入 ‘a’ (’ab’)
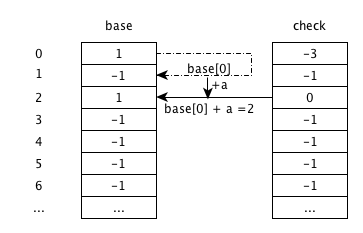
base[0]+a,由状态 0 跳转到状态 2。check[2]为 -1,说明为空,更新为父状态 0;base[2]更新为跳转过来的base, 即base[0]的值 1。输入 ‘b’ (’ab’)
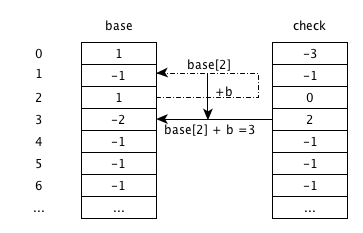
base[2]+b,由状态 2 跳转到状态 3,check[3]为 -1,说明为空,更新为父状态 2;由于字符串结束,将base[3]更新为 -2,代表叶节点。输入 ‘a’(’ad’)
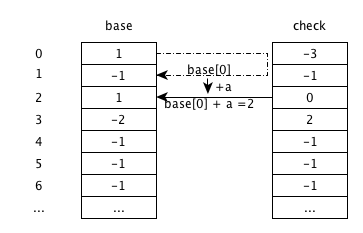
图中
base和check的状态不会变化。 根据base[0]+a,从状态 0 跳转到 2。check[2]不为空,但check[2]的值 0 与其父状态 S=0 相等,则无需更新,进入状态 2,等待输入下一个字符。这个过程相当于一个查询过程。输入 ‘d’ (’ad’)
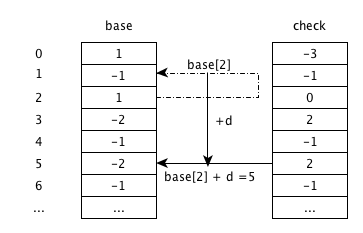
base[2]+d,由状态 2 跳转到状态 5,check[5]为 -1,说明为空,更新为父状态 2;由于字符串结束,将base[5]更新为 -2,代表叶节点。
5.4 解决冲突
DATrie 不可避免会出现冲突。仍以上面的例子说明,继续插入 ‘ca’:
输入 ‘c’(’ca’)
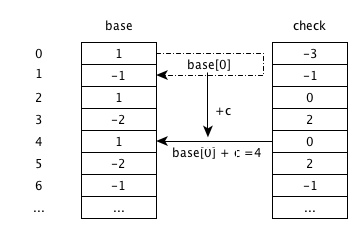
状态由 0 跳转到状态 4,
check[4]空闲,将check[4]赋值为 0,base[4]赋值为1。输入 ‘a’ (’ca’)
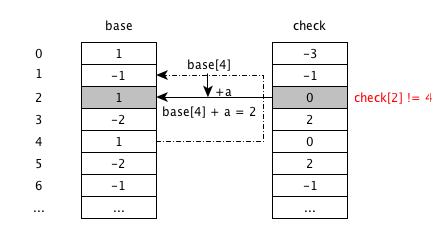
根据
base[4]+4状态从4跳转到2, 但是check[2]非空,并且check[2]=0不等于父状态 4,此时发生冲突。解决冲突
挪动以 4 为父状态状态转移,查找对应
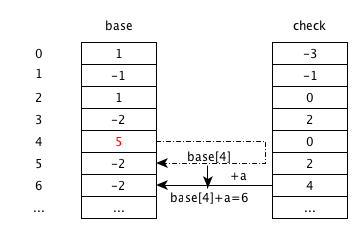
base,check的连续的空闲空间以放入状态。这里只有最新的输入 ‘a’ 带来的状态转移以 4 为父状态。base[6],check[6]有空闲。修改
base[4], 使其能够根据输入跳转到空闲空间,即base[4] = 6 - a = 5。重新插入 ‘a’,如下图
6. Trie 树的压缩
双数组 Trie 树虽然大幅改善了经典 Trie 树的空间浪费,但是由于冲突发生时,程序总是向后寻找空地址,导致数组不可避免的出现空置,因此空间上还是会有些浪费。另外, 随着节点的增加,冲突的产生几率也会越来越大,字典构建的时间因此越来越长,为了改善这些问题,有人想到对双数组 Trie 进行尾缀压缩,具体做法是:将非公共前缀的词尾合并为一个节点(tail 节点),以此大幅减少节点总数,从而改善树的构建速度;同时将合并的词尾单独存储在另一个数组之中(Tail array), 并通过 tail 节点的 base 值指向该数组的相应位置,以 {baby, bachelor, badge, jar} 四词为例,其实现示意图如下:
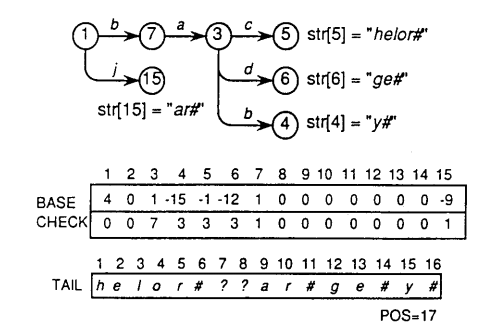
- 速度:减少了
base,check的状态数,以及冲突的概率,提高了插入的速度。 - 内存:状态数的减少的开销大于存储 tail 的开销,节省了内存。
- 删除:能很方便的实现删除,只需将 tail 删除即可。
7. 总结
- Trie 树是一种以信息换时间的数据结构,其查询的复杂度为 $O(m)$。
- Trie 的单数组实现能够达到最佳的性能,但是其空间利用率极低,是典型的以空间换时间的实现。
- Trie 树的哈希实现可以很好的平衡性能需求和空间开销,同时能够实现词典的实时更新。
- Trie 树的双数组实现基本可以达到单数组实现的性能,同时能够大幅降低空间开销;但是其难以做到词典的实时更新。
- 对双数组 Trie 进行 tail 改进可以明显改善词典的构建速度,同时进一步减少空间开销。
Reference
- 小白详解 Trie 树, xu_zhoufeng
- Double-Array Trie(双数组字典树), huangwei1024
- 前缀树匹配(Double Array Trie), minzhan’s blog
- 双数组前缀树(Double-Array Trie), 两片