之前我们介绍过 seq2seq 模型,通常用作机器翻译,通过编码器(encoder)对源语言进行编码,然后通过解码器(decoder)对编码器的结果进行解码,得到目标语言。原始的 seq2seq 模型是使用平行语料对模型从头开始进行训练,这种训练方式需要大量的平行语料。Prajit Ramachandran 提出一种方法,可以大幅降低平行语料的需求量:先分别使用源语言和目标语言预训练两个语言模型,然后将语言模型的权重用来分别初始化编码器和解码器,最终取得了 SOTA 的结果。
1. Method
1.1 Basic Procedure
给定输入序列 $x_1, x_2, …, x_m$,seq2seq 的目的是最大化:
seq2seq 模型是使用编码器(RNN)将 $x_1, x_2, …, x_m$ 表示成一个隐向量,然后将隐向量传递给解码器进行序列解码。我们的方法是将编码器和解码器都当做 RNN 语言模型进行使用大量的语料进行预训练。
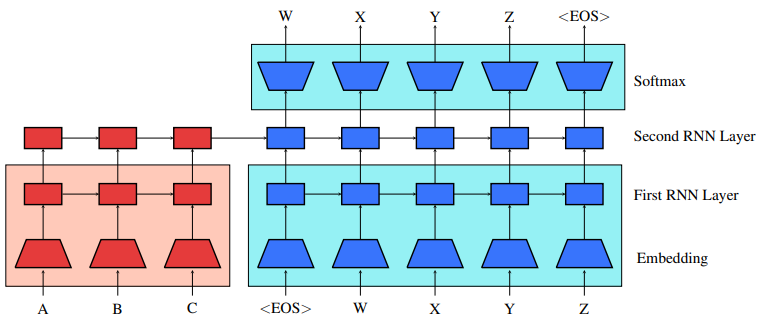
两个语言模型训练完成以后,将两个语言模型的权重用来初始化编码器和解码器。为了方便起见,解码器的 $\text{softmax}$ 使用目标语言的语言模型的 $\text{softmax}$ 进行初始化。
1.2 Monolingual language modeling losses
使用语言模型初始化 seq2seq 以后,再用平行语料进行 fine-tuning。根据 Goodfellow et al. 2013 的研究,fine-tuning 过程很容易造成灾难性遗忘(catastrophic forgetting),使得模型在语言模型上的性能急剧下降,损害模型的泛化能力。
为了保证模型在平行语料上不会过拟合,在fine-tuning 阶段继续训练语言模型任务,seq2seq 和 语言模型任务的损失等权相加作为最终损失。
1.3 Other improvements to the model
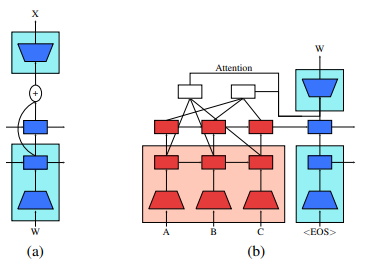
预训练和损失叠加机制能大幅提升模型性能,但是我们发现另外两个可以小幅提升模型能力的技巧:
- 残差连接;
- 多层注意力。
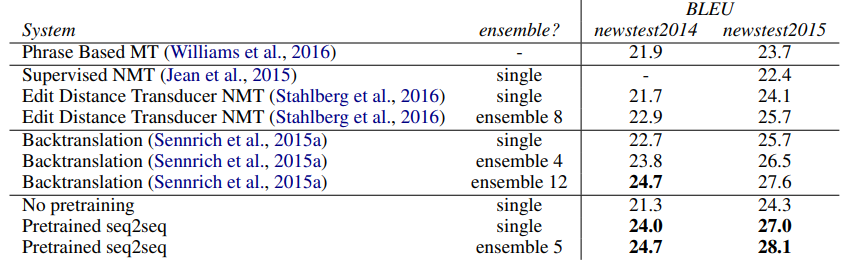
2. Experiments
Reference
- Unsupervised Pretraining for Sequence to Sequence Learning, Prajit Ramachandran, Peter J. Liu and Quoc V. Le 2017, arxiv: 1611.02683
- An empirical investigation of catastrophic forgetting in gradient-based neural networks, Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. 2013. arXiv preprint arXiv:1312.6211