之前我们介绍了 Word Embedding,将词转换成稠密向量。词向量中包含了大量的自然语言中的先验知识,word2vec 的成功证明了我们可以通过无监督学习获得这些先验知识。随后很多工作试图将句子、段落甚至文档也表示成稠密向量。其中比较有代表性的,比如:
- 有监督学习
- 无监督学习
等等。纯粹的有监督学习是通过分类任务去学习网络参数,最终得到句子向量表示。纯粹的无监督学习是通过预测上下文,比如 skip-thought 利用了 word2vec 的思想,通过预测上下文句子来学习句子表示。
本文要介绍的这篇论文则是首先尝试使用大规模无标注数据进行预训练,然后将整个句子的向量序列作为有监督任务的初始化值的方法。该方法开创了后来的与训练语言模型+微调下游任务的 NLP 模型训练模式。
1. Sequence autoencoders
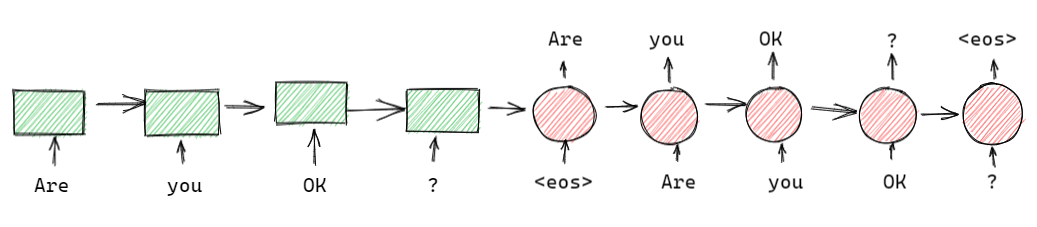
序列自编码器与机器翻译的 seq2seq 架构很相似,主要有两点不同:
- seq2seq 是有监督模型,序列自编码器是无监督模型
- seq2seq 输出是目标语言序列,而序列自编码器输出是输入的句子本身,所以叫做自编码器。
这个模型中,编码器(绿色部分)和解码器(红色部分)的权重是一样的。
序列自编码器的一个重要性质就是可以使用大量无标注的数据训练语言模型,这对有限标注数据任务非常有帮助。
2. Recurrent language models
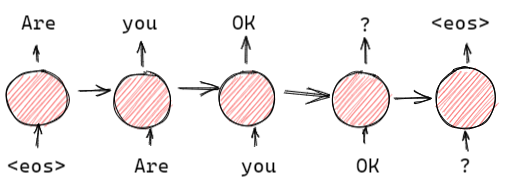
将序列自编码器,去掉编码器我们就可以得到 LSTM。在我们的任务中,我们使用序列自编码器对 LSTM 的权重进行初始化,我们将使用语言模型初始化后的 LSTM 称之为 LM-LSTM。
我们再将 LM-LSTM 用于下游的分类任务。通常情况下,LSTM 使用最后一个隐层的输出来预测输入的标签。但是在我们的实验中也尝试了使用 LSTM 每一步输出线性递增组合的方式预测标签,这样我们可以将梯度传递到更靠前的位置上,减轻梯度消失带来的问题。
另外,我们还尝试了将序列自编码器和下游监督学习模型一起训练的方法,称之为“联合训练”。
3. Experiments
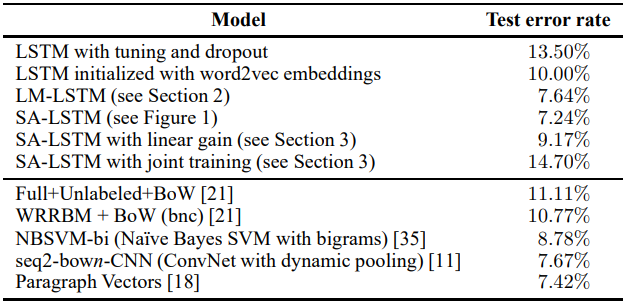
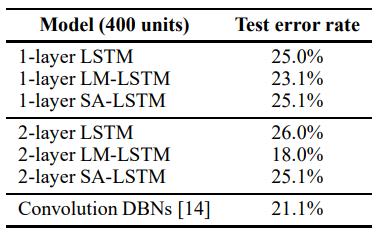
IMDB 数据集实验结果
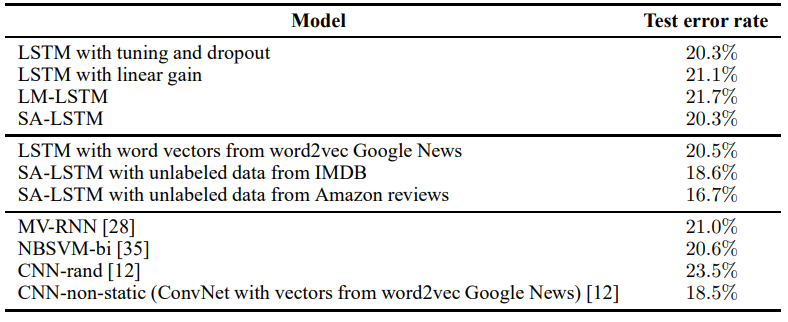
Rotten Tomatoes 数据集实验结果
20 newsgroups 数据集实验结果
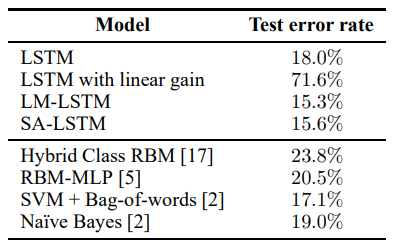
DBpedia character level classification
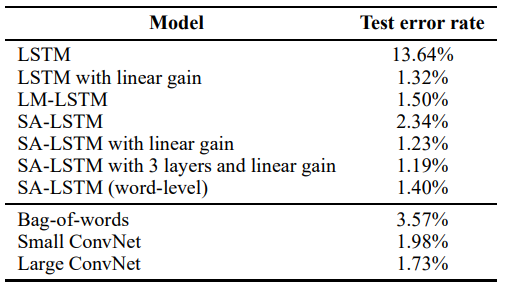
CIFAR-10 object classification
Reference
- Semi-supervised Sequence Learning, Andrew M. Dai, Quoc V. Le, 2015, arxiv:1511.01432
- Semi-supervised Sequence Learning, PaperWeekly, Zhihu