
1. 什么是本体?
“本体”(ontology)的概念来源于哲学对本体论的研究。随着人工智能(AI)的发展,科学家们将“本体”这一概念引入到计算机领域。不同的文献对本体有着不同的定义,甚至有些定义是相互矛盾的。为了方便起见,我们将本体定义为:本体是一系列词汇,这些词汇包括机器可读的概念定义和概念之间的关系。
- Classes: 类别,或者概念(concepts)表示具体领域内的一些抽象概念,比如“酒”,“人”等。Class 是本体的核心。
- Subclasses:表示,大类别下面的子类。比如“酒”的子类包括“白酒”、“红酒”等。
- Instances:实例,表示抽象概念下的具体事物。比如“白酒”的实例包括“红星二锅头”、“飞天茅台”等。
- Properties:属性,表示的是概念的不同特征和属性。OWL 中的 property 实际上表示的就是关系。主要包括两种关系:object property 和 data property 。Object property 表示两个实体之间的关系,比如小明和小红是兄妹关系,其中“兄妹”就是“小明”和“小红”两个实体的 object property;data property 表示实体属性,比如小明的年龄是12岁,其中“姓名”就是“小明”这个实体的 data property。除此以外, W3C 还规定了一种标注属性(annotation property),它表示一些实体的注释元信息,用来对实体进行注释说明。
- slots:槽,可以认为就是实体具体属性,比如“小明的年龄是12岁”,其中 “年龄” 就是一个 slot,而 “12岁” 就是 slot value。
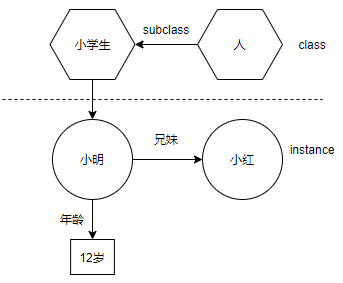
总结一下,本体需要包含以下要素:
- 定义本体类别
- 构建各类别之间的层级关系(父类 -> 子类)
- 定义 slot 以及可接受的值,比如年龄 slot 必须是数字
- 在实例中对 slot 进行填充
2. 为什么需要本体?
- 共享人类或者计算机理解的信息结构。假设多个的网页包含不同的医疗信息,如果这些网页能够共享相同的本体,那么计算机可以轻易从这些网页抽取有用信息提供给用户。不仅如此,计算机还可以聚合不同来源的信息,准确回答用户的问题。
- 领域知识的复用。举个例子,很多地方都会需要时间信息,包括时间段、时间点、相对时间等等。如果有人能够构建一个关于时间的本体,那么其他人就可以轻易将这个本体应用到自己的领域。另外,当我们自己构建本体的时候,也可以使用已有的本体知识在上面进行扩充或者缩减等。
- 明确领域假设。相当于我们将某一领域内的知识点利用一些假设关系相互串联起来,使我们对整个领域有更加清晰准确的认识,尤其是对一些新人。
- 将领域知识与可操作性的知识分离。这就有点类似于我们在设计一款产品的时候,我们将具体的产品和组件分离开来(模块化)。比如手机,多年前的手机充电器,基本上是一个品牌甚至同一个品牌的不同型号手机就有一个充电器,充电器不同共用,相当于手机和充电器是深度绑定的。后来为了解决这种深度绑定带来的各种问题,业内开始制定统一标准实现充电器与手机分离,一个充电器可以使用不同的充电器,而一个充电器可以给不同的手机充电。其中充电器标准就可以认为是领域知识本体,而手机就是可操作数据。
- 领域知识分析。当我们要复用和扩展领域知识的时候,这些领域知识元素就会变得非常有价值,说白了其实还是避免重复造轮子。
通常定义领域的本体并不是我们的最终目的。开发本体类似于定义一组数据及其结构以供其他程序使用。 解决问题的方法、独立于领域的应用程序和软件代理使用从本体构建的本体和知识库作为数据。 例如,在本文中,我们开发了葡萄酒和食物的本体以及葡萄酒与膳食的适当组合。 然后,该本体可以用作一套餐厅管理工具中某些应用程序的基础:一个应用程序可以为当天的菜单创建葡萄酒建议或回答服务员和顾客的查询。 另一个应用程序可以分析酒窖的库存清单,并建议扩展哪些葡萄酒类别以及为即将到来的菜单或食谱购买哪些特定的葡萄酒。
3. 如何构建本体?
现实中,并没有一个标准的、统一的本体构建方法。本文只是讨论一种比较通用的方法:先构建比较粗糙、大粒度的本体,然后不断的迭代细化。
在详细介绍构建本体的流程之前,我们先强调本体设计时的一些规则,虽然看起来有些教条,但是在很多情况下这些规则确实能帮助我们。
- 没有一个标准的、统一的本体构建方法。最好的方法就是根据实际业务需求去构建。
- 本体构建是一个需要不断迭代的过程
- 本体中的概念和关系必须是一些比较相近的对象(无论是物理上还是逻辑上)。这些对象可能是某领域内描述性句子中的名词或者动词。
接下来,我们以构建酒类和食物领域的本体为例,介绍构建本体的方法。
3.1 第一步、确定本体的领域和范围
构建本体的第一步是确定领域和范围,因此我们需要回答下面几个问题:
- 我们要构建什么领域的本体?
- 这些本体用来做什么?
- 这些本体可以回答什么问题?
- 谁会使用这些本体?
在本体设计过程中,这些问题的答案可能会发生变化,但是任何时候这些问题都可以帮助我们限定本体范围。
考虑酒类和食物的例子。首先我们已经确定要构建酒类和食物的本体了,我们的目的是用这些本体来推荐一些好的食物和酒的搭配。
那么显然,不同酒类的概念,食物类型的概念,以及酒和食物的搭配就必须包含在我们的本体中。同时,在我们的本体中不太可能包括管理酒厂库存或餐厅员工的概念,即使这些概念与酒和食物的概念有些相关。
如果我们的本体是用来帮助酒类杂志文章进行自然语言处理,那么词性、同义词等自然语言信息可能就会变得非常重要。如果本体用于帮助餐厅顾客决定订购哪种酒,我们需要包括零售定价信息。如果用于酒品买家储存酒窖,则可能需要批发定价和可用性信息。如果本体描述语言不同于本体用户语言,我们可能需要提供语言之间的映射。
能力问题(competency questions)
确定本体范围的方法之一就是勾勒出基于本体的知识库能够回答的问题(Gruninger and Fox 1995)。这些问题能帮助我们确定我们是否有足够的信息去回答这些问题,本体粒度都不够,覆盖的范围全不全。只需要一些大致的问题即可,无需穷举。
在我们的例子中,我们可能包含以下能力问题:
- 当我挑选酒品的时候应该考虑什么?
- Cabernet Sauvignon 适合搭配海鲜吗?
- 什么酒与烤肉最配?
- 酒类的哪些特点会影响与食物的搭配?
- 特定的酒的香气或者酒本身会随着时间发生变化吗?
- Napa Zinfandel 最好的年份?
从上面的问题中可以总结出,在我们的本体中石少应该包含:不同酒的特点、酒的类型、年份(及其品质的好坏)、食物分类以及酒和食物的搭配。
3.2 第二步、现有本体的复用
程序员的圣经之一就是“不要重复造轮子”。查找已有的可用本体是一件非常重要的事情。网上有很多相关的资源,下面列举一些比较重要的资源(大多是英文的资源,中文开放本体资源目前还比较少):
OpenKG
OpenKG是最大的中文开放知识图谱库,其中包含了很多本体。
Protege Ontology Library
地址:https://protegewiki.stanford.edu/wiki/Protege_Ontology_Library
Ontolingua ontology library
DAML ontology library
UNSPSC
RosettaNet
DMOZ
实际上现在确实有酒类开放实体可用,但是我们假设不存在,从头构建一个酒类本体。
3.3 第三步、枚举本体中的重要对象
当提到一个对象的时候你会讨论些什么?这些对象有什么属性?关于这个对象你会说些什么?思考这些问题对我们构建本体是非常有用的。我们可以把这些对象写成一个列表记录下来,比如提到“酒”,你会想到“葡萄”、“酿酒厂”、“原产地”、“酒的颜色”、“口感”、“含糖量”、“酒精含量”等等。而提到“食物”,我们通常会想到“鱼”、“虾“、”肉“、”蛋“、”奶“等等。起初,对于对象的一个综合理解更重要,无需过于关注概念和关系之间的相互覆盖。
3.4 第四步、定义类和类的层级结构
有几种不同的方法定义类的层级结构(Uschold & Gruninger 1996):
- 自上而下的方法是先定义领域内最通用的顶层概念,然后依次向下扩展。比如,我们先定义两个类别:“酒”和“食物”。然后定义酒的子类:白酒、红酒、玫瑰酒等等。然后对红酒进一步分类:Syrah,Red Burgundy,Cabernet Sauvignon 等等。对“食物”也是如此。
- 自下而上的方法是先定义一些具体的类别,然后讲这些类别聚合成更加通用的类别。比如“衡水老白干”和“红星二骨头”可以聚合成“白酒”。另外,“拉菲”,“桃乐丝”可以聚合成“红酒”。而“白酒”和“红酒”可以聚合成“酒”。
- 上下结合的方法是先定义一些比较重要的类,然后向上聚合和向下扩展。相当于将上面两种方法结合在一起。
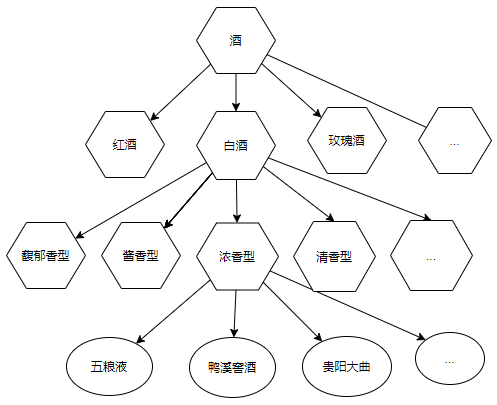
这三种方法中,没有一种是一定比其他两种更好的方法。最终采取哪种方法取决于开发人对领域的认知。如果开发人员对领域有着系统性的了解,那么采取自上而下的方法应该是首选。通常对于大多数的开发人员来说,上下结合的方法是比较适合的,因为多数人对领域都是有一定的了解而又了解不深。所以可以通过先构建一些比较通用的本体,然后再从实例中进行总结向上补充的方法会比较合适。
比如,多数人都知道酒可以分成“白酒”、“红酒”、“鸡尾酒”等,经常看广告也可以知道“白酒”有“酱香型”、“浓香型”对于其他的香型不太了解。而对于具体的酒进行总结归类,就可以发现,原来“酒鬼酒”是馥郁香型的,那么我们就可以将“馥郁香型”补充到酒类香型的层级上去。
无论是那种方法,都是从定义类开始的。第三步中,我们列举出了一些对象,现在我们可以从列表中的选择那些用于描述独立存在的对象作为类别,以这些对象作为锚点构建层级关系。一个重要的假设如下:
如果类别 A 是类别 B 的父类,那么属于 B 类的所有实例也同样是类别 A 的实例。
3.5 第五步、定义类的属性——slots
单纯的类别不足以为回答能力问题提供足够的信息,一旦我们用以上的方法定义了类别之后,需要为这些类别提供额外的信息,比如酒的颜色、口感、含糖量、产地等。这些信息就是类别的属性。
通常,一下集中类型的对象可以成为本体的属性:
- 内秉属性,比如:颜色、口感、含糖量等;
- 外部属性,比如:产地、酒名等;
- 子结构,如果一个对象是结构化的,那么它的实体结构和抽象结构都可以成为它的属性;
- 与其他对象的关系。比如,酒的厂家、酒的原料等。
所有子类都要继承父类的属性。比如“酒”的属性包括“厂家”、“颜色”、“口感”、“含糖量”、“产地”等,那么“酒”的子类“白酒”也要继承这些属性。因此,定义 slots 的时候通常是附加在具有该属性的最顶级类别上。
3.6 第六步、定义 slots 的刻面
slots 的刻面包括 slots 基数、数据类型、定义域和值域等。比如酒的名称(name)是一个字符串类型的数据,酒厂生产(produces)酒,这些酒是具体的酒的实例,因此其对应的数据类型应该是实例(instance)。
基数(cardinality)
slot 基数定义了一个 slot 可以有多少个值。有些 slot 只能至多有一个值,而有些则可以有多个值。比如一种酒只能有一种颜色,却可以有多个产地。
有些系统会规定 slot 基数的最大值和最小值。最小值 N 表明该 slot 至少有 N 个值,比如葡萄酒的原料葡萄 slot 最小值为 1,表明该种葡萄酒的原料中至少包含一种葡萄。最大值 M 表明该 slot 最多有 M 个值。比如葡萄酒的原料葡萄 slot 最大值为 2,表明该种葡萄酒最多有两种不同品种的葡萄酿制而成。如果最大值最小值都是 1,说明这种葡萄酒就是 1 种葡萄酿制而成的。所有时候将最大值设置成 0 也是非常有用的,表明对于某些特定的子类没有任何值满足条件。
数据类型
数据类型定义了 slot 的数据类型。
- 字符串(string):最简单,最常用的数据类型。
- 数字(number):数值类型的 slot,比如年龄、价格等。
- 布尔型(boolean):yes 或者 no,true 或者 false 等
- 可枚举(enumerated):给定 slot 可取到的值的列表,比如酒的口味可以是 [“重”,“中等”,“清淡”] 中的任意一种,而不能超过这三种的范围。
- 实例类型(instance):slot 允许定义两个单独实体的关系,但是必须定义清楚哪些类别的实体是可以作为 slot 的值。比如“酒”这个类别,可以作为 “produces” 的值。
定义域和值域
允许使用实例类型作为 slot 的类别称之为值域,比如 “酒” 作为 “produces” 的 slot 值,“酒” 就是 “produces” 的值域。简单来说,就是 $x \rightarrow y$,其中 $y$ 的所有实例数据类型的取值就是值域。
而定义域就是 slot 描述的对象。比如 “酿酒厂”,“produces”,“酒”,其中 “酿酒厂” 就是定义域。是简单来说,就是 $x \rightarrow y$,其中 $x$ 的取值范围就是定义域。
确定定义域和值域的规则是相似的:
- 找到最通用的类或者最具代表性的类别;
- 另一方面,不要将定义域和值域定义得范围太大,定义域中所有的值都可以被 slot 描述,值域中的所有值应该是 slot 的潜在填充值。不要选择过于笼统的类别,而是应该选择涵盖所有填充值的类别。
比如,“酿酒厂”,“produces” 的值域不应该是所有“酒” 的子类(“白酒”,“啤酒”,“红酒”等),而直接就是“酒”。同时,也不应该将“酒”进一步泛化到 “THING”。
具体来讲:
如果 slot 的值域或者定义域包括一个类别以及该类别下的子类,那么将其子类全部删掉
比如,一个 slot 的值域包括“酒”和“红酒”,那么应该将“红酒”删掉,因为“红酒”是“酒”的子类。
如果 slot 的值域或者定义域包含了 A 类的所有子类,但不包含 A 类本身,那么值域应该只包含 A 类本身而不包括其子类。
比如,一个 slot 的值域是“白酒”、“红酒”、“啤酒”等,我们可以将值域设为“酒”本身。
如果 slot 的值域或者定义域包含类别 A 中除少数子类以外的所有子类,那么我们应该考虑将类别 A 本身进行重新定义。
将一个 slot 挂在到一个类别上,和将该类别设为 slot 的定义域是完全等价的。一方面,我们应该尽可能泛化,另一方面我们应该保证 slot 对应的类别确实有相应的属性。总之一句话,我们既要一个都不差,也要避免张冠李戴。
3.7 第七步、构建实例
最后一步就是根据我们建立的类别层级结构构建实例。定义一个实例需要:
- 选择一个类别;
- 创建该类的单一实例
- 填充 slot 值
比如,我们创建一个 飞天茅台 的实体用来表示 “白酒” 的实例。它的属性如下:
酒精度:53%
颜色:无色透明
香气:幽雅细腻
口味:回味悠长
产地:贵州省仁怀市
生产商:贵州茅台酒股份有限公司
4. 定义类别和类别层级结构
本节讨论定义类别和类别层级结构时需要注意的点和容易出现的错误。对于任意领域来说都没有一个唯一正确的层级结构。我们所定义的层级结构依赖于我们要怎样使用本体,应用中必要的细节,个人喜好以及有时候可能还需要与其他模型进行兼容。但是我们还是要讨论一些开发层级结构时的一些指南,当我们开发完新的层级结构以后,回过头重新审视我们的定义是否满足这些指南,可以帮助我们避免很多错误。
4.1 保证类别层级结构的正确性
“is-a” 关系
如果类别 A 中的所有实例同时也是类别 B 的实例,此时我们就说类别 A 是类别 B 的子类,我们就可以定义关系(A,is-a,B)。比如,(“茅台酒”,“is-a”,“白酒”)。另一个也可以表示这种关系的是 “kind-of”,(“茅台酒” ,“kind-of”,“白酒”),(“肉”,“kind-of”,“食物”)等等。
单一的酒不是所有酒的子类
一个常见的错误是,在层级结构中包含同一个概念的单数版本和复数版本,然后令单数版本是复数版本的子类。比如,定义 “wine” 是 “wines” 的子类。然而这种关系是错误的。为了避免这种情况发生,在给类别命名的时候最好都采用单数形式或者都采用复数形式(第六节中讨论类别命名)。
层级关系的可传递性
满足以下条件的关系是可传递的:
如果 B 是 A 的子类,C 是 B 的子类,那么 C 也是 A 的子类。
比如,我们定义一个类别是 “酒”,然后定义 “白酒” 是 “酒” 的子类。然后再定义 “茅台酒” 是 “白酒” 的子类。那么可传递性表示 “茅台酒” 也是 “酒” 的一个子类。有时候我们会区分直接子类和间接子类。直接子类表示在层级结构中两个类别之间没有其他子类,即某一类别与其父类直接相连。而间接子类就是需要一个中间子类再与父类相连。实际上该子类也是中间父类的直接子类。
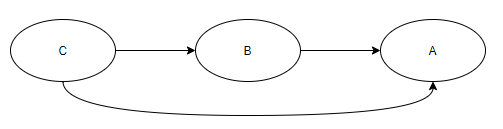
类别层级结构的演化
随着定义域的变化,要维护一个不变的层级结构可能会是一件很困难的事。比如通常我们见到的 “茅台酒” 是无色透明的,所以我们将 “茅台酒” 定义为 “白酒” 的子类。但是有可能在未来的某一天,酒厂发明了一种新的酿酒技术使得酒变成了黄色或者红色。此时,我们再将 “茅台酒” 归类到 “白酒” 里面可能就不太合适了。(这个例子实际上并不是很典型,一个比较典型的例子是组织结构的本体。组织结构的变动是很频繁的,一些部门今天还在,明天可能就取消了。)
类别及其名字的区别
区分类别和它的名字是至关重要的,通常也很难被注意到。
类别代表的是某一领域内的概念本身,而不是代表这个概念的几个单词。
我们选择的术语不同,其类别名就会发生变化,但实际上不同的术语表示的是同一个概念。比如 “克劳修斯表述”,“开尔文表述”,“熵增定律” 等等虽然名字不同,但都表示 “热力学第二定律” 这一概念。只是各自的名字不同罢了。再比如 “飞人乔丹”,“乔帮主” 都可以表示 “迈克尔·乔丹” 这个概念。
现实情况下,我们应该遵循以下规则:
表示相同概念的同义词不可代表不同的类别
同义词仅仅是相同概念的不同术语而已,因此,我们不能使用同义词来命名不同的类别。很多本体系统允许将同义词与表示类别名称相关联。比如,我们可以定义 “same_as” 关系,将“熵增定律”、“克劳修斯表述”和“开尔文表述”都关联到“热力学第二定律”上。如果不允许这种关联,则应该在类别文档中列出同义词。
避免类别套娃
类别层级结构中的循环指的是,类别 A 是类别 B 的子类的同时,类别 B 又是 类别 A 的子类,即两个类别互为子类和父类。是在构建层级结构的时候,我们应该避免出现这种情况。一旦出现这种情况就说明 A 和 B 是等价的:A 的所有实例也是 B 的实例,同时 B 的所有实例也是 A 的实例。
4.2 分析同级类别
- 层次结构中的同级类别
同级类别(siblings)指的是具有相同直接父类的类别。
除了根节点,所有同级类别必须处于同一层。
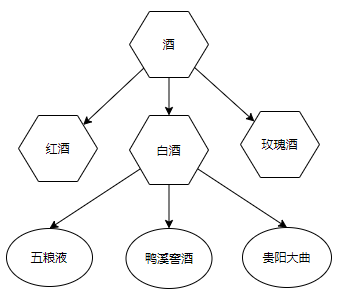
如图所示,“红酒”、“白酒”、“玫瑰酒” 同级别,“五粮液”、“鸭溪窖酒”、“贵阳大曲” 是同级别。
- 多少是太多?多少是太少?
并没有一个硬性指标规定一个类别至少应该有多少个直接子类。但是很多结构比较规范的本体中的类别通常有 2 个到 12 个直接子类。因此,我们可以有以下经验:
如果一个给定类别只有一个直接子类,可能是本体建模有问题,或者本体不完全;
如果一个给定类别的子类过多(超过 12 个),可能需要一些中间类别重新归类
比如上图,如果我们构建的本体,“酒” 只有 “白酒” 一个直接子类,说明我们丢了 “红酒”、“玫瑰酒”等其他酒品。而如果把所有白酒都挂到 “白酒” 下面可能说明,我们对 “白酒” 的分类过于粗糙。因此,我们可以对 “白酒” 再进一步细分成 “酱香型”、“浓香型”、“清香型”等等。然后,再将对应的白酒挂上去。
4.3 多继承
大多数知识表示系统都允许多继承:一个类别可以同时是多个类别的子类。比如,“啤酒”既可以是 “酒” 的直接子类,也可以是 “食物” 本体中 “调味料” 的直接子类。因此,“啤酒” 可以有两个父类:“酒” 和 “调味料”。“啤酒” 的所有实例同时也是 “酒” 和 “调味料” 的实例。当然,“啤酒” 也会同时继承 “酒” 和 “调味料” 的一些属性。
4.4 什么时候应该(不应该)引入新的类别?
本体构建最难的部分应该就是什么时候引入新的类别,或者什么时候通过不同的属性值加以区分。也就是说,对于一个新的对象,我们是把它归到已有的类别然后给予不同的属性,还是新建一个类别?如果新建过多类别,会造成类别过多,甚至会出现彼此嵌套。而如果是新加属性加以区分的话 ,又会造成属性过于复杂。如何找到一个平衡点并不容易。
为了寻找这样一个平衡点,我们可以设定一些规则:
一个子类通常需要满足以下条件之一:
- 有一些父类不具备的属性;
- 与父类的限制条件不同;
- 与父类参与的关系类型不同
比如,“烤肉” 有一个属性 “几分熟”,但是其父类 “肉” 通常不会有这个属性。或者 “白酒” 的颜色限制为 “无色透明”(或者 “微黄透明”),而 “酒” 没有这个限制。换句话说,当我们想要描述的对象无法通过父类来描述的时候,就需要定义新的子类。
实际情况下,每个子类都应该有新的 slot,或者有新的 slot 值,又或者要覆盖原有的继承自父类的刻面。
有时候,没有新的属性的时候也可以引入新子类:
术语层级结构不需要引入新的属性
比如,电子病历系统基础的本体可以包括对各种疾病的分类。这个分类可能只是没有属性(或者有相同属性集)的术语层级结构。比如,“糖尿病”、“心脏病”、“高血压” 都是不带属性的,但是我们还是应该将这些术语分成不同的类,而不应该看成属性。
另一个无新增属性而要新建类别的情况是——约定俗成。某些领域内的对象,在领域专家眼中通常是区分对待的,我们构建的本体系统应该反映出领域专家对该领域的看法。因此,这种情况下,还是需要新增子类。
最后,我们不应该为每个附加的限制创建一个子类。比如,我们可以构建 “红酒”、“白酒”、“玫瑰酒” 的分类,但是不能构建 “扬州酒”、“贵州酒”、“法国酒” 等,单独根据产地属性的类别。
4.5 新的类别或者属性值?
当我们对一个领域进行建模的时候,通常需要考虑将某些对象定义为属性还是类别的问题。
我们是要定义 “白酒”、“红酒” 作为 “酒” 的子类,还是要将 “白酒”、“红酒” 作为 “酒” 的 “颜色” 属性值?这通常取决于我们构建的本体的范围。“白酒” 在你的领域内重要性如何?如果 “白酒” 只是为我们提供一些边缘信息,或者与其他对象没有很重要的关系,那么我们就不应该将 “白酒” 作为一个类别来对待。
如果有不同 slot 的概念会变成其他类别的不同 slot 的限制,那么我们应该新建一个类别。否则我们就在属性中加以区分即可。
换句话说就是,如果 slot 的值发生了变,会使得类别也发生变化的话,那么我们应该新建一个类别。
比如,“红啤”、“白啤”、“黑啤” 等,这几种酒确实不是同一种酒。
如果领域内对对象的区分非常重要,并且我们将具有不同值的对象视为不同种类的对象,那么我们应该创建一个新类
同时我们还应该注意:
一个实例所属的类别不应该时常发生变动
通常情况下,当我们用外部属性而不是内秉属性来划分类别的时候,实例所属的类别经常会发生变化。比如,“热牛奶” 和 “常温牛奶” 并不应该分成两个类别,而是应该把温度设置成 “牛奶” 的属性。
另外,数字、颜色、地点通常应该是属性而不是类别。但是,对于 “酒” 来说,颜色应该是一个很重要的分类标准,所以在 “酒” 的分类中颜色应该属于类别而不是属性。
另一个人体解剖学本体的例子。当我们表示 “肋骨” 的时候,是否应该将肋骨分成 “左侧第一根肋骨”、“左侧第二根肋骨” 等?或者我们将肋骨的顺序和位置当成属性?如果在我们的本体中每根肋骨承载的信息非常不同的话,我们么确实应该为每根肋骨构建一个类别。比如,如果我们想要对肋骨不同位置的邻接信息建模,以及运动过程中每根肋骨所起的作用,或者不同肋骨保护的不同器官等等,这时候我们就需要对每根肋骨新建一个类别。如果我们只是对人体解剖学进行大致建模,那么我们只需要构建一个 “肋骨” 的类别,然后把 “位置” 和 “顺序” 作为属性即可。
4.6 实例还是类别?
决定一个对象是类别还是实例,还是取决于我们构建的本体的潜在应用场景。类别结束实例开始的位置决定了本体的细节粒度。比如,“酸奶” 应该算是一个类别,还是实例?如果作为类别,它下面还有 “成都老酸奶”、“青海老酸奶” 等更细粒度的类别,如果 “酸奶” 作为实例,那么就不需要区分 “成都老酸奶” 和 “青海老酸奶”了。
要确定本体的细节粒度,可以回到本体构建步骤的第一步——我们想要利用这个本体回答什么问题?
知识库中,单实例是粒度最细的概念。
比如,如果我们关心的是是否易消化,那么 “酸奶”、“纯牛奶” 就可以作为实例,而如果还要考察 “酸奶” 的制作工艺,口味特点等。那么 “酸奶” 就需要成为一个类别。
另外,如果满足以下条件,则可以将实例转化成类别:
如果一个概念天然有层级结构,那么我们应该把它当成类别。
比如,“地球有七个大洲”,我们可以把 “七大洲”(“亚洲”,“欧洲”,…) 当成 “地球” 的实例,但是 “七大洲” 是由不同国家组成的。因此,通常我们把每个大洲作为类别,而不是实例。
需要注意的是,只有类别有值域。在知识表示系统中,不存在 “subinstance” 的概念。因此,如果我们还想对一个概念进行细分,即使概念本身没有任何实例,也要把它当成类别,而不是实例。
4.7 限制本体范围
本体系统不需要包括领域内所有的信息:我们不需要细化或者泛化超过实际需求的本体。
比如,如果我们的用处是酒和食物的单配,那么我们就不需要知道如何酿酒和如何烹饪。
本体系统不需要包含所有的属性以及不同类别之间的区别。
本体系统不需要包含所有的关系
4.8 无交集子类
如果两个类别的实例中没有公共实例,我们就认为这两个类别是无交集类别。比如 “红酒” 和 “白酒” 就是无交集类别:没有一种酒即是红酒又是白酒。在构建本体系统的时候,我们可以指定两个类别是无交集类别。指定无交集类别的好处是可以使本体更好进行验证——如果不指定的话,我们要看两个类别是否有交集还要将两个类别的实例全部读取出来,然后求交集看是否为空。不仅浪费空间还浪费时间。
同时,如果我们指定 “红酒” 和 “白酒” 是无交集类别的话,在进行建模的时候,如果创建了一个多继承子类,父类中包括了 “红酒” 和 “白酒”,那么系统可以很快识别出建模错误。
5. 定义属性——更多细节
本节主要讨论可逆属性和属性默认值。
5.1 互逆属性(slot)
一个 slot 的值可能依赖于另一个 slot 的值。比如,(wine,produced_by,winery)和(winery,produces,wine)这两个关系就是互逆关系。如果在本体系统中将两个关系都存下来,会显得整个本体冗杂。当我们知道某种酒的生产厂家是某某某的时候,我们就可以推断出某某某厂家生产了某种酒。从知识获取的角度来说,明确这种互逆关系对知识获取来说是很方便的。知识获取系统可以自动填写互逆关系的值,以确保知识库的一致性。
比如,当我们明确了 “produced_by” 和 “produces” 是互逆关系之后,当我们填写了 “茅台酒 produced_by 贵州茅台酒股份有限公司” 以后,系统可以自动填写 “贵州茅台酒股份有限公司 produces 茅台酒”。
5.2 默认属性值(slot value)
许多基于框架的系统允许指定默认属性值。如果多数实例的特定属性是相同的,那么我们可以给这个属性指定一个默认值。然后,每次往该类别下添加有该属性的实例的时候,系统可以自动填充属性值。如果我们默认的属性值与该实例的实际属性值不符,我们还可以手动修改。
比如,如果多数白酒都是 53° 的,那么我们在 “酒精度数” 中可以默认为 53°。如果有些白酒不是 53°,还可以手动改成其他度数。
需要注意的是,默认属性值与属性值是不同的,默认属性值是可以修改的,而属性值是不可修改的。即如果我们定义了 “白酒” 的酒精度是 53°,那么所有 “白酒” 的子类和实例的酒精度都是 53°,这个度数在任意子类和实例中都不可修改。
6. 名字包含什么?
本节讨论对概念命名规则,主要集中在英文名称中会出现的一些问题,比如大小写、分隔符、单复数等。这些问题在中文中都基本不会出现。但是就个人而言,还是建议使用英文进行知识建模。众所周知,现在很多系统对中文的支持并不是十分友好,使用中文建模的话很可能出现各种意想不到的问题,因此,能用英文建模的就尽量使用英文建模吧。
为本体中的概念设定一些命名规则,不仅可以使本体更容易理解,还能够帮助我们避免一些常见的建模错误。命名方法有很多,实际应用的时候可以选择合适的方法。但是,我们要:
定义一种类别和属性的命名规范,然后遵守它。
在知识表示系统中,我们可以考虑以下特征用于对概念进行命名:
- 本体中是否存在同名的类别、属性、实例?比如 “酿酒厂” 既是类别又是属性?
- 本体系统大小写敏感吗?比如,系统是否人为 “Wine” 和 “wine” 是同一个概念?
- 名称中允许出现什么样的分隔符?空格、逗号、星号等等?
6.1 大小写与分隔符
首先,如果我们在本体中保证概念名称的大小写一致性能够大幅提升本体的可读性。比如,通常的做法是大写类别名称,小写属性名称(假设大小写敏感)。
当概念名称中有不止一个词的时候,我们需要在词与词之间添加分隔符。通常分隔符有以下几种选择:
- 空格
- 词与词之间没有分隔符,而是将每个词的首字母大写,比如 “MealCourse”
- 使用下划线或者连接符,比如 “meal_course”,“meal-course” 等
在使用空格的时候,需要考虑你所使用的本体建模工具是否支持空格,以及你构建出来的本体是否会与其他本体系统交互使用,如果有交互,需要交互的本体系统是否支持空格。因此,虽然用空格作为分隔符更符合人类的习惯,但是需要考虑的因素比较多,更建议使用后两种方案。
6.2 单数还是复数?
一个类别的名称代表的是一些列对象的集合。所以,建议使用复数作为类别的名称。但是无论使用单数还是复数,都要在整个本体中保持一致,不要出现在这里是单数,淡了另一处就变成了复数。甚至有些本体建模工具会要求用户指定概念名称的单复数。
6.3 前缀和后缀的规则
有些知识库会建议使用前缀或者后缀还区分类别名和属性名。属性名中常用的两种前缀或者后缀:“has-” 或者 “-of”。比如 “has-maker” 或者 “*maker-of”。通过这种方式区分类别名和属性名可以提高可读性。
6.4 命名中的一些其他考量
- 不要在概念名称中出现 “class”、“property”、“slot” 等词汇
- 避免使用缩写
- 对直接子类进行命名的时候,要么所有子类都包含父类的名称,要么都不包含父类的名称。不要出现有些子类包含父类有些不包含的情况。比如 “red wine” 和 “*white”
7. 其他可参考资料
- WonderTools? A comparative study of ontological engineering tools, Duineveld, A.J., Stoter, R., Weiden, M.R., Kenepa, B. and Benjamins, V.R. (2000).
- Knowledge sharing and reuse. Gómez-Pérez, A. (1998).
- Ontologies: Principles, Methods and Applications, Uschold, M. and Gruninger, M. (1996).
- Ontolingua tutorial. Farquhar, A. (1997).
- An Environment for Merging and Testing Large Ontologies. McGuinness, D.L., Fikes, R., Rice, J. and Wilder, S. (2000).
8. 总结
本文描述了构建本体的方法和步骤。讨论了构建过程中需要注意的问题。但是我们需要记住一点:
对于任意领域来说都没有一个唯一正确的方法
本体的构建是一个创造的过程,即使是以相同的目的和应用场景构建相同领域的本体,不同的人都会得到不同的本体。主要能满足我们的需求,就是好的本体。
Reference
Ontology Development 101: A Guide to Creating Your First Ontology. Natalya F. Noy and Deborah L. McGuinness