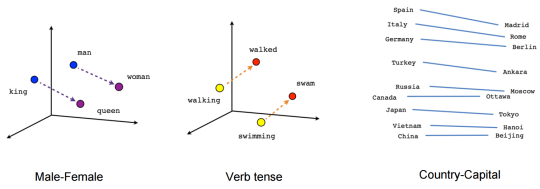
词嵌入(word embedding)是一种用稠密向量来表示词义的方法,其中每个词对应的向量叫做词向量(word vector)。词嵌入通常是从语言模型中学习得来的,其中蕴含着词与词之间的语义关系,比如 “猫” 和 “狗” 的语义相似性大于 “猫” 和 “计算机” 。这种语义相似性就是通过向量距离来计算的。
1. 简介
1.1 词表示法简史
自然语言文本在很长时间里并没有一个统一的表示法,用于计算机进行计算。通常人们给每个词分配一个 id,将词作为离散符号输入计算机系统。
查字典
最直接的方法是创建一个词表,每个词分配一个唯一的 ID,比如:
我, 0
是, 1
谁, 2
…
One-hot 编码
同样是先建立一个词表,然后给词表中的每个词分配一个大小为词表大小的向量来表示词。每个词对应的向量中,只有一个位置的数字为 1,其他位置上的数字全部是 0。词与词的 one-hot 向量两两正交。整个词表就是一个 $1\times (N+1)$ 的矩阵,其中 $N$ 表示词表大小,额外的 1 表示 UNK ,即不在词表中的词的统一标识。比如:
我,[1, 0, 0, 0, …]
是,[0, 1, 0, 0, …]
谁,[0, 0, 1, 0, …]
…
Distributional 表示法
以上两种方法存在着一下几个问题:
- 正交。词与词之间的语义丢失,我们没有办法从向量表示中得到词与词之间的关联性,
- 维度爆炸。通常一个词表会有几万个词,如果用 one-hot 表示,那么整个词表的 one-hot 就是一个几万乘几万的矩阵,极大地消耗了计算机资源。
- 矩阵稀疏。one-hot 矩阵中,除了特定位置上的数字是 1, 其余位置全部是 0,造成整个矩阵极端稀疏化,运算过程中极大地浪费了算力,
因此,人们提出了分布式表示法,希望通过稠密向量来获得词嵌入矩阵。而得到稠密向量的方法就是我们下面要介绍的。
1.2 发展里程碑
2003 年 Bengio 等人提出前馈神经网络语言模型(FFNNLM),该模型的一个重要副产物就是词向量。相当于提出了一种利用语言模型训练词向量的方法,同样为后来的 Word2vec 打下了基础。
Morin & Bengio 提出层级 softmax 思想。给定大小为 $V$ 的词表,通过一棵二叉树计算输出词的概率分布,将计算复杂度从 $O(V)$ 降到 $O(\log(V))$。这一思想成为后来 word2vec 模型的重要组成部分。
Gutmann & Hyvarinen 提出噪声对比估计(NCE)方法。其基本思想是:一个好的模型可以利用逻辑回归从噪声中识别有用数据。后来 NCE 被 Mnih &Teh 用于语言模型。后来 Word2vec 中的负采样技术就是 NCE 的简化版。
Mikolov 等人提出 word2vec 模型,使得大规模训练词向量成为现实。Word2vec 包含两个模型:skip-gram 和 CBOW。为了加速计算,word2vec 将 softmax 替换成层级 softmax,二叉树用的是哈夫曼树(Huffman tree)。
Mikolov 等人对原来的 word2vec 模型进行了优化,提出负采样的方法。负采样是噪声对比估计的简化版,比层级 softmax 更简单、更快。
Pennington 等人基于词共现的方法,提出另一种训练词向量的方法:Glove。与 word2vec 相比,两个模型表现相差不大,而 GloVe 更容易并行化训练。
接下来我们介绍两种主要的训练词嵌入的方法:
- Context-based:给定上下文,设计模型预测中心词。
- Count-based:统计文本中词的共现矩阵,然后利用矩阵分解的方法对矩阵进行降维。
2. Context-based: Word2Vec
2013 年 Mikolov 等人提出一种模型 —— Word2Vec。该模型包含两种架构:Continuous Bag-of-Words(CBOW) 和 Continuous Skip-gram(Skip-gram),然后在随后的文章中提出了两种模型训练的优化方法:hierarchical softmax(层级 softmax) 和 negative sampling(负采样)。Mikolov 等人不是第一个提出连续向量表示词的人,但是他们提出的 word2vec 模型是第一个能应用在大规模语料上的模型,具有非常重要的意义。
假设有一个固定大小的滑动窗口,沿着句子从头到尾滑动取片段,每个窗口中中心词即为目标词(target),其他的词为上下文(context)。举个例子(假设已经分词):
天才 就是 百分之一 的 灵感 加 百分之九十九 的 汗水。
| 滑动窗口(size=5) | target | context |
|---|---|---|
| [天才, 就是, 百分之一] | 天才 | 就是, 百分之一 |
| [天才, 就是, 百分之一, 的] | 就是 | 天才, 百分之一,的 |
| [天才, 就是, 百分之一, 的, 灵感] | 百分之一 | 天才, 就是, 的, 灵感 |
| … | … | … |
| [灵感, 加, 百分之九十九, 的, 汗水] | 百分之九十九 | 灵感, 加, 的, 汗水 |
| [加, 百分之九十九, 的, 汗水] | 的 | 加, 百分之九十九, 汗水 |
| [百分之九十九, 的, 汗水] | 汗水 | 百分之九十九, 的 |
2.1 Skip-Gram Model
Skip-gram 模型的核心思想是通过中心词预测上下文,即:
Skip-gram 模型采用的是一个浅层神经网络来计算这个概率分布。该一共只有三层:输入层、投影层(隐藏层)、输出层。模型结构如下图:
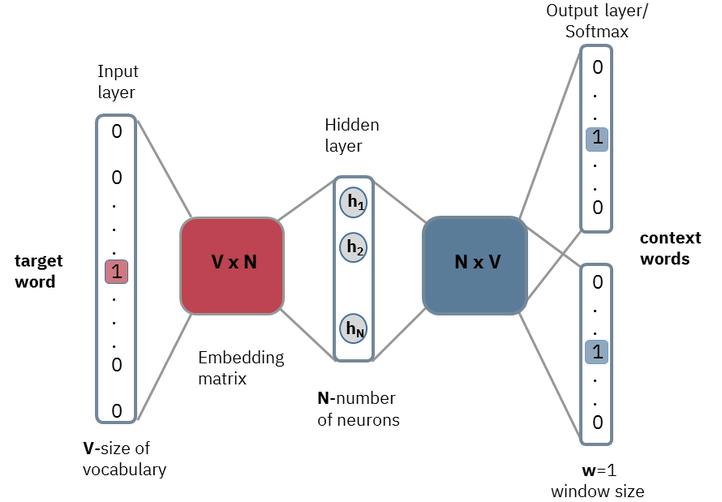
假设上下文中的词相互独立,则:
相当于训练样本的(target,context)对拆解成 $2m$个(target,context word)对,其中 $m$ 表示滑动窗口除中心词外一半大小(很多地方会直接把 $m$ 定义为窗口大小),context word 表示上下文中每个词。例如,中心词为 “百分之九十九”,那么训练样本就是:
(百分之九十九,灵感)
(百分之九十九,加)
(百分之九十九, 的)
(百分之九十九, 汗水)
此时,上面的模型结构则等效于下图:
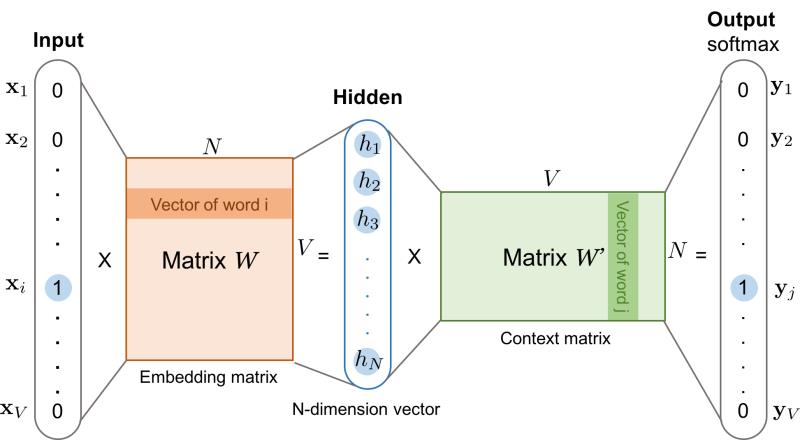
模型的输入是中心词,输出是上下文词之一。
假设词表 $\mathcal{V}$ 的大小为 $V=|\mathcal{V}|$,中心词在词典中的索引为 $i$,上下文对应的词在词表中的索引为 $j$, $N$ 表示词向量 $\boldsymbol{v}_i$ 的维度,即 $\boldsymbol{v}_i \in \mathbb{R}^N$。
关于模型的一些细节:
$\boldsymbol{x}$ 和 $\boldsymbol{y}$ 都是 one-hot 编码,编码中 $i$ 和 $j$ 对应的位置为 1,其余位置全部为 0,$\boldsymbol{x},\boldsymbol{y} \in \mathbb{R}^{1\times V}$。
首先,将输入 $\boldsymbol{x}$ 与一个 $\boldsymbol{W}$ 矩阵相乘得到隐藏层 $\boldsymbol{h}$,其中 $\boldsymbol{W}\in \mathbb{R}^{V\times N}$ ,则 $\boldsymbol{h}\in \mathbb{R}^{1\times N}$。实际上 $\boldsymbol{h}$ 相当于 $\boldsymbol{W}$ 的第 $i$ 行:
用 $\boldsymbol{h}$ 与另一个矩阵 $\boldsymbol{W’}\in \mathbb{R}^{N\times V}$ 相乘得到一个 $1\times V$ 的向量 $\boldsymbol{h’}$。
将 $\boldsymbol{h’}$ 进行归一化即可得到 $\boldsymbol{y}$ 的 one-hot 概率分布:
$\boldsymbol{y}$ 中概率最大的位置 $j$ 即对应词表第 $j$ 个词:
比如:
假设 $\mathcal{V}=[我,的,灵感,天才,…]$
$\boldsymbol{y} = [0.1, 0.2, 0.3, 0.2, 0.15, 0.05]$
$\boldsymbol{y}$ 中最大概率为 0.3,对应的索引是 2,即 $j=2$,
则 $w_j = \mathcal{V}_2 = 灵感$。
模型中有两个矩阵 $\boldsymbol{W}$ 和 $\boldsymbol{W’}$,非别对应着中心词的向量编码和上下文的向量编码。在自然语言处理应用中,一般使用中心词向量作为词的表征向量,即 $\boldsymbol{W}$ 就是我们最终得到的 word embedding。
2.2 CBOW Model
连续词袋模型(CBOW)模型与 skip-gram 模型正相反,CBOW 是利用上下文来预测中心词,即:
模型结构如下图所示:
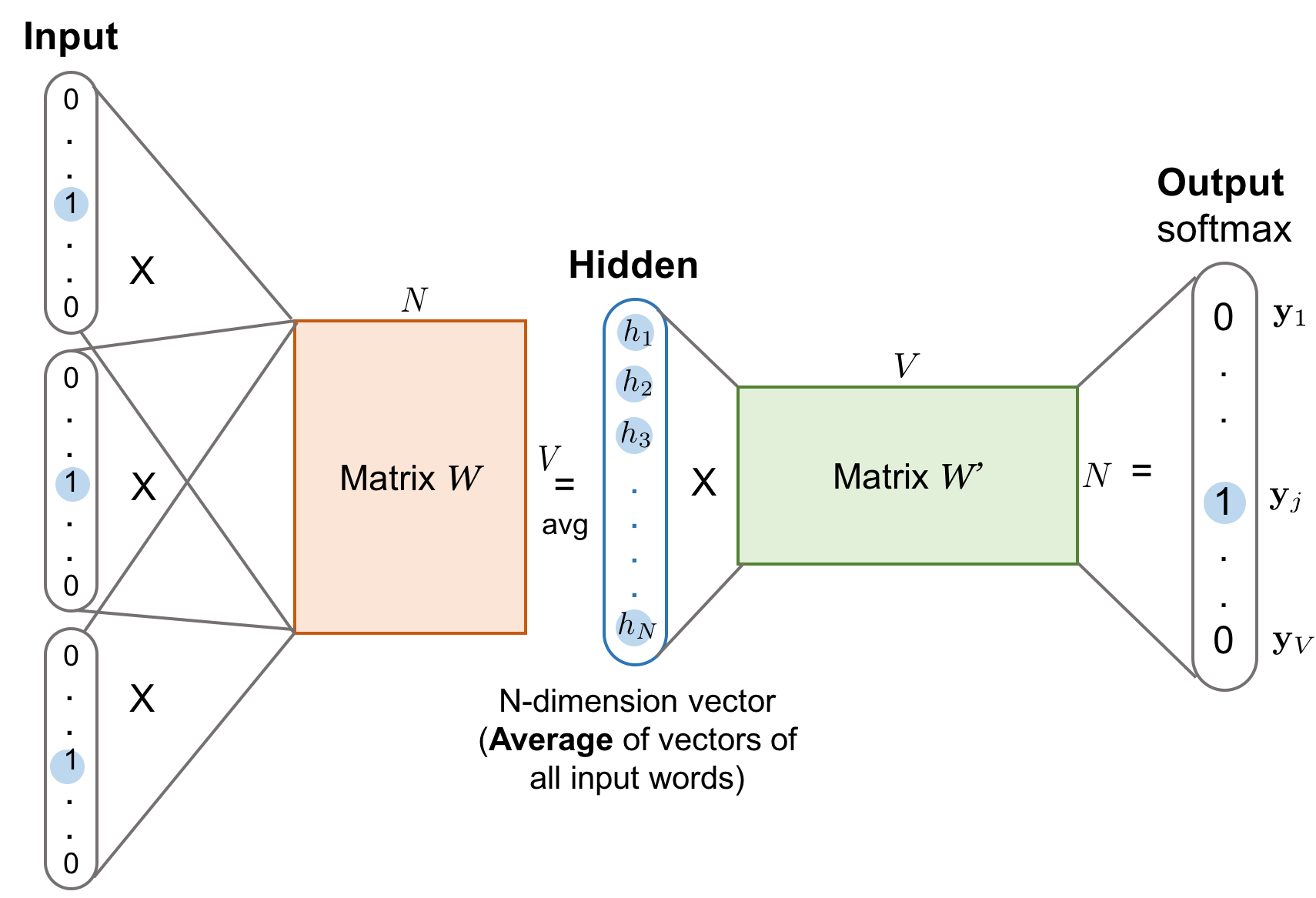
由于 CBOW 模型的输入有多个,所以我们将得到的 context 向量取平均,然后使用和 skip-gram 一样的方法来计算中心词的概率分布。
2.3 Loss/object Functions
无论是 skip-gram 模型还是 CBOW 模型,模型参数就是中心词向量和上下文词向量对应的嵌入矩阵 $\boldsymbol{W}$ 和 $\boldsymbol{W’}$。给定输入词 $w_I$ ,其在 $\boldsymbol{W}$ 中对应的向量为 $\boldsymbol{v}_I$(即 $\boldsymbol{h}$)。$\boldsymbol{W’}$ 中每一列对应的词向量为 $\boldsymbol{v’}_j$。输出词 $w_O$ 对应的词向量为 $\boldsymbol{v’}_o$。
通过最小化损失函数对模型进行训练,下面以 skip-gram 为例介绍一些常用的损失/目标函数。
2.3.1 标准 Softmax(Full Softmax)
用数学语言来描述上面的模型,即对于单个样本我们的目标函数为:
从上式可以看出,对于任意单一样本,我们都需要对全词表进行指数求和,然而当 $V$ 非常大的时候(实际情况下 $V$ 通常会有几万到几十万),计算将会变得非常复杂,根据 2.3.3 节关于交叉熵损失函数的介绍中,我们也可以看出进行后向传播的时候,计算过程同样是需要计算完整词表。因此,Morin and Bengio 等人在 2005 年的时候,提出了层级 Softmax,采用二叉树来加速计算。
2.3.2 层级 Softmax(Hierarchical Softmax)
由于标准的 softmax 的计算复杂度较高,所以人们就不断思考对其进行优化。2001 年 Goodman 提出基于分类思想的加速方案。简单来说,假设我们词表中有 10000 个词,在传统的方法是在这 10000 个词上做 softmax 获得每个词的概率分布,然后取出概率最大的词,这样我们需要计算 10000 次。如果我们将这 10000 个词进行分类,假设分成 100 个类别,每个类别 100 个词。这个时候我们的计算过程是,先用一个 softmax 计算下一个词是属于什么类别,然后再用一个 softmax 计算概率最大的类别中的词的概率分布,这样我们只需要两个 100 次的计算量,计算速度直接提升 50 倍。
基于这个思想,Morin & Bengio 于 2005 年提出层级 softmax 的方法:使用平衡二叉树来构建这种分类关系,能够将计算复杂度降到 $O(\log_2(|\mathcal{V}|))$。由于他们利用的是先验知识(wordnet 中的 is-a 关系)来构建二叉树,最终的而效果并不理想。随后 Mnih & Hinton 采用 boostrapping 的方法,从一个随机树开始自动学习一棵平衡二叉树。
直到 2013 年 Mikolov 等人提出使用 Huffman 树来代替平衡二叉树,使得层级 softmax 在效果和效率上都达到了新的高度。
2.3.2.1 Huffman 树
Huffman 树是一个用于数据压缩的算法。计算机中所有的数据都是以 0 和 1 进行存储的,最简单的数据编码方式是 等长编码。假设我们的数据中有 6 个字母,那么我们要将这些字母区分开,就至少需要三位二进制数来表示,$2^3=8>6$,如果数据中的字符数更多,那就需要更长的二进制数进行编码。然而我们希望用尽可能少的二进制数对数据进行编码,尤其是实际生活中,有些字符使用频率非常高,另一些字符很少使用。我们希望使用频率高的字符编码长度更短,这样就可以节省存储空间了。所以这里就涉及到 变长编码。
比如,给定一个字符串 aabacdab,包含了 8 个字符,我们发现这个这个字符串中包含了 4 个不同的字符 a、b、c、d,分别对应的频率为 4、2、1、1。由于 a 的频率大于 b,b 的频率大于 c 和 d。所以,我们可以给 a 分配一个 1 位的编码长度,b 分配 2 位的编码长度,c 和 d 分配 3 位的编码长度:
1 | a: 0 |
所以,aabacdab 就被编码成了 00110100011011(0|0|11|0|100|011|0|11)。但是这个编码会有问题,那就是歧义性。因为我们不仅需要编码,还需要解码。当我们把数据存储到计算机以后,还需要从计算机中将数据读取出来。读取数据的过程就是解码的过程。如果我们用上面的编码进行存储解码的时候,会出现不同的解码方式:
1 | 0|011|0|100|011|0|11 adacdab |
为了避免解码歧义,我们需要保证编码满足 “前缀规则”:任意编码不能是其他编码的前缀。在上例中,0 是 011 的前缀,所以才会出现解码歧义性问题。
Huffman 树就是用来做这种变长编码的数据结构,构造过程如下:
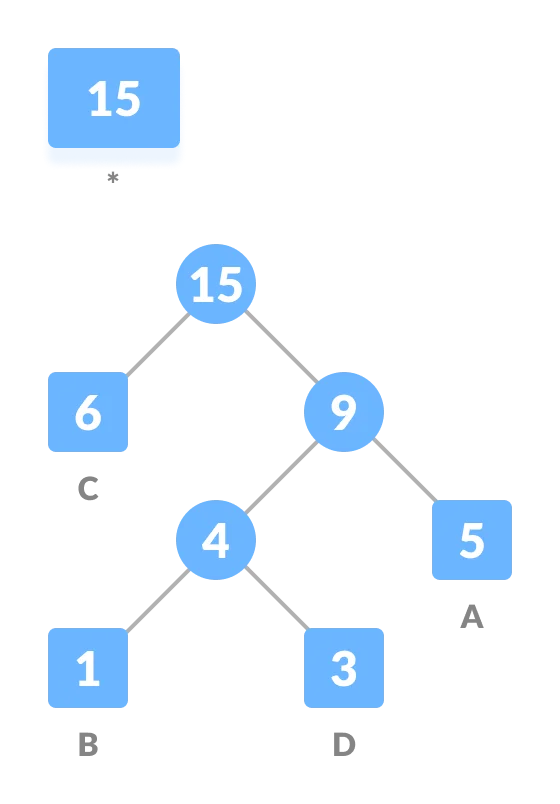
计算字符频率
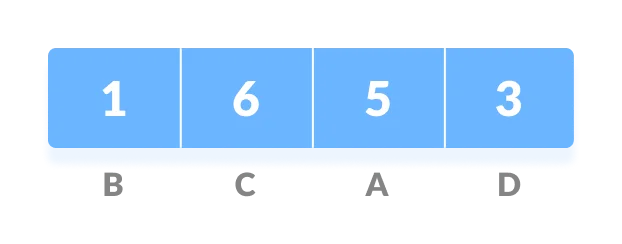
根据词频对字符进行排序,并按升序进行排列,得到序列
Q:
创建一个空节点
z。节点z的左子节点是频率最低的字符,右子节点是频率第二低的字符。节点z的频率为左右子节点字符频率之和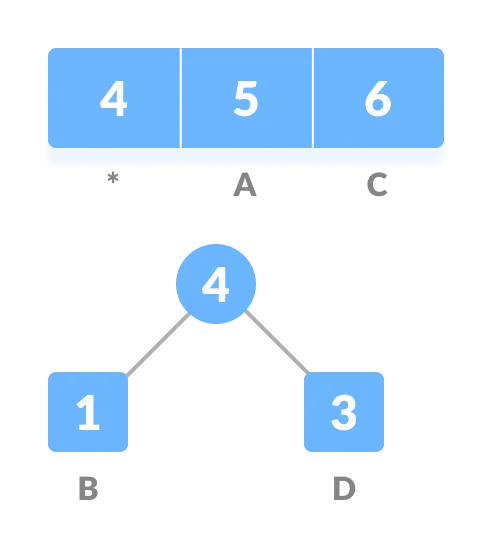
从
Q中删除两个上一步中两个频率最低的字符,然后将两者频率之和添加到Q中。重复 3-4 两步
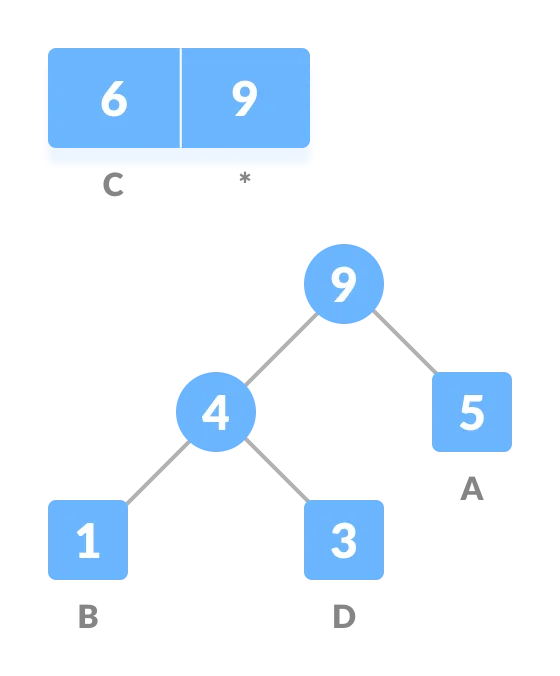
将左侧的边赋值为 0,右侧的边为 1。
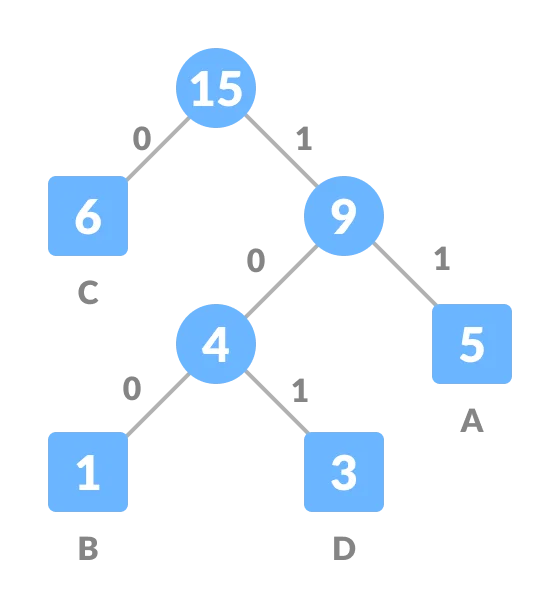
这样就构建好了一棵 Huffman 树。Huffman 编码就是找到从根节点到对应的字符之间的路径,然后将路径上的边对应的值拼接在一起。比如,上例中的 A、B、C、D 的编码分别为:11、100、0、101。
解码过程就是按照编码找到相应的路径:
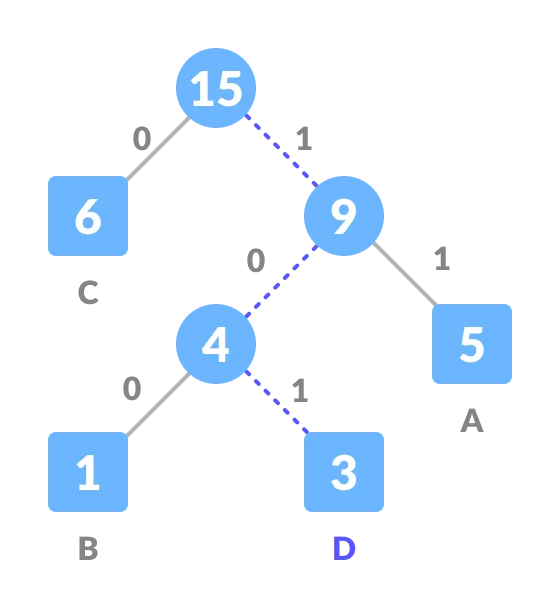
2.3.2.2 基于 Huffman 树的层级 softmax
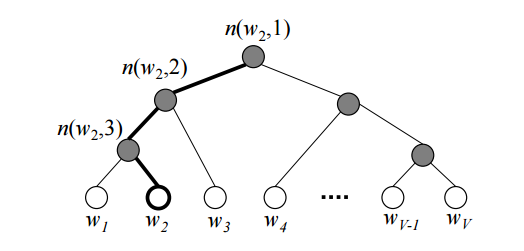
Word2vec 中是预先统计语料中的词频,根据词频构建起一棵 Huffman 树。
Huffman 树的每个叶子节点是词表中的一个词,每个除叶子节点和根节点以外的节点都表示一个二分类的概率,这个概率用来决定去往左右子节点的路径。
如上图所示,每个叶子结点(白圈)表示一个词表中的词 $w_i$,每个非叶子节点(灰圈)表示该路径上的概率。每个词都有一条唯一可达的路径,$n(w_i, j)$ 表示 $w_i$ 的路径上 第 $j$ 个节点。比如 $w_2$ 的路径就是 $n(w_2,1)n(w_2,2)n(w_2,3)w_2$。这条路径就对应 Huffman 编码。$w_2$ 的概率就是这条路径上每个节点的概率累积:
其中 $L(w_O)$ 表示 $w_O$ 的路径长度(Huffman 编码长度)。由于这是一个二叉树,相当于 $p(n(w_O,j))$ 是一个二分类,所以可以使用 $\sigma$ 函数进行计算:
其中 $v’_{n(w_O,j)}$ 表示 $n(w_,j)$ 节点对应的向量,$\mathbb{I}_{\text{turn}}$ 表示特殊的标识函数:如果 $n(w_O,j+1)$ 是 $n(w_O,j)$ 的左子节点,则 $\mathbb{I}_{\text{turn}}=1$ ,否则为 $\mathbb{I}_{\text{turn}}=-1$。比如,上图中,我们要计算 $w_2$ 的概率:
内部节点的向量 $\boldsymbol{v’}_{n(w_i, j)}$ 可以通过训练得到。由 $\sigma(\cdot)$ 的定义:
可知,整个概率的计算都无需遍历整个词表,只需计算 $\log_2(V)$ 次 $\sigma(\cdot)$ 即可,相当于将计算复杂度降低到了 $\log_2(V)$,大幅提升了计算效率。
由于 $\sigma(x)+\sigma(-x)=1$,给定中心词 $w_I$,生成词典 $\mathcal{V}$ 中任意词的体哦阿健概率之和也满足:
由于 Huffman 树是用来对数据进行压缩编码的,其主要思想是高频的词距离根节点越近,那么它的路径就会越短,所需要计算的 $\sigma(\cdot)$ 函数的次数也会越少。所以相比平衡二叉树,Huffman 树的计算更有效率。
需要注意的是,我们在训练过程中,由于已知我们需要预测的词是哪一个,所以只需要计算对应的词的概率,然后进行优化即可。但是在推理过程中,我们并不知道哪个词是最优解,所以还是需要遍历整个词表。所以基于 Huffman 树的 word2vec 加速了训练过程而没有加速推理过程。
2.3.3 交叉熵(Cross Entropy)
交叉熵用于度量两个概率($p$ 和 $q$)分布间的差异性信息的一个指标。计算公式如下:
当交叉熵用于损失函数的时候,我们需要度量的是真实标签概率分布($\boldsymbol{y}_{true}$)和模型输出标签概率分布($\boldsymbol{y}_{pred}$)之间的差异,即:
在我们的情况下,$\boldsymbol{y}_{true}$ 中只有 $y_{i=O}=1$,其余位置 $y_j$ 全部是 0,$\boldsymbol{y}_{pred} = p(w_i|w_I)$。也就是说,我们只需要计算 $w_i=w_O$ 位置的交叉熵即可,如下图所示。
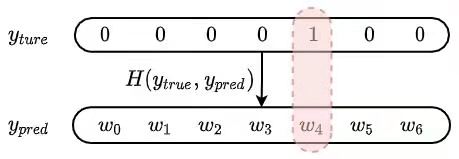
式中 $\theta$ 表示我们需要训练的参数。如上面介绍的,交叉熵是用来度量两个分布的差异性的指标。对于我们的模型来说,当然是 $\boldsymbol{y}_{ture}$ 和 $\boldsymbol{y}_{pred}$ 的差异越小越好。所以我们模型训练最终的目的是最小化交叉熵。
将 $p(w_O|w_I)$ 的 full softmax 公式代入交叉熵损失函数中得到:
使用随机梯度下降算法对模型开始训练,需要计算损失函数的梯度。为了简化,我们令 $z_{IO}=\boldsymbol{v’}_{O}^\mathsf{T} \cdot \boldsymbol{v}_I$ 及 $z_{Ij}=\boldsymbol{v’}_{j}^\mathsf{T} \cdot \boldsymbol{v}_I$。
将 $z_{IO}$ 和 $z_{Ij}$ 代回原式,根据下面两式:
可得:
上式中 $Q(\tilde{w})$ 表示噪声概率分布。根据上式,输出词的词向量越大,损失越小;而其他词的词向量越小,则损失越小。因此,交叉熵损失函数会使模型将正确的输出更加凸显,而对错误的输出进行压制,从而使参数达到最优。
2.3.4 Noise Contrastive Estimation
噪声对比估计(NCE)是通过简单的逻辑回归来区分目标词和非目标词的。
给定输入词 $w_I$,正确的输出词是 $w_O$。同时,我们可以从噪声词分布 $Q(\tilde{w})$ 中进行采样得到 $N$ 个负样本词:
此时,我们的样本就成了 $w_O$ 为正样本,$\tilde{w}_1,\tilde{w}_2,\dots,\tilde{w}_N$ 为负样本,然后再用一个二分类器进行分类:
$d$ 表示二分类器的输出标签。
当 $N$ 足够大时,根据大数定理可得:
为了计算概率分布 $p(d=1 \vert w_O, w_I)$,我们可以从联合概率 $p(d, w_j \vert w_I), w_j \in [w_O, \tilde{w}_1, \tilde{w}_2, \dots, \tilde{w}_N]$。我们有 $1/(N+1)$ 的概率得到 $w_j=w_O$,这个概率是一个条件概率 $p(w_j=w_O\vert w_I)$,同时我们有 $N/(N+1)$ 的概率得到噪声词 $q(\tilde{w}_{1:N})$。
然后我们可以计算 $p(d=1 \vert w, w_I)$ 和 $p(d=0 \vert w, w_I)$:
最后,NCE 二分类器的损失函数为:
然而,我们会发现公式中仍然有 $p(w \vert w_I)$ ,即仍然要对整个词表进行求和。为了方便,令 $Z(w_I)$ 为 $p(w\vert w_I)$ 的分母。NCE 对于 $Z(w_I)$ 的处理有两种假设:
将 $Z(w_I)$ 视作常数。Mnih & Teh, 2012 证明对于参数量很大的神经网络模型来说,将 $Z(w_I)$ 固定为 1 对每个 $w_I$ 仍是成立的。此时,上面的损失函数可以简化成:
这种情况下,我们可以证明,当 $N \to \infty$ 时,$\nabla_\theta \mathcal{L}_{NCE}=\nabla_\theta\mathcal{L}_{entrpy}$。证明过程可参看 Mnih & Teh, 2012。所以 NCE 的优化目标和交叉熵是一样的。作者还发现,当 $N=25$ 时,效果就已经与标准 softmax 效果差不多了,但是速度提升了 45 倍。
实际上 $Z(w_I)$ 到底取值是多少,不同作者都有过不同的尝试。但是从表现来看,不同点只是开始的时候收敛速度不同,最终的结果相差不大。
噪声分布 $Q(\tilde{w})$ 是一个可调参数,在选择 $Q$ 的分布的时候应该考虑两点:
① 接近真实数据分布;
② 容易采样
将 $Z(w_I)$ 看作一个可训练的参数。
从实践来看,当训练语料比较小的时候,$Z(w_I)$ 直接设置为常数效果更好。当有足够语料的时候,$Z(w_I)$ 作为可训练的一个参数效果更好。
NCE 处理似乎是故意绕开了标准 Softmax 计算量最大的分母,但其背后有充分的理论推导和证明。如果直接在最大似然估计上用这两种假设(之一)是否可行?
答案还真是不行。两种情况:
- 如果最大似然估计中的 $Z(w_I)$ 为常数,那么 $\mathcal{L}_\theta$ 的第二项 $\log Z(w_I)$ 就是常数,这就意味着 $\mathcal{L}_\theta$ 的导数的第二项就为 0。也就是噪声词的词向量缺少约束,模型只需要让目标词的概率变大即可,最坏情况下预测所有词的概率为 1 即可。
- 如果 $Z(w_I)$ 为可训练的一个参数,这个参数没有和数据产生任何联系,只需要简单的变小,就可以让似然概率变大,得到一个完全与数据无关的结果,所以也不可行。
2.3.5 Negative Sampling
Mikolov 等人 2013 年提出的负采样方法是 NCE 的一个简化版变种。因为 word2vec 的目标是训练高质量的词向量,而不是对自然语言中的词进行建模。所以,Mikolov 等人在 NCE 的基础上进一步简化。
在 NCE 假设 $Z(w_I)=1$ 的基础上,进一步令 $N q(\tilde{w})=1$,则
那么负采样的损失函数为:
因为 $Nq(\tilde{w})=1$,所以 $q(\tilde{w})=1/N$ 是一个均匀分布。这里的均匀采样并不是每个词采样概率相同,而是在总的语料中进行均匀采样。这就意味着,它实际上是按照每个词本身的词频来进行采样的,词频越高,采样的概率就越高。这种情况下,模型最终拟合的实际是词的互信息。详细解答看这里:“噪声对比估计”杂谈:曲径通幽之妙。互信息与条件概率的区别就类似:条件概率反映“我认识周杰伦,周杰伦却不认识我”,而互信息反映的是“你认识我,我也认识你”。所以,通常负采样的效果比层次 softmax 要好一些。
2.4 一些小技巧
Soft slide window。利用滑动窗口构建输入词和输出词样本对的时候,我们可以给距离较远的词更低的权重。比如,设置窗口就最大值 $s_{\text{max}}$,然后每次训练时的真实窗口大小是从 $[1, s_{\text{max}}]$ 中进行随机采样。因此,每个上下文词都有 $1/(d)$ 的概率被取到,其中 $d$ 表示到中心词的距离。
下采样高频词。极端高端的词可能由于太常见而无法得以区分(比如停用词)。而低频词可能会带有很重要的信息。为了平衡高频词和低频词,Mikolov 等人提出采样时对每个词施加一个采样概率 $1-\sqrt{t/f(w)}$。其中 $f(w)$ 表示词频,$t$ 表示相关性阈值,通常取值为 $10^{-5}$。
先学词组。词组表示一个有意义的概念单元,而非简单的独立单词的组合。先学习这些词组将他们作为一个词单元来处理可以提升词向量的质量。比如基于 unigram 和 bigram 统计:
其中 $C(\cdot)$ 表示 unigram $w_i$ 或 bigram $w_iw_j$ 的数量,$\delta$ 表示衰减阈值,防止过高频的词或词组。$s_{\text{phrase}}$ 得分越高则采样几率越高。为了形成长于两个单词的短语,我们可以随着分数截止值的降低多次扫描词汇表。
3. Count-based: GloVe
GloVe(The Global Vector)是 Pennington 等人于 2014 年提出的模型。 GloVe 结合了 矩阵分解和 skip-gram 模型。
众所周知,统计数量和共现可以表示词义。为了区分上下文的词嵌入 $p(w_O \vert w_I)$,我们定义共现概率:
$C(w_i, w_k)$ 表示 $w_i$ 和 $w_k$ 的共现频率。假设有两个词 $w_i=”ice”$ 和 $w_j=”steam”$,第三个词 $\tilde{w}_k=”solid”$ 与 $”ice”$ 相关,但是与 $”steam”$ 无关,我们希望:
因此 $\frac{p_{\text{co}}(\tilde{w}_k \vert w_i)}{p_{\text{co}}(\tilde{w}_k \vert w_j)}$ 会非常大。而如果 $\tilde{w}_k=”water”$ 与 $”ice”$ 和 $”steam”$ 都有关系,或者 $\tilde{w}_k=”fashion”$ 与两者都没有关系,$\frac{p_{\text{co}}(\tilde{w}_k \vert w_i)}{p_{\text{co}}(\tilde{w}_k \vert w_j)}$ 会接近 1。
以上描述给我们的直观感受就是,词义是通过共现概率分布的比例得到的,而非共现概率本身。所以,GloVe 模型是将第三个词的向量取决于另两个词之间的关系:
确定 $F$ 的函数形式过程如下:
$F(w_i, w_j, \tilde{w}_k)$ 是考察 $i, j, k$ 三个词的相似关系,不妨单独考察 $i, j$ 两个词。在线性空间中,两个向量的相似性最简单的就是欧氏距离 $v_i, v_j$,所以 $F$ 可以是
$\frac{p_{\text{co}}(\tilde{w}_k \vert w_i)}{p_{\text{co}}(\tilde{w}_k \vert w_j)}$ 是一个标量,而 $F$ 是作用在两个向量上的,向量与矢量之间的关系自然就可以想到内积,所以进一步确定 $F$ 的形式:
上式中,左边是差,右边是商。可以通过 $\exp(\cdot)$ 函数将两者结合在一起:
现在只要让分子分母分别相等,上式就可以成立:
只需要满足:
由于 $w_i$ 和 $\tilde{w}_k$ 是向量,所以 $\tilde{w}_k \top w_i = w_i \top \tilde{w}_k$ ,这就意味着上式中 $i, k$ 是顺序不敏感的,但是右边交换 $i,k$ 的顺序结果就会不同。为了解决这个对称性问题,模型引入两个偏置项 $b_i, b_k$,则模型变成:
上面的公式只是理想状态下,实际上左右只能无限接近,所以损失函数定义为:
根据经验,如果两个词共现次数越多,那么两个词在损失函数中的影响就应该越大,所以可以根据两个词共现的次数设计一个权重来对损失函数进行加权:
权重函数 $f(\cdot)$ 应该有以下性质:
① $f(0)=0$,即如果两个词没有共现过,那么权重为 0;
② $f(x)$ 必须是一个单调递增的函数。两个词共现次数越多,反而权重越小违反了设置权重项的初衷;
③ $f(x)$ 对于共现次数过多的词对,不能有太大的值,比如停用词。
有了这三个性质,可以将 $f(x)$ 定义为:
根据经验 GloVe 作者认为 $x_\text{max}=100, \alpha=3/4$ 是一个比较好的选择。
Reference
The amazing power of word vectors, Adrian Colyer
Learning Word Embedding, Lilian Weng
Illustrated word2vec, Jay Alammar
Efficient Estimation of Word Representations in Vector Space Mikolov et al. 2013
Distributed Representations of Words and Phrases and their Compositionality Mikolov et al. 2013
Linguistic Regularities in Continuous Space Word Representations Mikolov et al. 2013
word2vec Parameter Learning Explained Rong 2014
word2vec Explained: Deriving Mikolov et al’s Negative Sampling Word-Embedding Method Goldberg and Levy 2014
GloVe: Global Vectors for Word Representation, Jeffrey Pennington et al. 2014
A Brief History of Word Embeddings, gavagai
Word Representation, Chuanrong Li
Devopedia. 2020. “Word2vec.” Version 4, September 5. Accessed 2021-03-28. https://devopedia.org/word2vec
word2vec 中的数学原理详解, peghoty
(十五)通俗易懂理解——Glove算法原理, 梦里寻梦