1. 理论基础
如果有人问你现在几点了,你不会告诉他现在“10:14:34:4301”,而是会告诉他现在“10:15”。
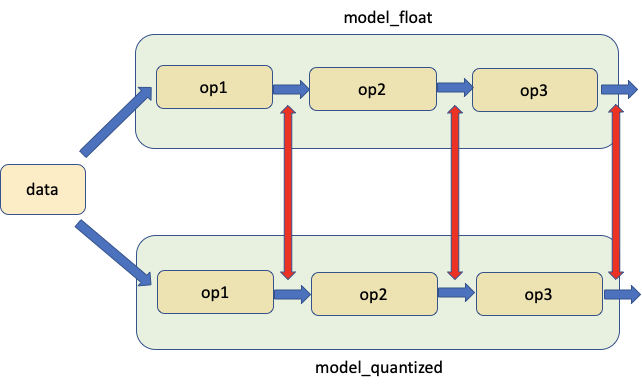
量化就是通过降低网络层权重和/或激活函数的数值精度达到模型压缩的方法。通常神经网络模型的参数都是过量的,将模型进行压缩可以使模型更小,运算速度更快。通常硬件上 8-bit 精度的数据比 32-bit 的数据处理速度更快。
1.1 映射函数
这里所说的映射函数就是将浮点数映射到整型数。一个常用的映射函数为:
其中 $r$ 是输入,$S,Z$ 分别是量化参数。通过下式可以将量化后的输入进行浮点数翻转:
注意 $\tilde{r}\ne r$,两者的差距表示量化误差。
1.2 量化参数
上面我们说到 $S,Z$ 表示量化参数,$S$ 可以简单的表示成输入范围和输出范围的比值:
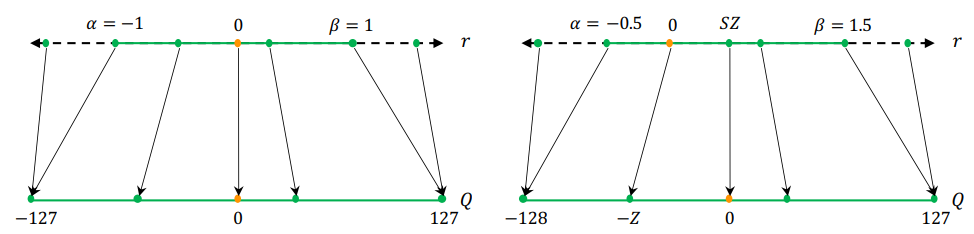
其中 $[\alpha, \beta]$ 表示输入的范围,即允许输入的上下界;$[\alpha_q, \beta_q]$ 表示量化后的输出的上下界。对于 8-bit 来说,输出的上下界为 $\beta_q -\alpha_q \le 2^8-1$。
$Z$ 表示偏差,如果输入中有 0,$Z$ 用来保证将 0 也映射到 0:$Z = -\frac{\alpha}{S}-\alpha_q$。
1.3 校准
选择输入限定范围的过程称之为校准。最简单的方法就是记录输入的最小最大值作为 $\alpha, \beta$。不同的校准方法会带来不同的量化策略。
- $\alpha=r_{min},\beta=r_{max}$ 时,称之为非对称量化,因为 $-\alpha\ne \beta$;
- $\alpha=-\max(|r_{min}|, |r_{max}|), \beta = \max(|r_{min}|, |r_{max}|)$ 时,称之为对称量化, 因为 $-\alpha=\beta$。
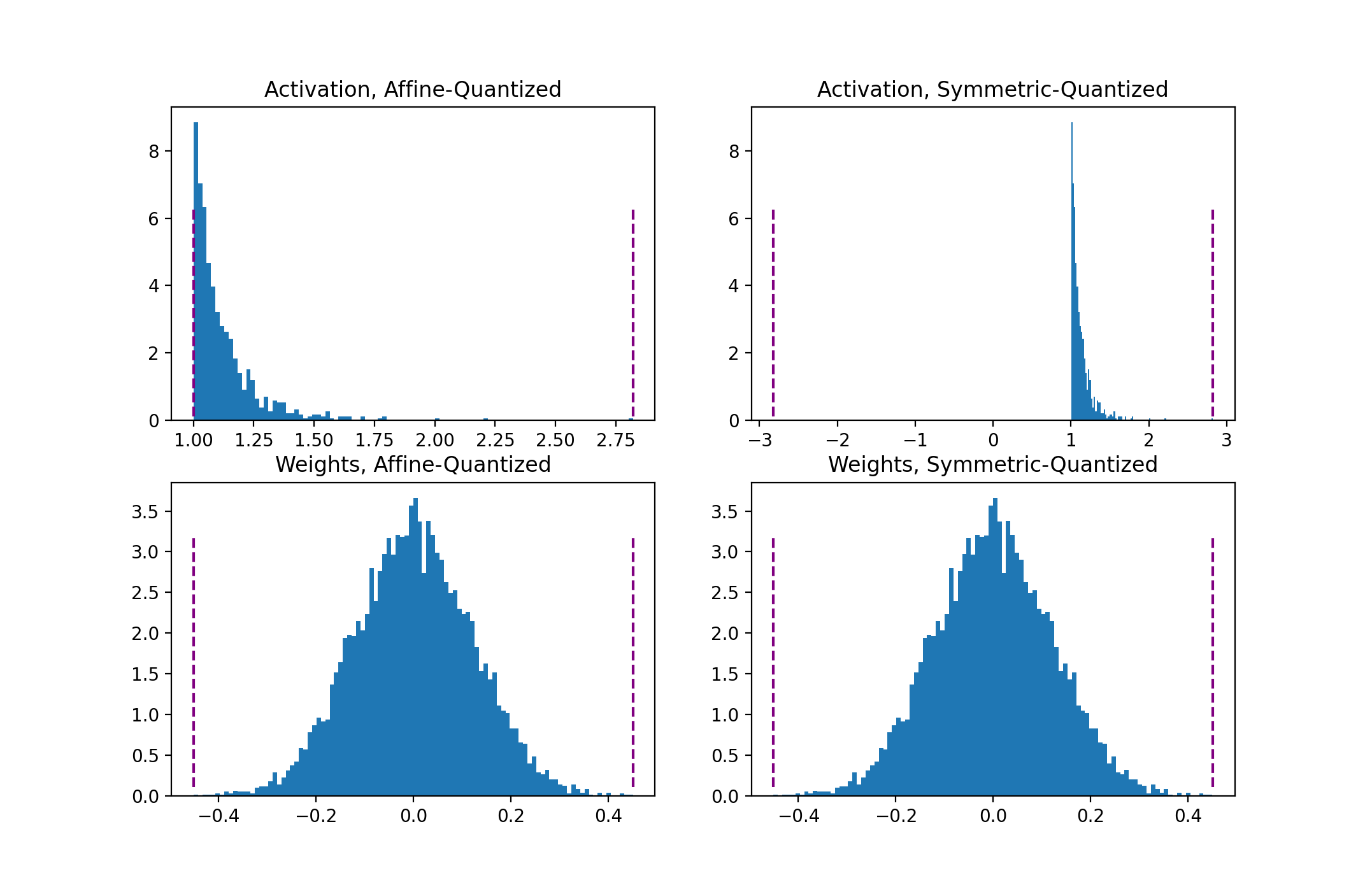
在实际应用中,对称量化应用更加广泛,因为其可以令 $Z=0$,这样可以减少推理过程计算成本。而非对称量化比对称量化更加紧凑。非对称量化容易受到异常值的影响,所以可以改进为百分比或者 KL 散度来优化这个问题。
1 | act = torch.distributions.pareto.Pareto(1, 10).sample((1,1024)) |
我们可以直接用 Pytorch 内置的模块:
1 | from torch.quantization.observer import MinMaxObserver, MovingAverageMinMaxObserver, HistogramObserver |
1.4 Per-Tensor and Per-Channel 量化策略
量化参数可以针对整个权重计算,也可以单独计算每个通道。Per-tensor 就是使用相同的量化参数应用于所有通道,而 per-channel 是不同的通道使用不同的量化参数:

通常权重的量化方面,对称 per-channel 量化效果更好。
1 | from torch.quantization.observer import MovingAveragePerChannelMinMaxObserver |
1.5 QConfig
用 QCfing NameTuple 存储 Observers 和量化策略:
1 | my_qconfig = torch.quantization.QConfig( |
2. In Pytorch
2.1 Post-Training Dynamic/Weight-only Quantization
1 | import torch |
- 通常会有更高的准确率;
- 对于 LSTM / Transformer 来说,动态量化是首选;
- 每一层事实校准和量化可能需要消耗算力。
2.2 Post-Training Static Quantization (PTQ)

1 | # Static quantization of a model consists of the following steps: |
- 静态量化比动态量化更快;
- 静态量化模型可能需要定期重新校准以保持对分布漂移的鲁棒性。
2.3 Quantization-aware Training (QAT)

1 | # QAT follows the same steps as PTQ, with the exception of the training loop before you actually convert the model to its quantized version |
- QAT 准确率比 PTQ 高;
- 量化参数可以随着模型一起训练;
- QAT 的模型重训可能需要消耗不少时间。
3. 灵敏度分析
并不是所有层在量化中起到的作用都是相等的,有些层对准确率的影响可能会比较大,要想找出最优的量化层与准确率的解是比较消耗时间的,所以人们提出使用 one-at-a-time 方法来分析那些层对准确率最敏感,然后再 32-bit 浮点数上重训:
1 | # ONE-AT-A-TIME SENSITIVITY ANALYSIS |
Pytorch 停工了分析工具:
1 | # extract from https://pytorch.org/tutorials/prototype/numeric_suite_tutorial.htmlimport torch.quantization._numeric_suite as nsdef SQNR(x, y): # Higher is better Ps = torch.norm(x) Pn = torch.norm(x-y) return 20*torch.log10(Ps/Pn)wt_compare_dict = ns.compare_weights(fp32_model.state_dict(), int8_model.state_dict())for key in wt_compare_dict: print(key, compute_error(wt_compare_dict[key]['float'], wt_compare_dict[key]['quantized'].dequantize()))act_compare_dict = ns.compare_model_outputs(fp32_model, int8_model, input_data)for key in act_compare_dict: print(key, compute_error(act_compare_dict[key]['float'][0], act_compare_dict[key]['quantized'][0].dequantize())) |
4. 模型量化工作流
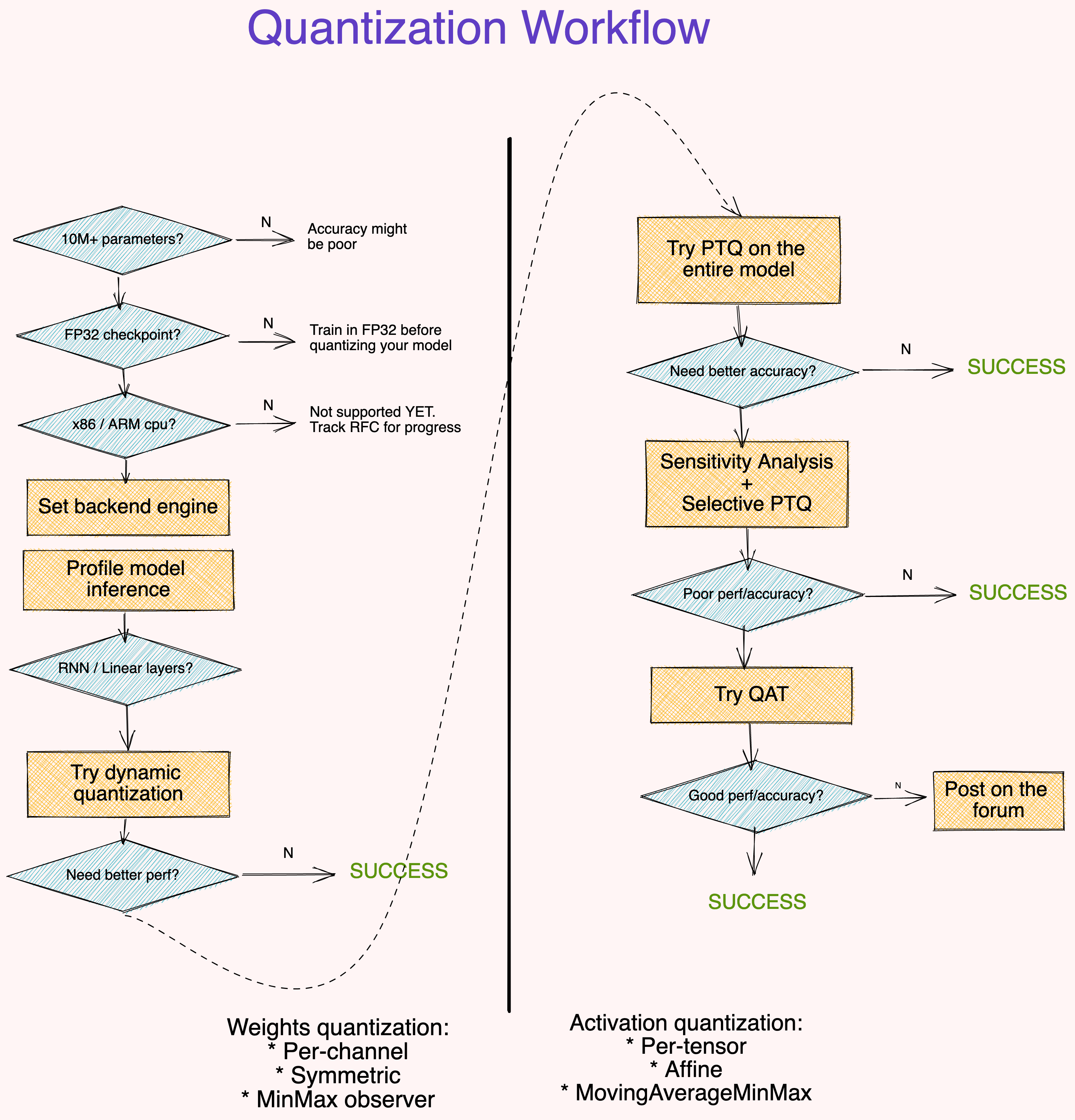
5. 写在最后
- 大模型(参数量大于 1 千万)对量化误差更鲁棒;
- 从 FP32 开始训练模型比 INT8 开始训练模型准确率更高;
- 如果模型中有大量的线性层或者递归层,可以首先考虑动态量化;
- 用
MinMax对称 per-channel 量化权重,用MovingAverageMinMax非对称 per-tensor 量化激活函数。