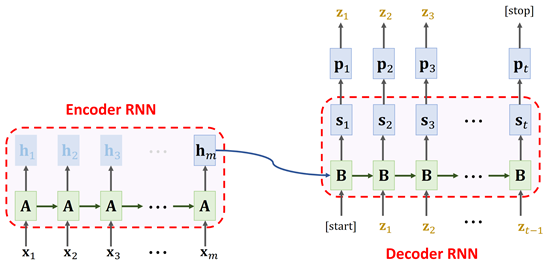
之前我们介绍过 seq2seq 模型,通常用作机器翻译,通过编码器(encoder)对源语言进行编码,然后通过解码器(decoder)对编码器的结果进行解码,得到目标语言。原始的 seq2seq 模型是使用平行语料对模型从头开始进行训练,这种训练方式需要大量的平行语料。Prajit Ramachandran 提出一种方法,可以大幅降低平行语料的需求量:先分别使用源语言和目标语言预训练两个语言模型,然后将语言模型的权重用来分别初始化编码器和解码器,最终取得了 SOTA 的结果。
之前我们介绍过 seq2seq 模型,通常用作机器翻译,通过编码器(encoder)对源语言进行编码,然后通过解码器(decoder)对编码器的结果进行解码,得到目标语言。原始的 seq2seq 模型是使用平行语料对模型从头开始进行训练,这种训练方式需要大量的平行语料。Prajit Ramachandran 提出一种方法,可以大幅降低平行语料的需求量:先分别使用源语言和目标语言预训练两个语言模型,然后将语言模型的权重用来分别初始化编码器和解码器,最终取得了 SOTA 的结果。