1. 简介
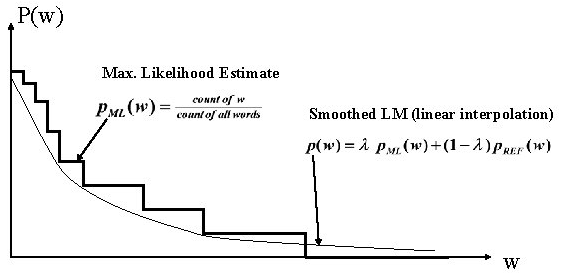
统计语言模型中,无论是 n-gram 还是对数线性语言模型都面临一个非常严重的问题——维度爆炸。为了解决维度爆炸问题,Bengio & Bengio 2000 年提出了一种使用分布式词特征表示的方法,也就是后来所说的词向量。
统计语言模型中,无论是 n-gram 还是对数线性语言模型都面临一个非常严重的问题——维度爆炸。为了解决维度爆炸问题,Bengio & Bengio 2000 年提出了一种使用分布式词特征表示的方法,也就是后来所说的词向量。
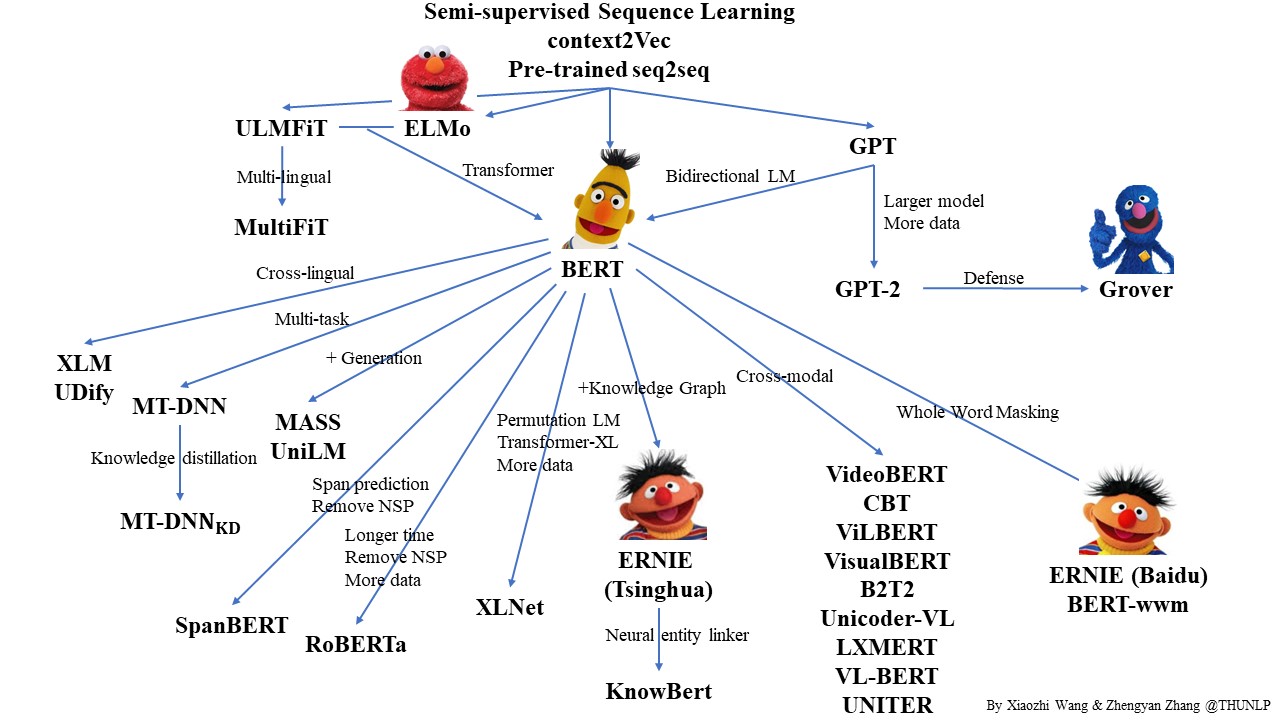
自从 2017 年 Vaswani 等人提出 Transformer 模型以后 NLP 开启了一个新的时代——预训练语言模型。而 2018 年的 BERT 横空出世则宣告着 NLP 的王者降临。那么,什么是预训练?什么是语言模型?它为什么有效?
2 / 2