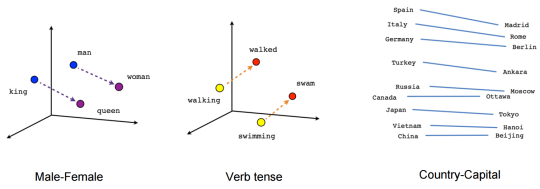
上一篇文章我们介绍了预训练词向量,它的缺点很明显:一旦训练完,每个词的词向量都固定下来了。而我们平时生活中面临的情况却复杂的多,一个最重要的问题就是一词多义,即同一个词在不同语境下有不同的含义。CoVe(Contextual Word Vectors)同样是用来表示词向量的模型,但不同于 word emebdding,它是将整个序列作为输入,根据不同序列得到不同的词向量输出的函数。也就是说,CoVe 会根据不同的上下文得到不同的词向量表示。
1. 神经网络机器翻译
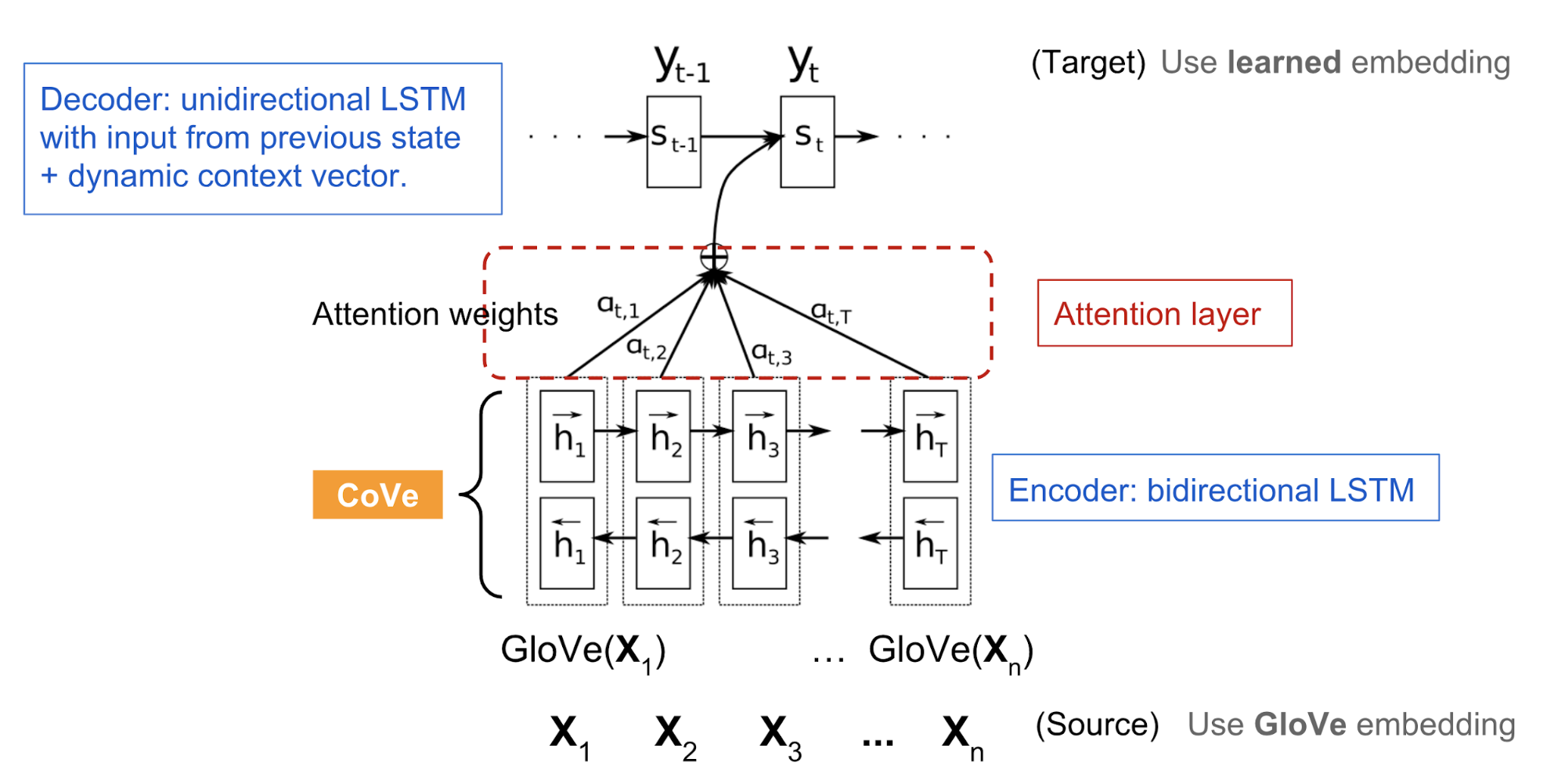
上图是一个经典的 attention seq2seq 模型:
源语言 $x = [x_1, x_2, …, x_n]$;
目标语言:$y = [y_1, y_2, …, y_m]$;
用 GloVe 将源语言的词转换成词向量;
编码器是 bi-LSTM,输出一个隐状态序列:
其中 $h_t = [\overrightarrow{h_t}; \overleftarrow{h_t}]$,$\overrightarrow{h_t}=\text{LSTM}(x_t, \overrightarrow{h}_{t-1})$;$\overleftarrow{h_t}=\text{LSTM}(x_t, \overleftarrow{h}_{t-1})$。
注意力加持的解码器:
seq2seq 训练完成之后,将编码器的输出作为 CoVe 用于下游任务。
2. CoVe 在下游任务中的应用
seq2seq 编码器的隐状态作为下游任务的语义向量:
论文中提出将 GloVe 和 CoVe 进行拼接用于问答和分类任务。GloVe 是通过词共现比例学习到的向量,因此它没有句子上下文。而 CoVe 是通过处理文本序列学习到的向量,本身就具有上下文信息:
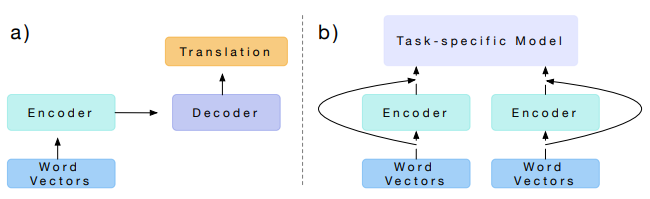
给定下游任务,首先将输入的词用上面的方法转化成向量,然后输入到特定任务模型中进行训练。
3. 总结
CoVe 的缺点是显而易见的:
- 因为预训练过程是有监督训练,所以训练效果严重依赖标注数据(平行语料);
- CoVe 的性能受限于特定任务的模型结构。
Reference
- Learned in Translation: Contextualized Word Vectors, Bryan McCann,James Bradbury,Caiming Xiong,Richard Socher. 2017
- Generalized Language Models, Jan 31, 2019 by Lilian Weng