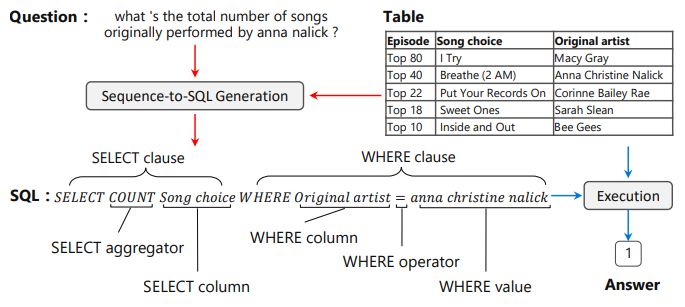
1. 简介
当今社会,人们越来越多地开始和数据打交道,其中一个核心的问题是数据的存储。为了更好的存储和管理数据,通常会把数据存储在数据库中。对于数据库管理系统的用户来说,必须具备两方面的能力:
- 对于数据库的结构非常了解,比如表名、列名、实体关系等等;
- 熟悉数据库查询语言,比如 SQL。
虽然 SQL 语言并不复杂,但是对于非技术人员来说,这仍然是阻碍他们与数据进行交互的门槛。就像封面中的例子:“what ‘s the total number of songs originally performed by anna nalick?”
- 首先,我怎么知道有哪些数据可用?也就是说,我怎么知道我要去哪张表里查我想要的数据?
- 其次,我怎么知道要去
Song choice和Original artist这两列中去找? - 然后,如果我得到了 anna nalick 有多少首歌以后,我还想知道她和 Macy Gray 谁的歌更多怎么办?
- 再然后,如果我想知道的不是 anna nalick 有多少首歌,而是每个歌手分别有多少首歌又怎么办?或者有哪些歌手的歌比 anna nalick 多?
- $\cdots$
如果我们能让计算机(数据库)理解人类的语言,只需要像和人类一样交流就可以从数据库中得到我们想要的数据岂不是美哉?这就是 NL2SQL 想要达到的目标。NL2SQL(Natural Language to SQL), 顾名思义是将自然语言转为 SQL 语句。它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据。
1.1 NL2SQL 的一些实际应用场景
通常数据交互的场景有三种:
- 企业内部数据管理。几乎所有企业都有大量数据需要存储和管理,多数企业会选择使用数据库,而对于这些企业来说,通常会雇佣专业技术人员来管理数据库。因此,企业内部数据管理对于 NL2SQL 的需求并不强烈;
- 个人用户数据管理。对于个人用户而言,很少有用户的数据量会多到需要用到数据库。因此,这种场景下似乎 NL2SQL 的作用也并不明显。
- 普通用户与企业数据之间的交互。比如订餐、订票、查天气、查公交地铁等等。在这些场景下,现在的技术手段是企业通过一些界面的选项引导用户一步一步查询到自己想要的数据。对于用户来说,这些操作繁复冗杂,而且需要一定的门槛。正是由于引导式操作的繁杂给社会带来了一些尴尬局面——移动互联网为年轻人提供了便利,但却给老年人带来了麻烦。同时,对于企业来说,如何引导设计查询页面,如何编写查询程序同样也是必须面对的问题。如果能够实现专用户直接使用自然语言进行信息查询,以上问题都会迎刃而解,这也是 NL2SQL 最大的意义所在。
2. NL2SQL 发展简史
NL2SQL 虽然是最近才火起来的,但是实际上它的研究历史还是比较长的。早在上世纪六七十年代人们就提出了 NLIDB (Natural Language Interface to Database)概念并做了一些研究。但是受限于数据量和计算机的算力,当时主要的技术手段是模式匹配、语法树和语义语法等。
最早出现的 NLIDB 系统是有两个:
- BASEBALL,主要面向当时没搞过国内的棒球联赛;
- LUNAR,用来回答有关从月球带回来的岩石样本的问题。 它能够准确地回答 80% 的查询,没有任何错误。
到了上世纪 70 年代末期,陆续出现了一些 NLIDB 系统:
- PLANES,该系统甚至能够响应不连贯或模糊的用户请求;
- LIFER/LADDER,通过语义语法系统分析用户请求;
- RENDEZVOUS,它是 IBM 实验室的 San José 开发的,可以帮助用户在模棱两可的情况下提出自己的请求
- CHAT-80,采用语义语法技术处理自然语句,使得 CHAT-80 达到了当时最好的效果。它最大的问题仍然是只对特定领域的数据集有效。
- MASQUE, DIALOGIC,都是对 CHAT-80 的改进型系统,在处理效率上有了大幅的提升。
从 90 年代开始,人们的研究开始聚焦关系型数据库。也就是说 NLIDB 系统开始向 NL2SQL 方向聚焦,当然此时的方法仍然是只针对对特定领域的数据。
- MASQUE/SQL,就是此时开发出来用于处理商业数据库的系统。
- California Restaurant Query,Expedia Hotels,GeoQuery,Hollywood,JobQuery,SQ-HAL,SystemX 等等一系列系统如雨后春笋般相继出现。
如果说 70 年代是 NLIDB 系统的诞生的话,那么进入 2000 年以后可以算是该系统的第一次进化。一些新方法的提出使得 NLIDB 不再只对特定领域的数据有效(需要指出的是,此时的主要技术手段仍然是基于规则的)。
- PRECISE,是第一个采用插件式的 NLIDB 系统。它通过结合语法技术和数学方法,使得语义分析器完全独立于数据库的配置信息。但是它只能处理简单的句子,不能处理嵌套语句,主要是因为它假设自言语句中的词和数据库表格中的数据存在一一对应的关系。
- NALIX,用于处理 XML 数据库。
随着机器学习技术的发展,机器学习也开始应用于 NLIDB 系统。
- NaLIR,通过与用户的交互使得它能处理复杂的自然语句。
- ATHENA,通过特定领域的本体处理更加丰富的语义信息。
- SQLizer,将自然语句转成逻辑表达,然后通过迭代优化逻辑表达式。
- Templar,是一种使用查询日志进行映射和联接路径生成的优化技术。
Seq2sql,SQLNet,TypeSQL,Coarse-to-Fine,IncSQL,X-SQL,STAMP,IRNet,SQLova,TRANX,SyntaxSQL …
3. 数据集
| 数据集 | 总语句 | 训练语句 | 验证语句 | 测试语句 | 总表数 |
|---|---|---|---|---|---|
| WiKiSQL | 80654 | 56355 | 8421 | 15875 | 26531 |
| ATIS | 5317 | 4379 | 491 | 447 | 25 |
| Advising (query split) |
4387 | 2040 | 515 | 1832 | 15 |
| Advising (question split) |
4387 | 3585 | 229 | 573 | 15 |
| GeoQuery | 880 | 550 | 50 | 280 | 7 |
| Scholar | 816 | 498 | 100 | 218 | 10 |
| Patients | 342 | 214 | 19 | 109 | 1 |
| Restaurant | 251 | 157 | 14 | 82 | 3 |
| MAS | 196 | 123 | 11 | 62 | 17 |
| IMDB | 131 | 82 | 7 | 42 | 16 |
| YELP | 128 | 80 | 7 | 41 | 7 |
| Spider | 9693 | 8659 | 1034 | - | 873 |
| WTQ | 9287 | 5804 | 528 | 2955 | 2102 |
| WikiTableQuestions | 22033 | 14152 | 3537 | 4344 | 2100 |
| CSpider | 8832 | 6831 | 95 | 1906 | 876 |
| DuSQL | 28763 | 22521 | 2483 | 3759 | 813 |
| TableQA | 54059 | 41522 | 4396 | 8141 | 5291 |
上表中列出了目前主要的一些数据及其统计信息,其中蓝色字体对应的数据为中文数据集,其他数据都是英文数据集。下面我们挑选几个应用最广泛的几个英文数据集和中文数据集进行简单的介绍。
ATIS (The Air Travel Information System):ATIS 是一个年代较为久远的经典数据集,由德克萨斯仪器公司在1990 年提出。该数据集获取自关系型数据库 Official Airline Guide (OAG, 1990),包含 25 张表以及 5000 次的问询,每次问询平均7轮,93% 的情况下需要联合 3 张以上的表才能得到答案,问询的内容涵盖了航班、费用、城市、地面服务等信息。总的来说, ATIS 数据集存在数据量少,标注简单,领域单一等问题。
WikiSQL:该数据集是 Salesforce 在 2017 年提出的大型标注 NL2SQL 数据集,也是目前规模最大的 NL2SQL 数据集。它是 Victor Zhong 等研究人员基于维基百科标注的数据。这个数据集一经推出就引起了学术界极大的关注。因为他对模型提出了新的挑战,研究人员也在此数据集的基础上研究出了大量的优秀模型。目前学术界的预测准确率可达 91.8%。但是 WiKiSQL 数据集是一个单表无嵌套的数据集,总的来说相对于实际场景还是偏于简单。
- Spider:Spider 数据集是耶鲁大学于 2018 年新提出的一个较大规模的 NL2SQL 数据集。Spider 数据集虽然在数据数量上不如 WikiSQL,但 Spider 引入了更多的 SQL 用法,例如 Group By、Order By、Having、UNION、EXCEPT、INTERSECT、LIMIT 等高阶操作,甚至需要 Join 不同表,更贴近真实场景,所以 Spider 是目前最复杂的数据集。作者根据 SQL 语句的复杂程度(关键字个数、嵌套程度)分成 4 种难度,而以 Spider 的标准划分的话, WiKiSQL 只有 easy 难度。目前准确率最高只有 54.7%。
- WikiTableQuestions:该数据集是斯坦福大学于 2015 年提出的一个针对维基百科中那些半结构化表格问答的数据集,表格中的数据是真实且没有经过归一化的,一个 cell 内可能包含多个实体或含义,比如「Beijing, China」或「200 km」;同时,为了很好地泛化到其它领域的数据,该数据集测试集中的表格主题和实体之间的关系都是在训练集中没有见到过的。
- CSpider:CSpider 是西湖大学利用 Spider 作为源数据集进行问题翻译,并利用 SytaxSQLNet 作为基线进行评测的 NL2SQL 数据集。CSpider 只翻译了问题,而数据库仍然是英文的,因此它在传统的 NL2SQL 上增加了额外的一些挑战,比如中文问题和英文数据库的对应问题(question-to-DB mapping)、中文的分词问题以及一些其他的语言现象。
- DuSQL:该数据集是百度基于现有数据集问题和实际应用需求构建的多领域、多表数据集,覆盖了更多的问题类型。
- TableQA:TableQA 是一个大规模,跨领域的中文 NL2SQL 数据集。与现有的 NL2SQL 数据集不同,TableQA 不仅要很好地概括为不同问题和表模式的 SQL 框架,而且还要概括为条件值的各种表达式。实验结果表明,在 WikiSQL 上具有 95.1% 的条件值精度的最新模型在 TableQA 上仅获得 46.8% 的条件值精度和 43.0% 的逻辑形式精度,这表明所提出的数据集具有挑战性且需要处理。
4. 技术路线
为了系统的介绍现在的 NL2SQL 方法,我们将模型分成三部分:输入、技术方法、输出。然后总结出不同模型在这三部分的处理方法。
4.1 输入
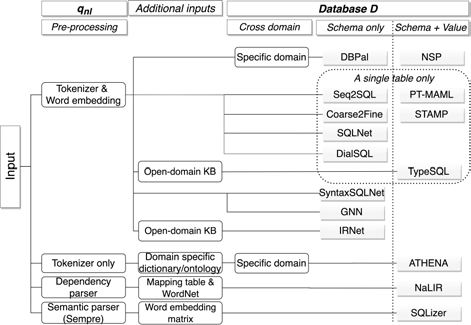
模型的输入一般从三个方面考虑:
- 自然语言问句 $q_{nl}$ 的预处理;
- 附加信息的输入;
- 数据库的处理。
现有的所有方法中,模型输入都会包含两部分:自然语言问句 $q_{nl}$ 和数据库 $D$,其中 $S_D$ 表示数据库中的表头,$V_D$ 表示表中每一列的数据集合。
4.1.1 自然语言问句预处理
自然语言问句的预处理有不同的方法:
- 基于深度学习的模型,将($q_{nl}$,$S_D$,$V_D$)转化成词向量是必备的步骤;
- 基于规则的模型,包含以下几种预处理方法:
- 将自然语言问句解析成句法树,比如 NaLIR;
- 将自然语言问句转化成逻辑表达式,比如 SQLizer;
- 单纯地只进行分词,比如 ATHENA;
4.1.2 数据库的处理
模型对数据库的处理包含以下几种方法:
将 $D$ 作为模型的输入进行处理,这是最常见的做法;
只用 $D$ 来构建词表;
有些模型假设数据库只包含一张表;
通过字典将自然语句中的一些实体映射到本体上,然后通过本体关系找到可能需要 JOIN 的表;
”本体(ontology)“原本是一个哲学概念,后来被应用于计算机领域。这里不对这个概念做过多的介绍,简单举几个例子说明什么是本体,大家自行体会。
比如:
“阿里巴巴”、“金山办公”、“姚明”等等的本体是“名字”;
“2012年”、“周五”、“3月份”等的本体是“时间”;
…
诸如此类的用来描述事物本质的概念称为“本体”。
只用 $S_D$ 或者使用 $S_D + V_D$。
4.1.3 附加信息输入
通常使用的附加信息包括:
- 开放领域的知识库,比如 Freebase;
- 使用专业领域的字典;
- 提前构建的 $q_{nl}$ 中的词语与 SQL 关键词之间的映射字典;
- WordNet;
- 用于计算词相似度的预训练词向量矩阵。
4.2 技术方法:输入增强
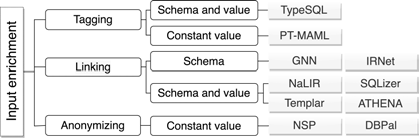
输入增强有三种方法:
标签化(Tagging)
- 首先,找到 $q_{nl}$ 中的一些特殊词,比如 TypeSQL 通过字符串匹配找到 $q_{nl}$ 中包含在数据库或知识库中的实体;PT-MAML 是利用词相似度匹配的方法在 $q_{nl}$ 中找到包含在数据库中的 $V_D$。
- 然后,将这些词和数据库中实体之间建立联系;
- 然后,给 $q_{nl}$ 中的找到的词打上实体标签或者直接将这些词规范化到 $V_D$;
- 将每个词的标签转化成词向量拼接到每个词的词向量后面,或者将每个实体的类型加到 $q_{nl}$ 对应实体的位置之前;
- 将处理后的词向量序列输入到编码器中。
其实一句话总结就是,标签化增强技术是利用数据库中的实体对 $q_{nl}$ 中的实体进行增强。这样可以使模型更好的捕捉到 $q_{nl}$ 实体和数据库实体的对应关系,从而提高准确率。但是这严重依赖 $q_{nl}$ 实体与数据库实体的匹配技术(无论是字符串匹配还是词相似度匹配),理论上讲即使没有这一步模型也是可以自动学习到,但是这种做法可以提高训练效率,在小数据量上效果应该不错,但是上到大数据量上之后过拟合的风险会大大提高。(当然,这只是个人推断没有实验证据)
词链接(Linking)
所谓词链接技术就是计算 $q_{nl}$ 中每个词与数据库中的实体之间的相似度。词链接有两种方法:
- 使用词向量计算 $q_{nl}$ 中的词与数据库中的实体之间的相似度;
- 使用神经网络计算词与词之间的相似度。
词链接的相似度同时输入给 $q_{nl}$ 编码器和 $S_D$ 编码器。词链接技术与标签化技术的不同之处在于计算相似度的过程是可以跟随整个模型一起进行训练的。
词链接的技术要比标签化的方法更加合理,但这也意味着模型需要训练的参数量有所上升,训练和推理效率会受到影响。
匿名化(Anonymizing)
匿名化方法就是将 $q_{nl}$ 和 $q_{sql}$ 中的常数值替换成一些特殊符号,这样可以降低词表大小。比如 “city.state_name=’New York’” 替换成 “city.state_name=’@STATE’”。用 “@STATE” 来代替具体的城市。
4.3 技术方法:翻译技术
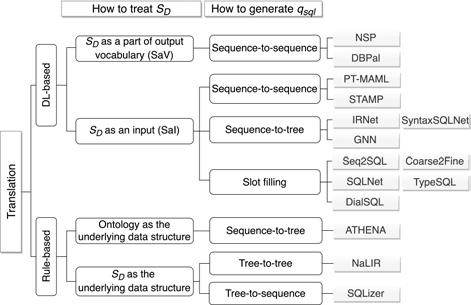
4.3.1 基于规则的方法
现在的基于规则的方法通常是将 $q_{nl}$ 解析成一个树结构的中间表达,不同的模型生成的树不一样。
NaLIR 是将输入的依存句法树转化成另一种分析树。通过一个简单的算法来移动任意初始句法树的子树,然后使用一系列节点插入规则最终实现树结构的变换。
ATHENA 是构建一棵解释树(Interpretation tree),其中节点对应概念或者属性,边表示在本体库中概念或属性之间的关系。
SQLizer 是将经过预处理的自然语言问句转化成逻辑表达式。
4.3.2 基于深度学习的方法
基于深度学习的方法接班架构都是“编码器—解码器”(encoder-decoder)结构的。2019 年之前的工作,通常都是使用 RNN 作为编码器对 $q_{nl}$ 进行编码。但是随着 Transformer 的特征提取能力逐渐被人们发掘,尤其是以 BERT 为代表的预训练语言模型技术被提出以后,使用预训练语言模型作为编码器逐渐成为主流。
下面我们从两个方面介绍基于深度学习的 $q_{nl} \rightarrow q_{sql}$ 映射方法。
如何处理数据库 $S_D$
在深度学习框架下,数据库通常有两个作用:作为输出词表的一部分(SaV)和作为输入(SaI)。
- 在 SaV 方法中,将数据库中所有的表名和列名添加到输出词表中。在解码过程中,解码器从输出词表中选择需要解码的词。
- 在 SaI 方法中,数据库中所有表名和列名都以输入的方式传递给模型。在解码过程中,解码器利用指针机制从输入中选择需要解码的词。
如何生成 $q_{sql}$
在生成 $q_{sql}$ 方面,已有的深度学习模型可以分成三种:
- sequence-to-sequence:输入一个序列,输出一个序列,类似于机器翻译;
- sequence-to-tree:输入一个序列,输出一棵树;
- slot filling:所谓的槽填充就是,把 SQL 语句看成是一系列的槽,通过解码器对一个一个的槽进行填充。比如,我们预先设定一个 SQL 语句:“SELECT * FROM * WHERE *”,其中 “ * ” 就是我们要填充的内容。
4.4 技术方法:后处理
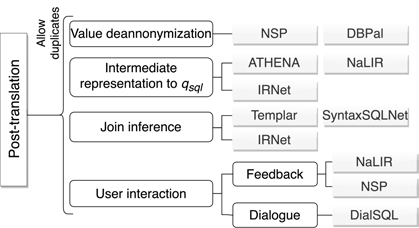
后处理通常有四种:
- 将之前匿名化的值进行还原;
- 对输出是树结构的模型来说,需要后处理将树结构的结果解析成 $q_{sql}$;
- JOIN 推理;
- 使用用户反馈对结果进行修正。
4.5 技术方法:训练
NL2SQL 模型的训练方法是根据它采用的 AI 算法确定的,目前来说有以下几种:
- 最常见的深度学习模型采用监督学习训练算法;
- NSP 和 DBPal 模型通过预先设定的模板和释义技术(paraphrasing techniques)记性训练;
- Seq2SQL 和 STAMP 模型采用强化学习方法进行训练;
- PT-MAML 采用元学习方法训练;
4.6 输出
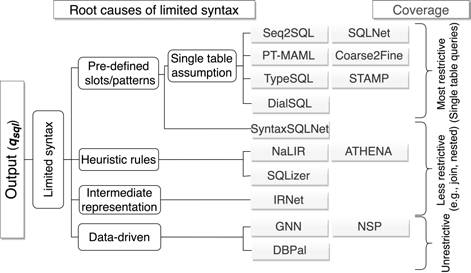
目前 NL2SQL 技术存在四个方面的缺陷:
- 预定义的语法模式或者槽类型(实体类型);
- 启发式翻译规则;
- 语法覆盖能力有限的中间表达;
- 有限的训练数据。
所以目前的 NL2SQL 输出的 SQL 语句是有限制的。根据限制能力的不同可以分成:
- 不受限制的,这种模型通常是数据驱动类型的。缺点就是需要大量的训练数据,这也是目前几乎所有 AI 任务的痛点;
- 低限制的,这样的模型通常是基于规则的模型, 限制通常来源于连表查询和嵌套查询等;
- 非常受限的,这样的模型通常需要预定义语法模式和实体类型,一旦发现问题要进行改动的影响面会非常大,甚至可能需要重新设计模型结构,重新标注数据等等。
所有模型输出结果的方式是先生成一系列候选语句,然后对候选语句进行排序,选择排名最高的 SQL 语句。基于规则的模型会设计不同的排序算法,而基于深度学习的模型通常采用的是用 softmax 函数来计算得分,根据每一个候选语句的得分进行排序。
5. 评估方法
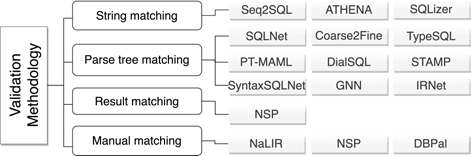
对于 NL2SQL 模型来说,一个非常重要的点就是,我们如何评估一个模型的好坏?目前的评估方法有四种:
- 字符串匹配,通过对比模型生成的 SQL 语句和给定的标准 SQL 语句,判断生成 SQL 语句的正确性。这种方法可能导致误判,比如 WHERE 条件中,$a \mathrm{and} b$ 和 $b \mathrm{and} a$ 是等价的,但是用字符串匹配的方式就会得到错误的评估。
- 解析树匹配,通过对比模型生成的 SQL 和标准 SQL 的解析树,判断生成 SQL 的正确性。这种方法相比字符串匹配的方式,误判率会低一些,但是仍然是有一定的限制。比如,一个嵌套 SQL 语句和一个非嵌套语句实际上是等效的,但是他们的解析树是不一样的,这样解析树匹配的时候就会造成误判。
- 结果匹配,通过对比两条 SQL 语句在数据库中的执行结果来判断生成的 SQL 是否正确。这种方式看起来比较合理,但是仍然不能排除两条不同的 SQL 会得到相同结果的可能性。
人工验证,人工验证的误判率是最低的,但是却是成本最高的方法,几乎无法应用于实际生产中。
多级验证(Multi-level),用于验证两条 SQL 语句是否等价,如下图所示:
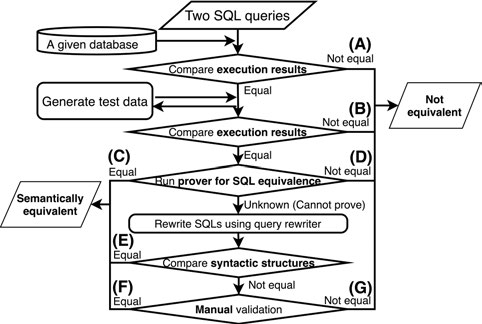
该方法的核心思想就是:给定两条 SQL 语句,如果它们在任何数据库中的执行结果总是相同的,那么他们就是等价的,一旦出现一次不同的结果,那么他们就不是等价的。
在给定的数据库上面执行两条 SQL 语句,如果结果不同则直接认定模型生成的 SQL 有误。如果结果相同,则继续下一步。
如果第一部中的数据库比较小,数据比较少,两条不等价的 SQL 语句可能会产生相同结果。所以,作者提出使用数据库测试技术对比两条 SQL 语句的执行结果。
所谓数据库测试技术,实际上是为了检测数据库引擎是否存在bug的技术。具体做法就是生成大量的数据库实例,然后跑 SQL 语句。用在这里主要是通过生成大量的数据库实例来验证两条 SQL 语句是否有相同的执行结果。
用一个现成的验证器,验证两条语句是否等价,比如 Cosette。
如果验证器无法验证两条语句是否等价,那么使用 SQL语句重写技术对两条 SQL 语句进行重写。然后对比重写后的 SQL 语法结构。
如果重写后的 SQL 语法结构不等价,再使用人工验证。
在本文的实验中,数据库实例生成器用的是 EvoSQL,SQL 语句等价验证器用的是 Cosette,SQL 语句重写用的是 IBM DB2。
6. 实验结果
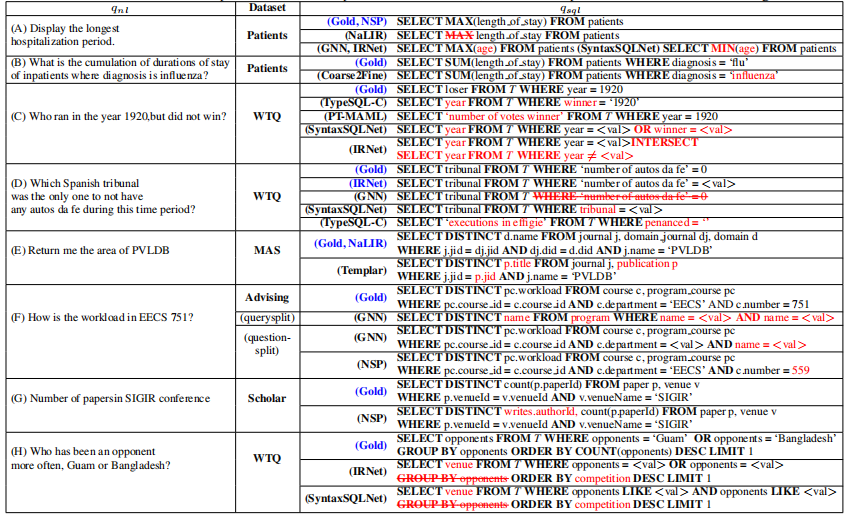
为了方便我们对实验结果进行分析,这里专门挑选出一些比较典型的错误案例。
6.1 不同评估方法的对比
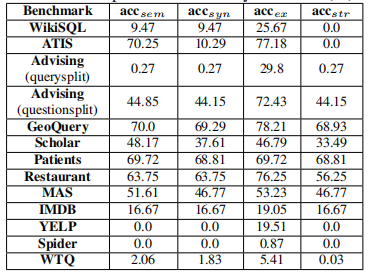
首先定义一个表格中的变量。
- $acc_{sem}$,表示利用语义等价评估方法得到的结果;
- $acc_{ex}$,表示利用 SQL 执行结果进行评估的方法的得到的结果;
- $acc_{str}$,表示利用字符串匹配方法得到的评估结果;
- $acc_{syn}$,表示利用解析树匹配的方法得到的评估结果。
这个实验的目的是对比同一个模型在相同的数据集上用不同的评估方法得到的评估结果。这里选取的模型是 NSP 模型,因为它能生成复杂的 SQL 语句。从表中我们可以看出,不同的评估方法得到的结果差别很大,如果考虑复杂的 SQL 语句的话,这个差别将会更大。
6.2 简单 SQL 语句实验结果
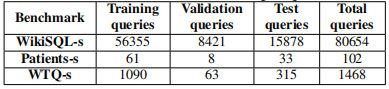
上表是用于验证简单 SQL 语句使用的数据集的统计数据。在所有数据集中,只有 WikiSQL、Patients和 WTQ 三个数据集包含了简单的 SQL 语句,将这三个数据集中的简单语句筛选出来形成新的数据集(加上 -s 后缀以示区别)。
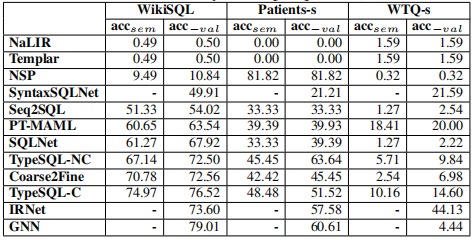 |
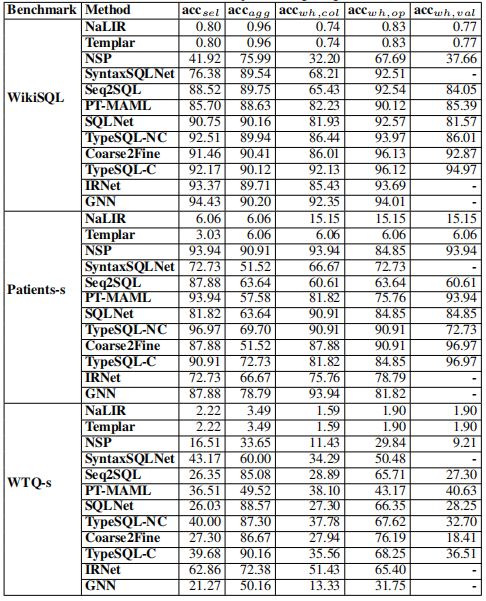 |
上表中,左边的表表示不同模型的总的表现,右侧表示每个单项的准确率,其中 $acc_{sel}$ 表示 SELECT 列的准确率,$acc_{agg}$ 表示聚合函数的准确率,$acc_{wh, col},acc_{wh, op}, acc_{wh,val}$ 分别表示 WHERE 条件中的列,操作符和值的准确率。
6.2.1 模型泛化性
从表中我们可以看出,基于规则的模型准确率都比较低。主要还是基于规则的方法有很大的限制性,比如 NaLIR,如果映射表中没有将 “longest” 映射成 $MAX$ 函数的方法,那么当自然问句中包含 “longest” 时就会出错。解决的办法就是尽可能的扩充映射表,但是这需要大量的人工工作。
NSP 作为基于深度学习的模型,其表现出来的水平较之其他深度学习模型差了很多。主要原因是它将 $S_D$ 作为输出词表的一部分,这样会有三个问题:
- 模型无法捕捉自然语言问句中的实体与数据表中实体之间的关系;
- 输出词表会很大,对解码器选择正确的输出造成困扰;
- 如果用于验证的语句中包含训练集中没有见过的实体,模型的处理效果就会很差。
而其他深度学习模型通常是将 $S_D$ 作为输入输送给模型进行处理,然后使用指针机制进行解码。这样就可以避免以上三个问题,最终的效果会好很多。
6.2.2 小数据集的模型鲁棒性
另一方面,我们会发现 NSP 在 Patients 数据集上的效果意外得好。通过分析发现, Patients-s 数据集的训练样本是最少的,NSP 的效果好是否跟它的数据增强技术有关呢?为了验证这个猜测,我们将 Patient-s 数据集利用数据增强技术扩展到 500。对比所有深度学习模型的表现,我们发现所有模型表现都有所提升,但是 NSP 的提升还是尤为明显。通过分析我们发现可能有以下几个原因:
- 由于其他深度模型是通过指针机制从自然问句中找出实体,如果自然问句中没有数据表中对应的实体,那么这些模型就不能生成正确的 SQL 语句了。比如错误案例中 (B)所展示的,数据表中是 “flu”,而自然问句中是 “influenza”,通过指针机制无法从自然问句中找到 “flu” 这个实体,自然就无法生成正确的语句了。而 NSP 模型是将数据表中的实体作为输出词表的一部分进行解码的,这样就可以正确找到 “flu” 这个实体了。
- 另外与 NSP 类似的将数据表实体作为输出词表的一部分的模型,比如 SyntaxSQLNet, GNN 和 IRNet 在小数据集上的效果也不如 NSP,主要原因是 NSP 的释义技术的应用。比如错误案例(A)中 NSP 可以准确的将 “hospitalization period” 映射到 “length_of_stay”,而另外几个模型就不能做到。
6.2.3 自然语言复杂性
自然语言的复杂性来源于多个方面:
- 语法多样性
- 领域多样性
- 目标 SQL 的多样性
- 句子数量
这里我们先讨论语法多样性和领域多样性。仔细看实验结果我们会发现,几乎所有的模型在 WTQ-s 数据集上的效果都比较差。主要是因为 WTQ-s 的数据集中自然语言问句比较多样,比如错误示例(C),不仅包含两个独立的条件,而且还有否定条件。这样的句子几乎现在所有的模型都不能处理。另外,如果数据表中的列名或者常数值比较复杂,也会导致问句比较复杂。比如错误示例(D)中列名是 “number of autos da fe”,这里面包含了非英文词汇,而这些词在词表中属于 OOV(Out of Vocabulary),导致模型无法准确辨别列名。
6.2.4 $q_{nl}$ 与 $S_D$ 的实体对齐
$q_{nl}$ 与 $S_D$ 的实体对齐对准确率的影响非常之大。在 WikiSQL 数据集上 GNN 的总体准确率是最高的,而在单项预测上 GNN 在预测列名的准确率也是最高的,因为在 GNN 模型中使用了实体链接技术。而使用标签化技术的 TypeSQL-C 和 IRNet 在列名的预测上,准确率仅次于 GNN,他们的总体准确率也是如此。
在 WTQ-s 数据集上,IRNet 的总体准确率是最高的,在单项上 $acc_{wh, op}$ 和 $acc_{agg}$ 与其他模型的准确率相比相差不多,但是在 $acc_{wh, col}$ 和 $acc_{sel}$ 上的准确率高出其他模型一大截。细致的分析我们会发现, IRNet 在长列名和表中有相似列名的时候表现尤为突出。比如错误示例(D)中,IRNet 是唯一预测正确的模型。
从以上的分析中我们不难发现,列名的准确性在很大程度上影响了模型的准确性。要提高模型预测列名的准确性,实体对齐是一个很有效的方法。而实体链接和标签化各有优势。
6.2.5 学习算法的有效性
在以上所有评估模型中,Seq2SQL 和 PT-MAML 分别采用了强化学习和元学习的方法。我们将这两个学习算法都改成监督学习以后发现,两个模型的准确率都有所下降。说明他们各自的学习算法都有利于发挥他们的能力,但是总体而言,强化学习和元学习在准确率上还是比其他深度学习模型准确率差一些。
6.3 复杂 SQL 语句实验结果
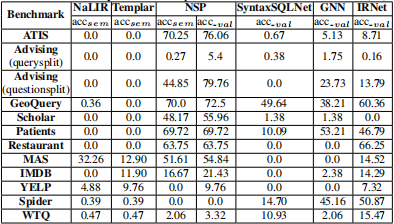
复杂 SQL 语句的实验只在上表中的六个模型上做的,因为其他模型都不支持 复杂 SQL 语句的生成。数据集排除了 WikiSQL,因为该数据集全部是简单 SQL 语句。总的来说,这些模型的准确率都很低。
6.3.1 基于规则的模型
基于规则的模型准确率低,主要的原因和前面简单 SQL 的问题一样。但是 Templar 比较有意思,它的准确率在除 MAS 数据集之外的所有数据集上的表现和 NaLIR 相差不大。经过分析我们发现,主要是在 MAS 数据集上 Templar 总是无法正确进行实体映射。给定两个实体 $qf_1$ 和 $qf_2$,如果 $qf_2$ 在检索日志中出现的频率更高的话,Templar 选择 $qf_2$ 的概率更高,即使可能 $qf_1$ 的语义更符合 $q_{nl}$。比如错误案例(E),“area” 与 “domain.name” 的语义相似度比 “publication.title” 更高,但是 Templar 选择了后者。
6.3.2 泛化性
SaI 方法总体效果强于 SaV 方法,主要原因还是输出词表的 OOV 问题。使用 SaI 方法的模型中, SyntaxSQLNet 的准确率比 GNN 和 IRNet 低很多,主要原因为后者使用了实体对齐技术。
6.3.3 小数据集上的模型鲁棒性
在小数据集上的表现和简单的 SQL 的情况类似,但是对于复杂 SQL 下,迷行表现更加糟糕。基于 SaI 的深度学习模型甚至无法训练处一个有意义的模型出来。这也从侧面说明,要想训练一个能处理复杂语句的深度学习模型需要大量的训练数据。
6.3.4 生成 SQL 的覆盖面
SyntaxSQLNet, GNN 和 IRNet 只能支持有限的 SQL,因为:
- SyntaxSQLNet 采用槽填充的方法,而槽的类型是预先定义的。预定义的槽类型严重限制了 SQL 语句的覆盖面。
- GNN 和 IRNet 是基于语法的模型,他们的表现比 SyntaxSQLNet 要好一些,但是也只能支持部分 SQL 语法。比如,不支持 LIMITE、ORDER BY、GROUP BY 等等。
NSP 也面临着类似的问题,随着复杂度和多样性的提升 NSP 生成的 SQL 的错误率也随之提升。通过分析发现,NSP 的主要错误来源于表名和列名的预测错误,而这些错误中主要集中在需要连表查询的时候。
6.3.5 自然语言问句复杂度
$q_{sql}$ 的复杂度随着 $q_{nl}$ 增加。目前所有的模型在面对复杂语句的时候准确率都非常低。
6.3.6 常数值的匿名化
在 Advising(question split)数据集上 NSP 模型 $acc_{sem}$ 和 $acc_{val}$ 准确率相差近 35%,这个差距非常大。而 35% 非常接近 NSP 在 WikiSQL 上对常数值的预测准确率。看下错误示例(F)我们会发现, NSP 的错误点在于将 “751” 预测错误。说明 NSP 没有正确地将 “751”匿名化。这给我们两点启示:
- NSP 的匿名化技术还有待提升;
- 精准的映射常数值也是提升模型准确率的有效手段。
7. NL2SQL 未来的发展
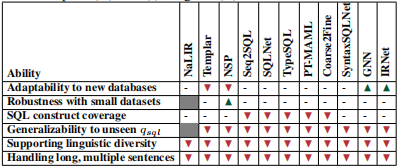
上表总结了目前的模型能力,红色倒三角表示模型表现很差,“-” 表示一般,绿色正三角表示表现很好。从上表中我们可以看出,没有一个模型能在所有问题上达到哪怕一般般的水平。因为每个模型都这或这或那的局限性。
对于跨领域的模型适应能力,需要将数据表实体当成模型输入而不是输出,但是在特定领域下,SaV 的效果会比 SaI 好。对于数据表实体的编码研究会是一个有意思的课题。(ps:将数据表实体既当输入也当输出?)
$q_{nl}$ 和 $S_D$ 实体对齐能有效提升准确率。但是目前的对齐方法还比较基础。字符串匹配的方式比词向量相似度的方法更加可靠,因为 $S_D$ 实体中可能包含很多词向量中没有的词。但是字符串匹配的方式容易造成过拟合,从实验结果中也可以看出来,IRNet 即使使用字符串匹配的方式,在 WTQ-s 数据集上的表现仍然很低,在更复杂的语句上准确率就更低了。
如何生成常数值也是一个具有挑战性的问题。即使使用匿名化技术,NSP 在 $V_D$ 比较多的情况下,表现也不尽如人意。
8. 总结
本文总结了 2014年-2019 年之间的 NL2SQL SOTA 模型。并综合性的做了对比实验,从实验中我们发现了一些规律:
- 表名,列名的预测准确性很大程度上影响了生成 SQL 语句的准确性;
- 实体对齐技术能有效提升表名\列名的准确性;
- 数据表实体作为输入和输出都有其优劣性,目前还没有同时作为输入输出的模型;理论上应该会有一定的提升;
- 匿名化技术对预测常数值有一定的帮助。
9. 参考资料
- Analyza: Exploring Data with Conversation,Kedar Dhamdhere, Kevin S. McCurley, Ralfi Nahmias, Mukund Sundararajan, Qiqi Yan
- Natural language to SQL: Where are we today?,Hyeonji Kim, Byeong-Hoon So, Wook-Shin Han, Hongrae Lee
- Semantic Parsing with Syntax- and Table-Aware SQL Generation,Yibo Sun, Duyu Tang, Nan Duan, Jianshu Ji, Guihong Cao, Xiaocheng Feng, Bing Qin, Ting Liu, Ming Zhou
- The history and recent advances of Natural Language Interfaces for Databases Querying,Majhadi, Khadija; Machkour, Mustapha
- NL2SQL概述:一文了解NL2SQL
- 试试中国人自己的Spider吧!
- Text-to-SQL Datasets and Baselines
- WIKISQL
- Spider
- CSpider
- Improving Text-to-SQL Evaluation Methodology,Catherine Finegan-Dollak, Jonathan K. Kummerfeld, Li Zhang, Karthik Ramanathan, Sesh Sadasivam, Rui Zhang, Dragomir Radev
- NaLIR: An Interactive Natural Language Interface for Querying Relational Databases,Fei Li,H. V. Jagadish
- Search-based test data generation for SQL queries,Jeroen Castelein, Maurício Aniche, Mozhan Soltani, Annibale Panichella, Arie van Deursen