神经网络三大神器:DNN、CNN、RNN。其中 DNN 和 RNN 都已经被用来构建语言模型了,而 CNN 一直在图像领域大展神威,它是否也可以用来构建语言模型呢?如果要用 CNN 构建语言模型应该怎么做?接下来我们从四篇论文看 CNN 构建语言模型的三种方法。
1. CNN 语言模型
简单的 CNN 语言建模思路如下:
- 首先输入的词经过 embedding 层,将每个词转化成句子矩阵 $x_{1:n} \in \mathbb{R}^{n \times k}$,其中 $n$ 表示句子长度,$k$ 表示词向量维度;
- 得到句子矩阵以后,用 $W \in \mathbb{R}^{w\times k}$ 的卷积核对句子矩阵进行卷积运算,一共有 $k$ 个卷积核;
- 经过卷积之后得到一个新的矩阵,然后在新的矩阵上使用
ReLu激活函数; - 接下来使用 batch normalization,为了解决内部协方差飘移问题;
- 然后经过一个 DNN 层进行降维之后直接使用 softmax 层输出,而不经过最大池化层,因为最大池化层会使句子丢失位置信息。
以上就是最基本的 CNN 语言模型的结构。除此之外,还有几个变种:
MLPConv
标准的 CNN 卷积操作是利用卷积核和特征矩阵进行线性变换。而 MLPConv 是在标准的卷积核后面接一个多层的 DNN 将原来的线性变换转化成非线性变换。需要注意的是,MLPConv 同样没有加入最大池化层。
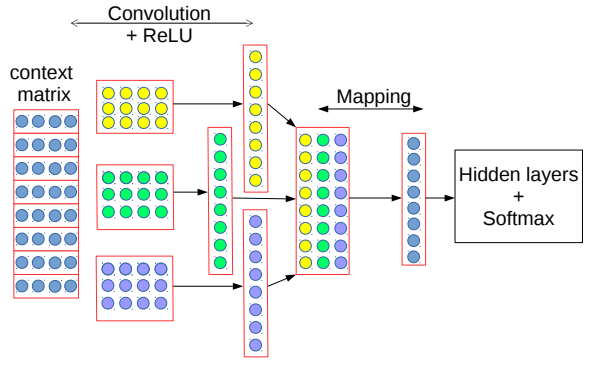
Multi-Layer CNN
将多个同尺寸卷积核的卷积叠加在一起,如下图左侧。
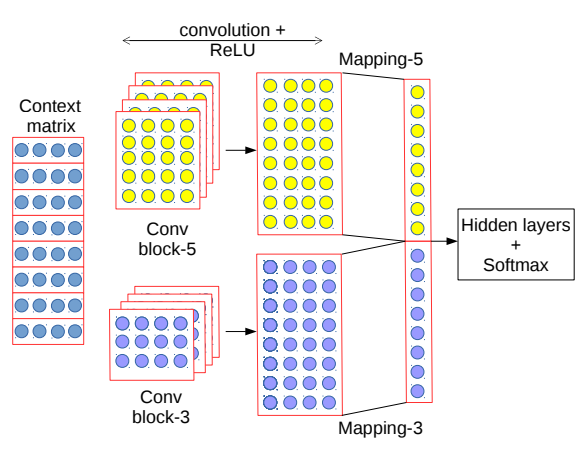
COM
将不同尺寸的卷积核的卷积拼接在一起,如下图右侧。
 |
 |
2. Gated-CNN 语言模型
2.1 $gen$CNN
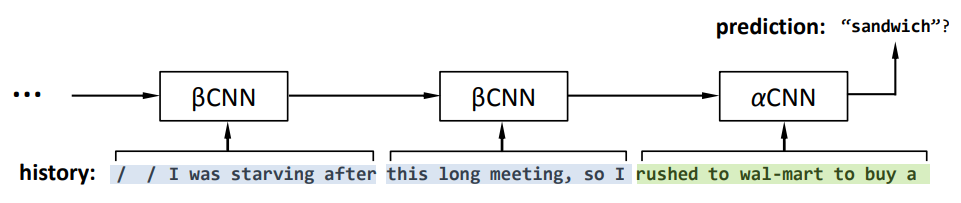
下图展示了 $gen$CNN 模型的大致结构:
- $\beta$CNN 用来记忆序列中较早之前的信息;
- $\alpha$CNN 用来处理距离需要预测的词最近的部分序列。
相对于传统 CNN,$gen$CNN 有两点不同:
- 部分权重共享策略;
- 用门控网络代替池化层。
接下来我们详细介绍一下模型的每一个部分。
2.1.1 $\alpha$CNN: 卷积
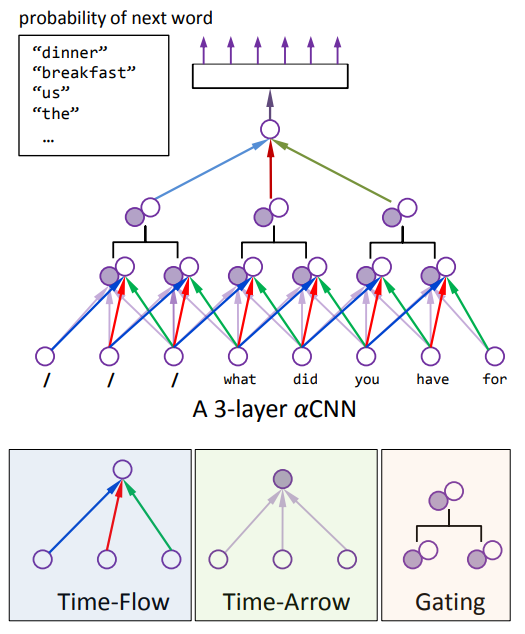
$\alpha$CNN 是部分共享权重的,在卷积单元中存在两种特征:Time-Flow 和 Time-Arrow,分别对应上图中的空心节点和实心节点。
Time-Flow:就是传统的 CNN,用来理解句子的整体时态结构;Time-Arrow:更像是基于 FFNN 的语言模型,用来理解句子的顺序。
假设输入句子 $\pmb{x}=(x_1, \cdots, x_T)$,第 $l$ 层的特征为:
其中:
- $z_i^{(l, f)}$ 表示第 $l$ 层网络第 $i$ 个位置的特征输出;
- $\sigma(\cdot)$ 表示
sigmoid函数或者Relu函数; - $W_{TF}^{(l, f)}$ 表示第 $l$ 层网络,$f\in \mathrm{Time-Flow}$ 的参数;$W_{TA}^{(l, f, i)}$ 表示第 $l$ 层网络第 $i$ 个位置,$f\in \mathrm{Time-Arrow}$ 的参数;
- $\pmb{\hat{z}}_i^{(l-1)}$ 表示第 $l-1$ 层第 $i$ 个位置的特征,令 $\pmb{\hat{z}}_i^{(0)}=[x_i^T, x_{i+1}^T, \cdots,x_{i+k-1}^T]$,$k$ 表示窗口大小。
2.1.2 门控网络

假设有一个第 $l$ 层网络的特征矩阵,然后再第 $l+1$ 层上加门控(窗口大小为 2)。门控网络定义是一个二分类逻辑回归器:
其中 $\bar{\pmb{z}}_j$ 表示第 $j$ 个窗口中将 $\hat{\pmb{z}}_{2j-1}^{(l)}$ 和 $\hat{\pmb{z}}_{2j}^{(l)}$ 融合在一起的矩阵。
然后将得到的值与特征矩阵进行加权求和:
这样就得到了 $l+1$ 层的特征矩阵。
- 窗口为 2,是因为网络包含两种特征
Time-Flow和Time-Arrow,每个窗口位置 $j$ 都包含两个窗口,所以用 $2j-1$ 和 $2j$ 表示;- 门控网络实际上是代替池化层做特征筛选,将卷积后的特征矩阵利用门控网络筛选出第 $j$ 个位置的特征到底是更偏向于结构信息还是更偏向于位置信息。
2.1.3 循环结构
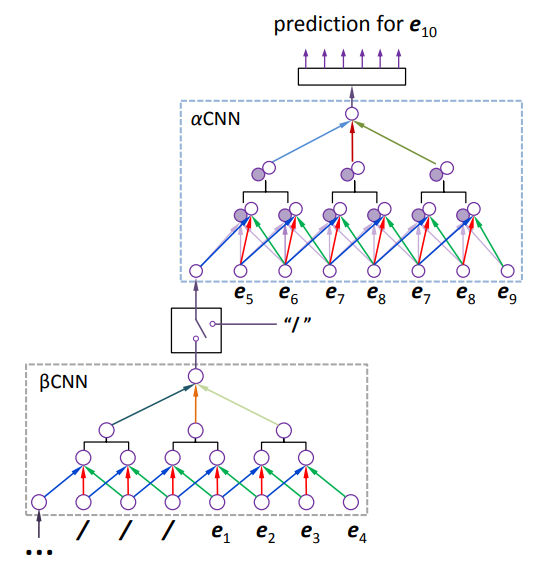
就像之前介绍的那样,我们处理使用 $\alpha$CNN 来获取当前信息以外,还会使用 $\beta$CNN 来记录历史信息。$\beta$CNN 只包含 Time-Flow 特征,得到 $\beta$CNN 特征之后将它作为 $\alpha$CNN 输入的第一个词输入给 $\alpha$CNN。所有的 $\beta$CNN 都是相同且循环对齐的,使得 $gen$CNN 能处理任意长度的句子。每个 $\beta$CNN 后面加一个特殊的开关,当没有历史信息的时候就会把开关关掉。
实验中 $\alpha$CNN 处理的句子长度为 $L_\alpha=30\sim40$,也就是说,如果句子长度短于 $L_\alpha$ 的话,那么模型就只包含了 $\alpha$CNN。实验中发现,90% 以上的句子可以只用 $\alpha$CNN 就可以, 超过 99% 的句子只需要一个 $\beta$CNN 就可以。实际上作者发现一个更大更深的 $\alpha$CNN 比 更小的 $\alpha$CNN 更多的 $\beta$CNN 结构表现更好。
2.2 Gated-CNN
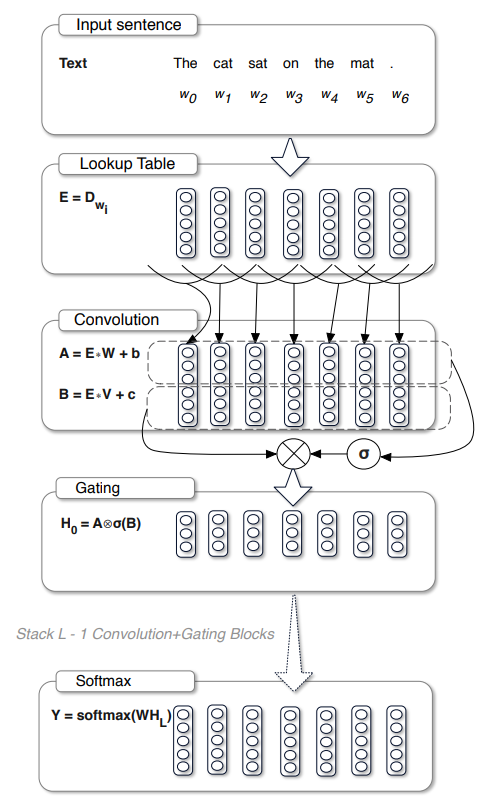
上图是 Gated CNN 模型的基本结构,大体上和传统的 CNN 语言模型区别不大,只是在 卷积之后加了一个门控机制:
其中 $\pmb{x} \in \mathbb{R}^{N\times m}$ 表示词向量组成的句子矩阵或者上一层网络的输出,$W \in \mathbb{R}^{k\times m\times n}$, $b \in \mathbb{R}^n$, $V \in \mathbb{R}^{k\times m\times n}$, $c \in \mathbb{R}^{n}$ 表示模型参数,$\sigma$ 为 sigmoid 函数,$\otimes$ 表示元素级相乘。
其实这就相当于决定每个特征值有多少信息可以进入下一层网络,和 LSTM 中的遗忘门作用相同。
2.3 小结
- 从 LSTM 出发到门控 CNN,我们会发现所谓门控其实就是通过 sigmoid 函数控制特征的传递。
- CNN 语言建模的关键在于不要使用池化层,因为池化层会丢失位置信息。
3. TCN 语言模型
TCN 模型即所谓的 Temporal Convolution Networks,该模型基于两个基本原则:
- 网络输出一个和输入序列等长度的序列;
- 不会发生从未来到过去的信息泄露。
为了达到第一点原则,TCN 使用 1D 全连接卷积网络:每一个隐层的长度和输入层相同,并且使用零填充保证后续的隐层也能保持和之前序列长度相同。
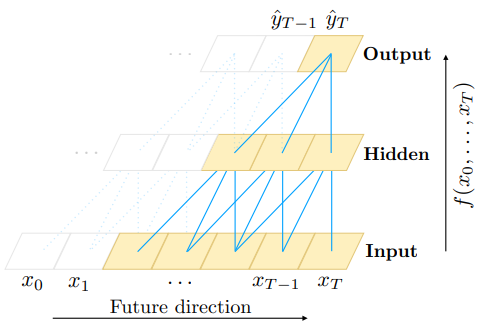
为了达到第二点目的,TCN 使用因果卷积(causal convolutions, 如下左图),即 $t$ 时刻的输出仅为 $t$ 时刻及之前的序列的卷积结果。
3.1 Dilated causal convolution
为了使模型能够足够深,且能处理足够长的序列,TCN 没有使用标准的卷积网络,而是使用的空洞卷积(dilated causal convolution,如下右图)。
 |
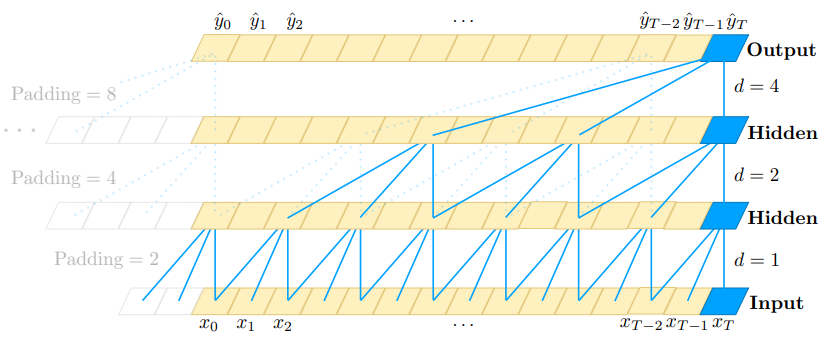 |
1D 空洞卷积的定义如下:
输入序列 $\pmb{x} \in \mathbb{R}^{n}$,卷积核 $f:\{0, \cdots, k-1\} \rightarrow \mathbb{R}$,在序列元素 $s$ 上的空洞卷积操作 $F$ 定义如下:
其中 $d$ 是空洞步长(或者空洞卷积的扩张率),$k$ 是卷积核尺寸。
使用空洞卷积可以使得上层的节点感受野更大,这样也就可以引入更多的历史信息。一般 $d$ 随着层数的指数增加,即 $d=O(2^i)$,其中 $i$ 为层数。每层计算卷积时相隔 $d-1$ 个位置。
TCN 的视野取决于网络深度,卷积核大小和空洞卷积的步长。比如,如果我们需要依赖前 $2^{12}$ 个历史信息来预测下一个词的话,就需要至少 12 层网络。为了防止梯度消失,TCN 还使用了残差网路。
3.2 Residual connection
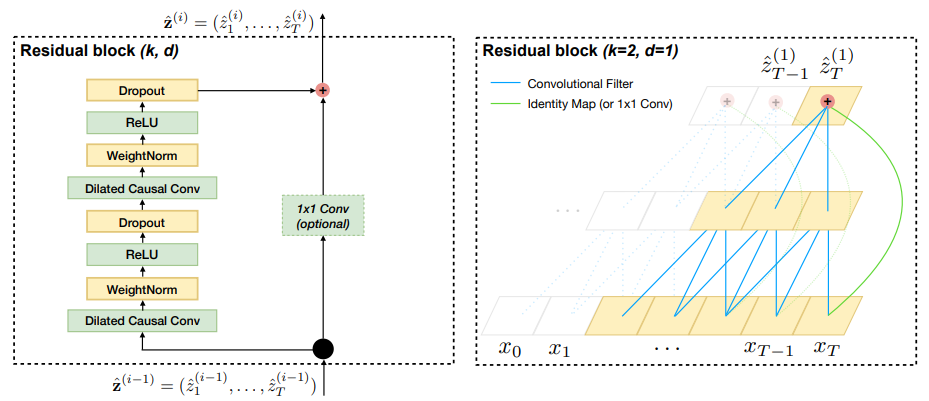
如上图所示,残差网络是训练深度模型常用的技巧,它使得网络可以以跨层的方式传递信息。TCN 构建了一个残差块来代替一层的卷积。一个残差包含两层的卷积和非线性映射,在每层中还加入了 WeightNorm 和 Dropout 来正则化网络。
3.3 TCN 的优点
并行性。当给定一个句子时,TCN可以将句子并行的处理,而不需要像RNN那样顺序的处理。
灵活的感受野。TCN的感受野的大小受层数、卷积核大小、扩张系数等决定。可以根据不同的任务不同的特性灵活定制。
稳定的梯度。RNN经常存在梯度消失和梯度爆炸的问题,这主要是由不同时间段上共用参数导致的,和传统卷积神经网络一样,TCN不太存在梯度消失和爆炸问题。
内存更低。RNN在使用时需要将每步的信息都保存下来,这会占据大量的内存,TCN在一层里面卷积核是共享的,内存使用更低。
3.4 TCN 的缺点
- TCN 在迁移学习方面可能没有那么强的适应能力。这是因为在不同的领域,模型预测所需要的历史信息量可能是不同的。因此,在将一个模型从一个对记忆信息需求量少的问题迁移到一个需要更长记忆的问题上时,TCN 可能会表现得很差,因为其感受野不够大。
- 论文中描述的TCN还是一种单向的结构,在语音识别和语音合成等任务上,纯单向的结构还是相当有用的。但是在文本中大多使用双向的结构,当然将TCN也很容易扩展成双向的结构,不使用因果卷积,使用传统的卷积结构即可。
- TCN毕竟是卷积神经网络的变种,虽然使用扩展卷积可以扩大感受野,但是仍然受到限制,相比 Transformer那种可以任意长度的相关信息都可以抓取到的特性还是差了点。TCN在文本中的应用还有待检验。
4. 总结
- 用 CNN 进行序列建模不要使用池化层,因为池化层会丢失位置信息;
- 门控 CNN 通常是用 sigmoid 函数进行信息控制;
- 空洞卷积可以扩展 CNN 的视野;
- 残差连接可以训练更深的网络。
5. Reference
Convolutional Neural Network Language Models, Ngoc-Quan Pham and German Kruszewski and Gemma Boleda
A Convolutional Architecture for Word Sequence Prediction, Mingxuan Wang, Zhengdong Lu, Hang Li, Wenbin Jiang, Qun Liu
Language Modeling with Gated Convolutional Networks, Yann N. Dauphin, Angela Fan, Michael Auli, David Grangier
Convolutional Sequence Modelling Revisited, Shaojie Bai, J. Zico Kolter, Vladlen Koltun