1. 简介
市面上的专业创建信息图表的工具虽然在努力平衡易用性和功能强大,但是这些工具通常是面向高级用户的,比如设计师、数据科学家等等。对于普通用户非常不友好。
普通用户通常有以下几个特点:
- 他们偶尔才会创建信息图表,对各种图表工具并不熟悉;
- 他们的目标不是设计美观、复杂、令人印象深刻的图表,而是需要一个专业、高效、能够准确说明问题的图表;
- 他们几乎没有设计经验,不知道如何从头开始设计图表。但是,给他们一些好的模板,他们能快速挑选符合心意的图表。
为了解决这类用户的需求,我们希望能够从自然语言描述中自动创建图表。为了达成这一目标,我们需要解决两个主要问题:
- 准确理解给定的语句并从中提取适当的信息;
- 利用提取出的信息创建图表。
为了解决以上两个问题,我们使用的技术方案是:
信息抽取解决方案
- 收集大量的真实用户数据;
- 对收集到的数据进行人工标注(序列标注);
- 利用标注数据训练一个基于 CRF 算法的模型(NER 模型)。
图表设计解决方案
利用从互联网上收集到的图表模板,分析其设计空间,提出了一套系统的设计方案。
本文提出的方法使用范围:适用于比例相关的语言描述,比如 “中国 2020 年 GDP 涨幅为 6%。”
2. 图表综述

一个合法图表单元应该具备以下四个特征:
- 至少能传达一条信息;
- 至少包含一个图形元素;
- 在视觉和语义上保持完整性和连贯性;
- 无法被拆分成更小的满足上面三个条件的单元。
上图中每个蓝色方框中表示一个图表单元。
根据从互联网上收集到的图表,我们将图表分成四类:
- 基于统计的图表:这是最主要的图表类型,这类图表通常包含,水平/垂直的柱状图、饼状图、甜甜圈图等;
- 基于时间线的图表:这类图表用来表示事件发展信息,通常包含,时间线、表格等;
- 基于过程的图表:这类图表用来告诉读者如何一步一步达到特定的目标,这类图表通常用在食谱或者操作手册上;
- 基于位置的图表:这类图表通常包含一个地图,地图上有一些标志、箭头、图例等信息。
在进一步分析基于统计的图表时,我们又将基于统计的图表细分成四个字类:
比例图表:用于表示某一部分占据总量的比例。通常在文本描述中会包含 “$n\%$”、“$m/n$”、“$m$ 分之 $n$”、“百分之 $m$” 等表述。这类图通常时柱状图、饼状图、甜甜圈图等。

数量图表:用于表示总量,比如收入、人口、速度等。这类图表通常不会使用饼状图、甜甜圈图,而是使用横向/纵向柱状图、象形图(pictographs chart)等;

变化图表:虽然变化图表通常可以用比例图标或者数量图表来表示,但是实际上变化图表和之前两种图表并不相同。变化图表的文本描述中通常会包含 “增长”、“下降” 等词汇,而图表通常会有不同的颜色、图形等的一一对比;

排名图表:这类图表中通常会包含星星、奖牌、奖杯等图像,而文本描述中通常会出现序数词,“第一名”、“前十名”等等。

对于基于统计的图表,通常一个图表只包含一个信息,但是有些图表在一个单元内包含多个信息。根据包含的不同信息,我们将图表分成四类:
- 单实例图表:这种是最简单的
- 合成图表:这类图标指的是用多个子图表形成一个完整的图表。比如文字描述 “中国2013年的总人口是14亿,较 2012 年的 13.5 亿增长了 10%。” 这段文字中的粟裕偶数字都是用来描述中国总人口的。
- 对比图表:多个实例进行对比,通常会使用颜色、图标、尺寸、形状等进行区分;
- 累积图表:这种图表有点类似于对比图表,但是不同的是,不同的主体会形成一个较大的整体。比如 “中国生产了美国大选所需的所有美国国旗,其中义乌生产了 70%,上海生产了 30%。”
3. 比例相关的图表
3.1 文字描述
- 从网上爬取了 10 万 PPT 数据;
- 利用规则从 10万 PPT 数据中抽取 5562 条描述语句;
- 主要规则包含: “$n\%$”、“$m/n$”、“$m$ 分之 $n$”、“百分之 $m$” 等。需要注意的是,包含这些关键词的句子并不一定是比例图标,比如 “公司营收增长了 50%。”显然应该属于变化图表;
- 从 5562 条规则抽取的文本中,经过人工筛选得到 800 条比例图表相关语句;
- 我们对比了 PPT 里面的语句和文章当中的语句,我们发现PPT里面的句子更加精炼,因此,没有在训练数据中添加文章句子。
3.2 图表可视化
图表可视化设计的四要素:布局、描述、图形、颜色。
布局
图表布局分两种:
单实例(最常见)。单实例的图表通常包含一个图形和一段描述性的语言。这样的图表通常采用的布局是网格布局,便于图形和描述性文字的对齐。
多实例。将多个实例组合成一个图表通常采用四种策略:
- 并排(side-by-side)。为了表示对比、层级或者其他逻辑关系,多个实例通常采用网格布局,包括平行、并列、循环、层级和堆积等(下图a)。
- 共享轴(share-axes)。这种布局通常是将多个实例进行对齐,然后放到一个通用的坐标系统下。通常用在带坐标轴的统计图表里,比如条形图、散点图等(下图b)。
- 共享中心(share-center)。这种布局将多个数字实例以同一个圆心排列成圆形或者扇形。通常用在饼状图、夜莺玫瑰走势图(Nightingale rose charts)等上(下图c)。
- 共享文本(share-context)。这种布局将图表上不同的区域使用相同的注释加以说明。通常用在注释图表中,将注释放在公共空白区域(下图a)。

文本描述
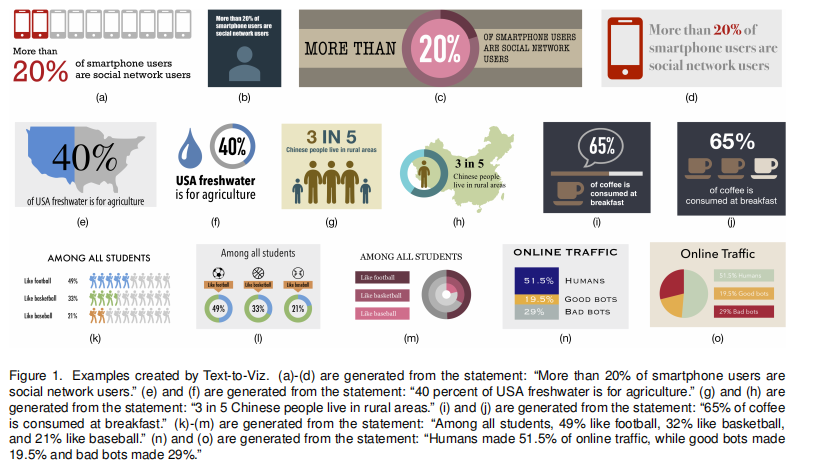
前面我们对比例图表的定义是,用来表示某一部分占据总数的比例。那么在比例图表的文本描述中就应该包含三个关键信息:数值、局部、整体,实际上图表设计师通常会在数值前面加上一个修饰词,比如 “大于”、“小于” 等。除了这四种类型(包括修饰词)的描述,我们还发现了下面一些通用形式的描述:
- 完整描述。
- 在描述中数字被省略了。比如,“40 percent of USA fresh water is used for agriculture” 中的 “40 percent” 被省略。(ps: 我没有找到合适的中文例子)
- 局部是一个动词词组。比如,“65% 的咖啡是在早餐中消费掉的”, 其中 “消费掉” 作为局部,是一个动词词组。
- 数值-整体组合。比如,“65% 的咖啡是在早餐中消费掉的” 中的 “65% 的咖啡” 就是一个数值-整体组合。
- 文本描述以数值为界被分割开了。比如,“中国只有”,“10%”,“的人有本科学历”(ps: 同样没找到比较合适的中文例子)。
图形
图形部分涉及两点:图形的选择和组合。图形设计主要考虑两点:
- 图形应该与原始的文本描述具有语义相关性;
- 图形的不同元素应该具有不同的作用。(ps: 不同的元素表示相同的信息的话容易造成混淆)
根据已有的比例图表,我们将最常使用的图形分成七大类:象形图(下图a)、装饰图(下图d)、圈图(下图c)、饼状图(下图o)、条形图(下图i)、填充图标(下图e)、缩放图标(下图g)。

颜色
颜色设计的通用规则是:
- 前景和背景颜色:背景颜色占据绝大多数区域;前景颜色更加多样;不同文本框的文本描述使用相同的颜色;图形元素可以使用一种或者多种颜色,视情况而定。比如,象形图、饼状图等至少需要两种颜色,而装饰图标只需要一种颜色。
- 数字高亮:常见的高亮方法包括尺寸、颜色和字体。
4. Text-to-Viz 技术实现方案
系统包括两个主要模块:文本分析模块和可视化生成器模块。首先用户输入一段文本,然后文本分析模块对文本进行分析,从中抽取 修饰词、数字、局部、整体 等信息。然后将原始文本和从文本中抽取出的信息一同输入给可视化生成器模块。可视化生成器模块生成或者选取合适的 布局、描述、图形、颜色,然后将这些元素组合成一系列可用的图表。对生成的图表进行评估和打分,根据打分的高低进行排序,呈现给用户,让用户进行选择。
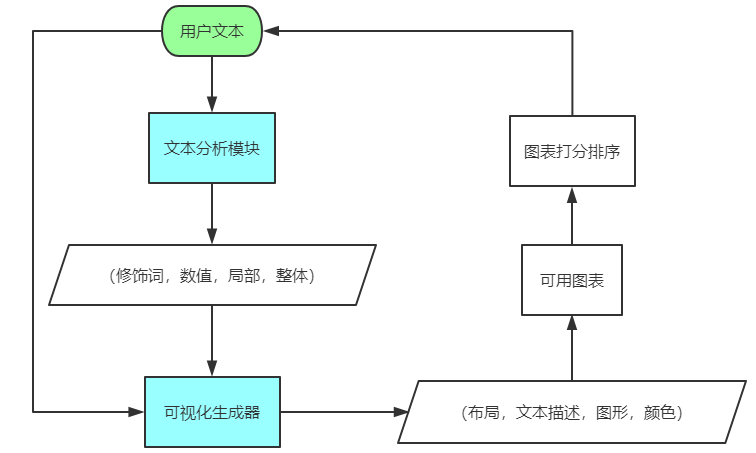
4.1 文本分析模块

预定义四种实体:修饰词(Modifier)、数字(Number)、局部(Part)、整体(Whole)(ps: B-M、I-M、B-N、I-N、B-P、I-P、B-W、I-W、O一共需要九个输出)。利用命名实体识别模型对这四种实体进行识别抽取。本文使用的命名实体识别模型是 CNN+CRF 模型。主要包括一下三步:
- 分词:“中国 GDP 上涨 6%。” -> [”中国“,”GPD“,”上涨“,”6%“,”。“]
- 特征化:将分词后的结果映射成词向量序列
- CNN+CRF:一维 CNN,$kernel_size=(9\times m)$,本文中 $m=59$。
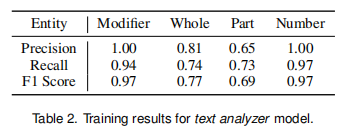
训练结果:
4.2 可视化生成模块
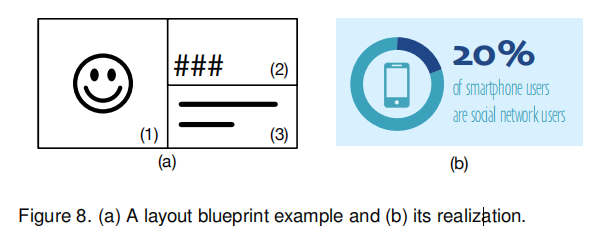
4.2.1 布局
布局设计需要解决两个问题:
- 如何分割区域?
- 每个区域需要填充什么样的信息?
以上图为例,我们可以通过人为设计规则来解决以上两个问题:
- 如果用户的文本描述是以数值开头的,那么我们将区域分成上图 $2\times 1$ 的形式;
- 区域1 填充象形图、图标、饼状图等;
- 区域2 填充文本描述中的数字信息;
- 区域3 填充删除数字信息后的用户输入文本
我们通过分析收集到的数据,预先定义了 20 套布局模板作为项目启动数据。然后针对每一套布局模板都制定了相关的规则。
4.2.2 描述
基本的描述信息通过文本分析模块已经得到了,剩下一些补充描述我们利用 Stanford Parser 对用户文本进行语法分析得到一个语法树。然后根据不同的布局,从语法树中抽取不同的内容。
4.2.3 图形
在我们的实现中,我们构建了一个图形库,包含 100 个图形,每个图形都人为添加一个或多个关键词用来表示该图形的语义信息。然后将局部和整体的内容进行行分词、删除停用词,然后用 word2vec 进行词义匹配,找个最合适图形。
4.2.4 颜色
颜色生成考虑两方面:
- 所有选用的颜色组合起来应该是协调的;
- 如果搭配的颜色与文本描述的内容相搭就更好了,比如文本描述保护环境,我们选择绿色和蓝色。
在我们的颜色生成模块中,同样是人为构建了一套颜色系统,给每个颜色系统打上标签,包括前景、背景、高亮等。颜色系统设计可参考 Adobe 颜色 和 Coolors。然后根据标签设计规则,只当每种颜色系统的使用条件。
4.2.5 合成
遍历所有生成的布局、描述、图形、颜色,将这四元素组合。比如,可视化生成模块生成结果如下:
- 布局 =
[layout1, layout2] - 描述 =
[description1, description2, description3] - 图形 =
[graphic1, graphic2] - 颜色 =
[color1]
将上面的元素组合起来得到一个候选集:
1 | 候选集 = [ |
得到候选集以后根据以下规则进一步处理:
- 用户的输入文本不满足布局模板所需要的元素。比如,某个布局模板需要修饰词(比如 ”大于“),但是在用户文本中没有出现修饰词,那么我们就将这个布局模板的组合删掉。比如将候选集中所有包含 layout1 的组合删掉。
- 抽出描述和图形,计算他们的横纵比,将他们缩放到一个合适的尺寸,放到布局模板中。这个问题可以通过 Badros 等人提出的方法去解决。
- 挑选合适的字体,然后将所有元素进行对齐。
4.2.6 重排
综合考虑三种评分机制:语义得分、可视化得分和信息得分。
语义得分:由于图形和颜色的选取是通过标签语义匹配得到的,因此,得分越高说明匹配度越高。word2vec 计算词义距离 $\alpha_s \in [0,1]$,0 分说明语义和图形或者颜色毫无关系,1 分说明非常契合。
可视化得分:由于图形和描述的尺寸与布局不一定相称,所以可视化得分也是我们考虑的因素之一。我们通过计算可视化元素中空白区域的占比来衡量可视化得分:
信息得分:通过信息得分来衡量图表是否包含了用户描述的所有信息。定义如下:
其中 $S$ 表示用户描述文本中的所有非停用词,$I(w)$ 的定义如下:
有了上面三种评分方式,候选集中每种组合方式最后的总得分为:
默认情况下,令 $w_s=0.25,w_v=0.5, w_i=0.25$。
最后我们根据每种组合最后的得分对候选集中的图表进行重排,然后推荐给用户。
需要注意的是,我们要支持用户对图表进行编辑,改变布局、描述、图形、颜色等。
5. Text-to-Viz 实际效果