自从 2017 年 Vaswani 等人提出 Transformer 模型以后 NLP 开启了一个新的时代——预训练语言模型。而 2018 年的 BERT 横空出世则宣告着 NLP 的王者降临。那么,什么是预训练?什么是语言模型?它为什么有效?
在本系列文章中我们将会讨论跟预训练语言模型相关的技术。目前初步制定的计划如下:
一、前言
二、语言模型
三、NLP 中的迁移学习
四、预训练语言模型
五、预训练语言模型的应用
六、预训练语言模型的压缩
大体分成以上六个部分,本文为第一部分,将会对预训练语言模型的发展、技术路线做一个综述,使得我们能对这一领域有一个整体的认识。
1. 语言模型
狭义上的语言模型就是对自然语言进行建模,自然语言指的是人类文明演化过程创造的用于人与人交流的语言,不包括编程语言等。自然语言通常包含语音和文字,语言模型指的是对文字进行建模。广义上来说,语言模型可以用来对任意的系列化结构进行建模。这里我们讨论的是狭义上的文字语言模型。
语言模型简单来讲就是让计算机判断一个词序是不是正常的句子,如果是则给出高概率,反之则给出低概率。本质上就是构建一个词序概率分布,一个序列的概率由序列中每个词出现的概率相乘得到,而每个词出现的概率由其前后出现的词来确定。用形式化语言描述为:
给定一个词表 $\mathcal{V}$,对于序列 $s = w_1w_2…w_n$,其中 $w_i \in \mathcal{V}, i \in {1, …, (n-1)}$ 以及 $n \ge 1$,$w_n$ 通常是一个特殊符号,用于标志序列的结束。语言模型可以定义为:
语言模型在 NLP 领域有广泛的用途,比如机器翻译过程中,模型给出几个候选翻译结果,然后再根据语言模型选出最符合自然语言的句子,使得翻译结果更加流畅。
1.1 统计语言模型
在神经网络技术出现之前,人们通常是使用统计学方法从训练语料中去学习模型参数,因此此时的语言模型也称为统计语言模型(Statistical Language Model)。
标准的语言模型存在两个问题:
- 参数空间过大。假设序列中的词全部来自 $\mathcal{V}$,那么对于一个长度为 $n$ 的序列来说,模型具有 $\mathcal{V}^n$ 个自有参数。我们可以看出,模型的自由参数随着序列长度增加成指数级增长。
- 数据稀疏性。表面上看,序列中的每个词都具有 $\mathcal{V}$ 种可能的取值,那么长度为 $n$ 的序列可以有 $\mathcal{V}$ 种组合方式,但是实际上我们的语料不可能出现这么多种组合。
因此,直接对上面的语言模型进行求解几乎是不可能的,我们需要对问题进行一些合理的假设,从而简化模型。
n-gram 语言模型
马尔科夫假设:
句子中第 $i$ 个词出现的概率只依赖于前面 $i-1$ 个词。
我们将这个假设再进一步弱化:
句子中第 $i$ 个词出现的概率只依赖于前面 $n-1$ 个词,其中 $n \le i$。
基于这个假设,我们就能够理解 n-gram 中的 n 实际上就是前面 n-1 个词的意思。(为啥说是 n-1 个词呢,因为通常认为第 n 个词表示第 i 个词本身)
比如:
$n=1$ uni-gram: $p(w_1, w_2, …, w_n) = p(w_i)$
$n=2$ bi-gram: $p(w_1, w_2, …, w_n) = p(w_1)\prod_{i=2}^np(w_i|w_{i-1})$
$n=3$ tri-gram: $p(w_1, w_2, …, w_n) = p(w_1)\prod_{i=2}^np(w_i|w_{i-2},w_{i-1})$
…
$n=n$ n-gram: $p(w_1, w_2, …, w_n)=p(w_1)\prod_{i=2}^np(w_i|w_(i-1),…,w_{i-n+1})$
在实际应用中,$n$ 的选取通常从计算复杂度和模型效果两个方面去考虑,假设 $|\mathcal{V}| = 2 \times 10^5$, 下表给出了常见的 $n$ 的取值对应的计算复杂度和模型效果:
| n-gram order | 模型参数量 | perplexity |
|---|---|---|
| $1$ | $2 \times 10^5$ | $962$ |
| $2$ | $(2 \times 10^5)^2=4 \times 10^{10}$ | $170$ |
| $3$ | $(2 \times 10^5)^3 = 8 \times 10^{15}$ | $109$ |
| $4$ | $(2 \times 10^5)^4=16 \times 10^{20}$ | $99$ |
上表中 perplexity 表示语言模型的评估指标,值越小表明语言模型越好。
从表中我们可以看出,随着 $n$ 增大,模型参数量级是指数增加的,在实际应用中通常采用 $n=3$。
尽管 n-gram 模型将参数量大大降低,但是技术的发展,尤其是互联网技术的发展,我们可以轻松获得大量的语料。对于语言模型来说,一个基本的事实是语料越多模型效果越好,但是另一方面,模型的参数量也会随着词表的增大而剧增,这样就极大的限制了语言模型的发展。
1.2 神经网络语言模型
为了解决上述问题,人们开始考虑使用神经网络技术将语言模型映射到连续空间中,我们称之为“语义空间”。
最早提出使用神经网络对语言进行建模思想的是百度徐伟,在其 2000 年的论文《Can Artificial Neural Networks Learn Language Models?》提出一种构建 2-gram 语言模型($p(w_i|w_{i-1})$)的方法。该方法的基本思路与后来的神经网络语言模型的建模方法已经差别不大了,但是由于他采用的是只有输入层和输出层,而没有隐藏层的神经网络,且只是二元语言模型,因此限制了其模型泛化能力和上下文语义捕捉能力。
到 2003 年 Bengio 等人提出了真正意义上的神经网络语言模型(Feedforward Neural Network Language Model, FFNNLM),该模型采用四层神经网络来构建语言模型——输入层、投影层、隐藏层和输出层。该模型不仅解决了统计语言模型的维度灾难问题和稀疏性问题,同时还诞生了一个非常重要的副产物——词向量(word vector)。词向量我们会在下文详细介绍。
直到 2010 年,Mikolov 等人提出基于 RNN 的语言模型。自此,神经网络语言模型逐渐成为语言模型的主流并得到快速发展。
2012 年,Sundermeyer 等人提出使用 LSTM 构建语言模型,用来解决长程依赖问题。
随后的时间,各种神经网络语言模型如雨后春笋般涌现,用来解决各种各样的问题。直到 2018 年,以 ELMO、GPT 和 BERT 为代表的语言模型的出现,正式宣布预训练语言模型时代的到来。本小节先不讨论预训练语言模型的相关内容,留待下文讲解。这里我们先简单介绍一下 FFNN、RNN 、LSTM 三种里程碑式的语言模型的发展,为后续预训练技术在语言模型上的发展奠定基础。
1.2.1 FFNN 语言模型
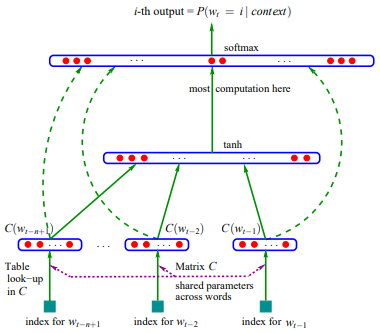
Bengio 等人 2003 年提出的第一个 FFNN 语言模型结构如上图所示。图中最下方表示输入层,$w_{t-n+1}, …, w_{t-2}, w_{t-1}$ 表示前 $n-1$ 个词。上面一层表示投影层,$C(w)$ 表示将词投影到相应的词向量上,$C$ 表示一个大小为 $|\mathcal{V}| \times m$ 的词向量矩阵,矩阵中每一行对应词表中的一个词的词向量,$m$ 代表词向量的维度。实际上 $C(w)$ 就表示从 $C$ 矩阵中找到 $w$ 对应的向量。将词映射成词向量以后,将 $C(w_{t-n+1}),…,C(w_{t-2}), C(w_{t-1})$ 这 $n-1$ 个词向量首尾相接,得到一个 $(n-1)\times m$ 维的向量,记为 $x$。第三层为隐藏层,通过下式计算得到:
其中,$H \in \mathbb{R}^{h \times (n-1)m}$。最后就是输出层:
其中 $U \in \mathbb{R}^{|\mathcal{V}|\times h}$,$W \in \mathbb{R}^{|\mathcal{V}| \times ({n-1})m}$。
FFNN 语言模型存在以下几个问题:
- 不能处理变长句子序列。由于输入层的神经元是固定的,因此模型必须输入固定长度的序列。
- 由于输入序列长度是固定的,因此,模型只能对固定长度的上下文进行建模,而不是对整段序列进行建模。
- 序列中的词没有包含位置信息,而实际上我们知道,对于相同的几个词,放在不同的位置整句话就会表达不同的意思。
- 尽管全接连神经网络需要学习的参数量远小于 n-gram 但是相比于其他结构的神经网络,其参数量还是过大。
因此,Bengio 在论文最后提到,可以使用循环神经网络(RNN)来降低参数量。这就是后来 Mikolov 提出的 RNN 神经网络。
1.2.2 RNN 语言模型
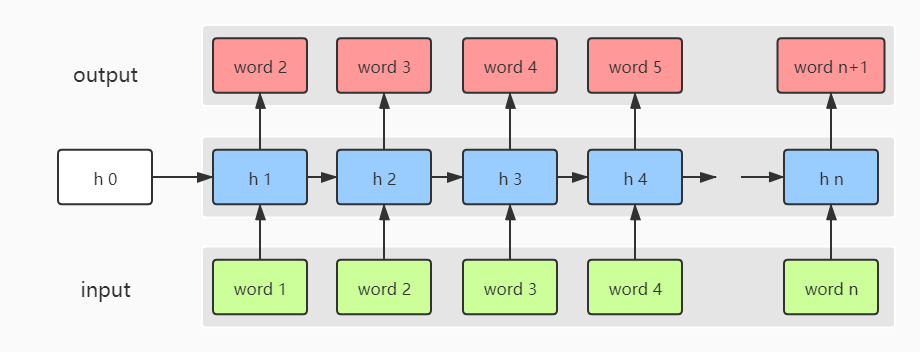
Mikolov 等人提出的 RNN 语言模型,将一个 RNN 神经网络展开,得到如上图所示的结构。每个时间步,句子中的当前词经过隐层编码预测下一个词。注意 $h_0$ 通常是零向量进行初始化。由于隐层 $h_t$ 的传递性, RNN 语言模型实际上就相当于 n-gram 语言模型,而这个 n 是一个变量,即整个句子的长度。这样避免了马尔科夫假设,使得我们能够得到更加精准的语言模型。
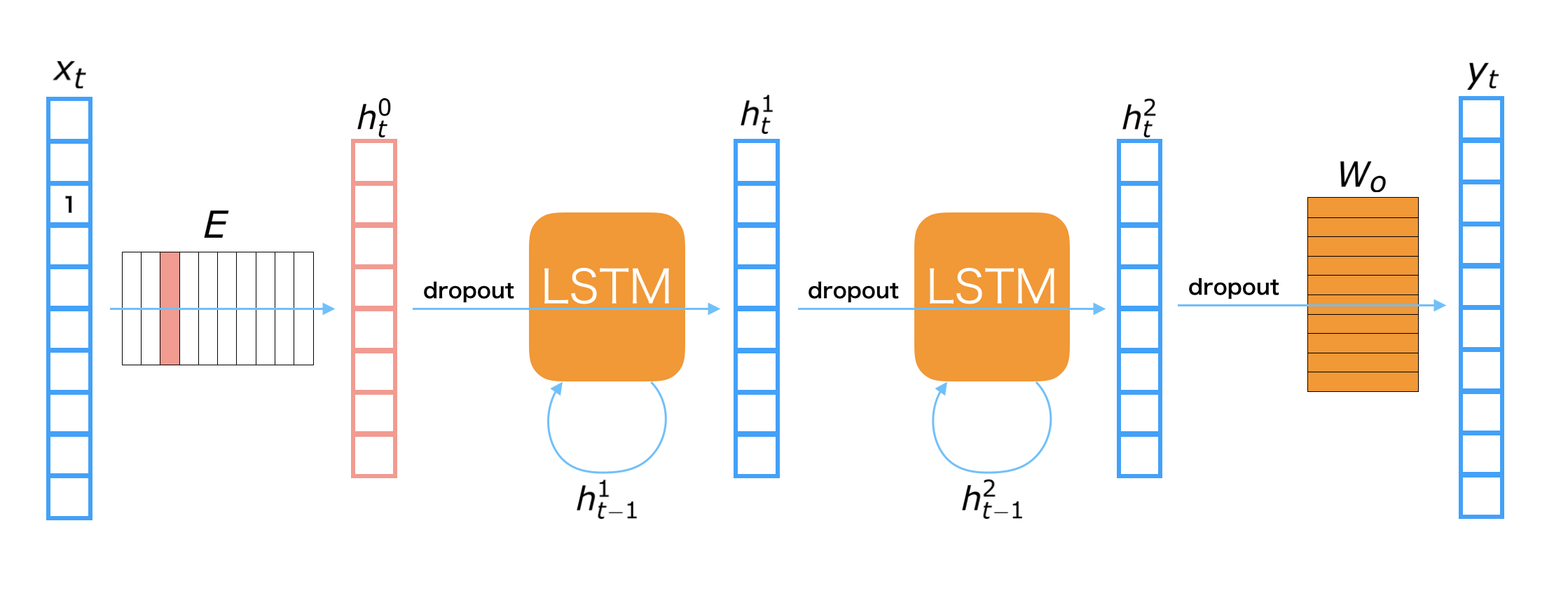
我们将其中一个时间步展开可得到如下图所示的结构:
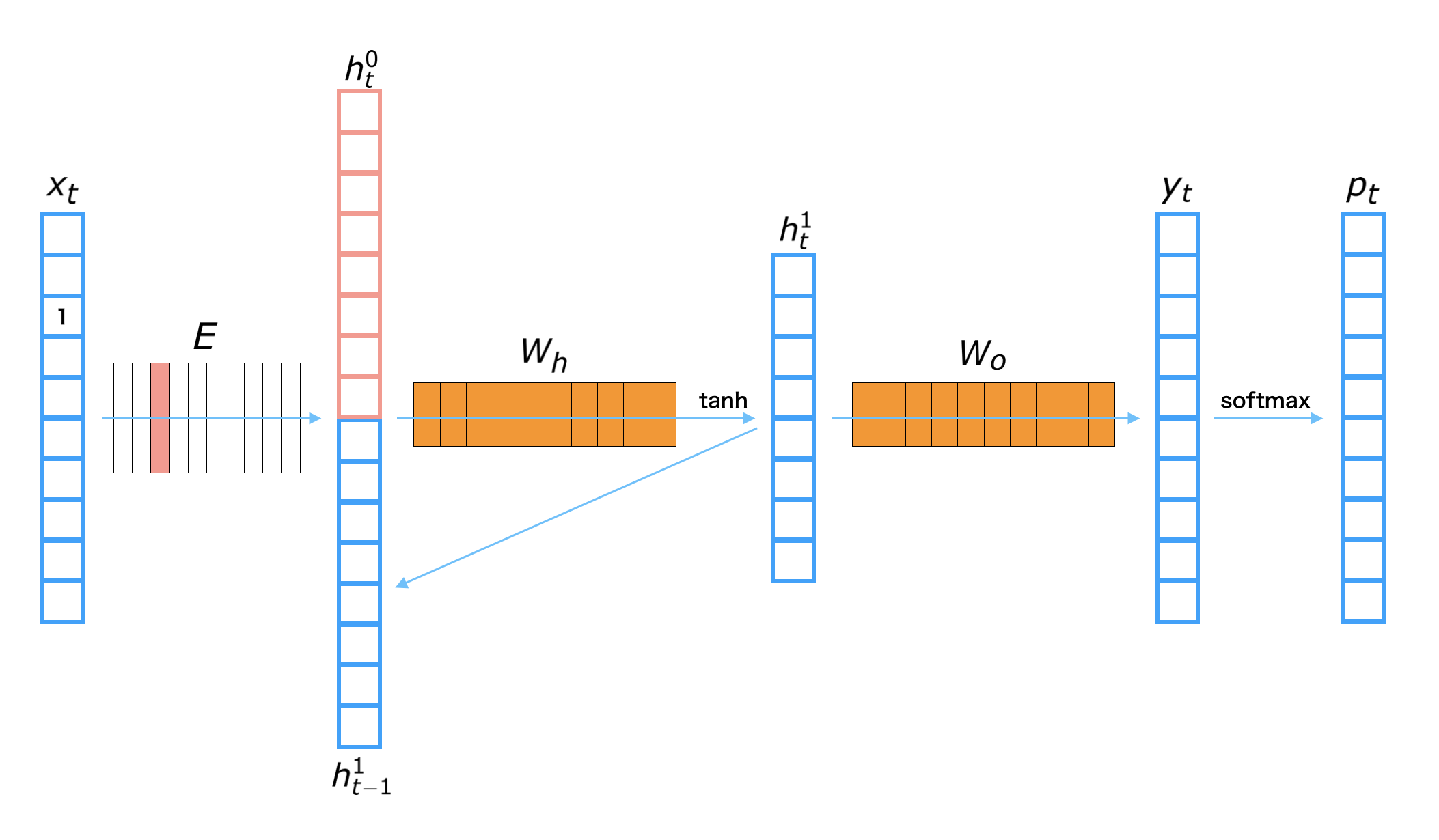
其中 $x_t$ 表示第 $t$ 个词,$y_t$ 表示第 $t$ 个词经过编码以后的输出,$h_t^{(i)}$ 表示第 $t$ 个隐藏层的第 $i$ 层,$p_t$ 表示通过第 $t$ 个词预测的第 $t+1$ 个词,$E$ 为词向量矩阵,$W_h$ 和 $W_o$ 分别表示隐层和输出层的权重矩阵。计算过程如下:
- 将词映射成词向量:$h_t^{(0)} = Ex_t$
- 隐层编码:$h_t^{(1)} = \tanh(W_h[h_t^{(0)};h_{t-1}^{(1)}]^T)$
- 计算输出层:$y_t=W_oh_t^{(1)}$
- 计算输出概率:$p_t=\mathrm{softmax}(y_t)$
注意:$[h_t^{(0)};h_{t-1}^{(1)}]^T$ 表示 $h_t^{(0)}, h_{t-1}^{(1)}$ 两个向量的首尾拼接。
相比于 FFNN 语言模型,RNN 语言模型能够处理变长序列,相当于对整个句子进行编码,即根据句子前面所有的词来预测当前词。这样我们能够获得更加准确的语言模型。另外由于隐层是共享权重的,因此语言模型的参数量被大大降低了。
虽然 RNN 语言模型有诸多优点,但是也存在严重缺陷。最棘手的问题是由于神经网络梯度消失或者爆炸导致模型在处理远程依赖问题上的无能为力。为了解决这个问题,Sundermeyer 等人提出了 LSTM 语言模型。
1.2.3 LSTM 语言模型
LSTM 是 RNN 的一种变体,包含了三个门结构:输入门,遗忘门和输出门。对于神经网络而言,造成梯度消失或者梯度爆炸的罪魁祸首是过深的连乘结构,而 LSTM 通过这三个门结构将原来的连乘结构,一部分连乘改成了加法形式,从而缓解了梯度消失或者爆炸问题。LSTM 语言模型就是利用这种特性对语言进行建模从而能够更好的处理长程依赖问题。
尽管 RNN 、LSTM 语言模型表现良好,但仍然存在一系列问题,比如训练慢、OOV 问题、softmax 需要考虑全部词表等等,后续的研究也在一步一步提出更加完善的语言模型。但无论如何,以这三种经典的神经网络语言模型为基础,神经网络语言模型正在蓬勃发展,这也为后来的预训练语言模型打下了坚实的基础。
2. 预训练
自然语言处理技术的发展大体经历了:基于规则处理方法、基l于统计概率的处理方法和基于神经网络的处理方法三个阶段。尤其是随着神经网络技术的发展,自然语言处理在各项任务上也取得了突飞猛进的发展。然而 Jia and Liang, 2017 和 Belinkov and Bisk, 2018 的研究指出,基于神经网络的 NLP 算法在泛化性上仍然非常脆弱,模型只能对在训练数据中“见过”的特征进行建模,一旦遇到“未见过”的数据,模型就会失效。
为了解决(或者说缓解)这个问题,通常的做法是使用更大的数据集去训练模型,但是这样又带来一个问题,训练神经网络模型通常是需要大量的标注数据的,更多的训练数据意味着更多的人工标注,使得训练模型的成本大大增加。
我们希望训练好的模型能够将学习到的知识应用到具有相似性的问题上去,即使新的问题在训练数据中从来没有出现过,就像人类一样具有“举一反三”,“照猫画虎”的能力,这样模型的泛化能力将会得到大大的增强。而这正是迁移学习的思想,预训练则可以认为就是一种迁移学习。
预训练首先在图像领域发光发热,这就不得不提 ImageNet。
2.1 ImageNet
早期的目标识别任务面临一个过拟合的问题,因为当时训练模型的数据集都非常小。斯坦福大学的李飞飞受到 George Miller 的 WordNet 的启发,决定构建一个能够”覆盖世界上所有物体”(map out the entire world of objects)的数据集。
ImageNet 项目正式启动于 2007 年,在短短三年的时间内构建了 300 多万张经过人工标注的图片,并将图片分成 5000 多个类别。2012 年,多伦多大学的 Hinton 研究小组发布了深度卷积神经网络(CNN)—— AlexNet,该网络在 ImageNet 上将错误率下降到 25%,这直接导致了深度学习的爆发。
研究人员很快发现,在 ImageNet 上训练好的最佳模型的权重参数可以被用来初始化新的模型,然后在新的数据集上进行训练,而且这种方法可以明显提升模型的能力。这一发现就为图像识别的打开了预训练方法的大门。
假设我们有一个任务 A,但是用于模型训练的数据十分匮乏并不能直接从头开始训练一个模型。但是我们有大量的其他类型的数据,这个时候我们可以先试用这些数据训练一个模型, 然后使用这个模型的权重来初始化我们的任务模型,然后在我们自己的任务数据上再训练模型,这样可以极大的加快模型收敛速度,同时提升模型效果。我们将在大数据集上训练模型的过程称之为“预训练(Pre-Training)”,将在我们自己的数据集上训练的过程称之为“微调(Fine-Tuning)”。
具体的做法如下:
- 假设我们想要一个图像分类器,用于区分“大象”和“狮子”,但是“大象”和“狮子”的图片很少,但是我们有大量的“斑马”和“猴子”的图片,这个时候我们可以使用 CNN 先在“斑马”和“猴子”的图片上训练一个分类器。将训练好的权重参数保存下来。
- 然后采用和上面相同结构的网络模型,在比较浅的几层采用上面预训练模型相应层的权重作为初始化权重,在接近任务端的较深的几层仍然采用随机初始化。
- 之后我们就可以训练这个“大象”和“狮子”的分类器了。通常有三种训练方法:① 浅层加载的参数在训练过程不参与训练,称之为 “Frozen”;② 浅层加载的参数也参与训练,但是学习率会小于深层随机初始化的参数,使得浅层参数在一个较小的范围内变化;③ 浅层参数与深层参数一起训练,后两种称之为 “Fine-Tuning”。(实际上,一般人们说的 Fine-Tuning 指的是目标任务模型整个训练过程)
![]()
这么做的好处是,首先我们可以在较少的任务数据下训练一个可用的模型。其次,预训练模型具有可复用性。比如,这次我们需要的是“大象狮子”分类器,下次我们需要“熊猫老虎”分类器,仍然可以使用预训练的模型参数。再次,加载预训练模型参数的目标模型在训练的时候收敛速度更快,效果更好。最后,随着开源社区的发展,很多大公司比如微软、谷歌都愿意将自己的模型开源。这些机构通常有海量的数据和计算资源,使得它们能够在完成海量数据的训练任务,这样它们开源出来的预训练模型本身就是一个非常优秀的模型,对于下游的任务而言有非常大的帮助。因此,这种 Pre-Training + Fine-Tuning 的模式在图像领域很快就流行起来了。
一个自然而然会产生的问题是:预训练方法为什么有效?
这其实就是知识的成功迁移。以人脸识别为例,对于层级 CNN 模型来说,不同层的网络学习到了不同的特征:最底层学习到了线段特征;第二层学习到了人脸的五官轮廓;第三层学习到了人脸的轮廓……研究发现,越浅层的网络学习到的特征越基础,越具有通用性。

既然预训练方法具有如此神奇的功效,为什么只在图像领域有效?为什么没有引入到自然语言处理领域呢?实际上这两个问题是不成立的,因为预训练方法很早就有人用在了自然语言处理领域,但是并没有取得像图像领域那么大的成功。下面我们就聊一聊 NLP 领域的预训练。
2.2 Word Embedding
语言是人类智慧的结晶,想要将计算机发展成一种具有通用智能的系统,对人类语言的理解是一个不可或缺的能力,由此诞生了自然语言处理(NLP)这门学科。对于自然语言来说,词 被认为是构成语言的有意义的最小单位,对于更高级的结构,比如词组、句子则是由词构成的,对于更低级的结构,比如单个字、字母通常是没有意义的。因此,如何将词转换成计算能够理解的表达(称之为“词向量”)就变成了一个非常重要的任务。
2.2.1 ASCII 码表示法
一个最基础的想法是,计算集中的每个字(字母)都对应一个 ASCII 码,由于词是由字构成的,那么我们可以使用每个字对应的 ASCII 码组成的序列来表示词。比如:“desk“ 和 ”table“,可以分别表示成:
1 | desk: 01100100 01100101 01110011 01101011 |
但是这种表示法有一下几个缺陷:
- 变长。由于词是由不同个数的字组成的,使用这种方式表示的词的长度也是变化的,不利于矩阵运算;
- 稀疏。以英文为例,英文字母有26个,英文单词通常由 1-20 个字母组成,为了说明问题我们这里取 10 作为平均数。这 26 个字母有 $26^{10}$ 种排列组合方式,但实际上的英文单词个数远小于这个数。也就是说,真正的英文单词在这种排列组合情况下式非常稀疏的。这种稀疏化的表示方法会给后续的工作带来一系列问题,比如存储、计算等。
- 无法表达词与词之间的关联性。比如上面的 “desk” 和 “table” 都有 “桌子” 的意思,那么他们应该具有相似的语义。但是这种 ASCII 码表示法完全无法将这种语义关联性表示出来。
2.2.2 One-Hot 表示法
给定一个固定的词表:$\mathcal{V}=\{w_1, w_2, …, w_{|\mathcal{V}|}\}$。我们使用一个维度为 $\mathcal{|V|}$ 的向量对每个词进行编码,这个向量中对应该词在词表中的索引的维度为 1, 其余为 0:
举个例子, 假设我们的词表为 [desk, table, apple, orange],那么词表中的每个词可以用 one-hot 表示成:
1 | desk: [1, 0, 0, 0] |
看起来 one-hot 的表示形式比 ASCII 码表示形式要好一些,至少每个词都有了固定的长度,而且不存在使用字母进行排列组合导致的词稀疏问题。在传统的机器学习算法上, 比如最大熵、SVM、CRF 等模型上,one-hot 表示法都是非常常见的。但是,这种表示法仍然存在问题:
- 稀疏。从上面的定义我们可以看出,词的维度和词表的大小是一致的,那么如果一个词表过大会造成词向量(简单理解为词的向量化表示)的维度过高,而一个词中只有一个维度的值是 1, 其余全部是 0,这样也会造成高维稀疏化问题;
- 同 ASCII 码表示法一样,无法表达词与词之间的关联性;
- 如果遇到新词需要添加到词表中,词表中的每个词的维度都需要相应的增加,这样在实际使用过程中是非常不方便的, 甚至有可能会导致一些问题。
2.2.3 向量空间模型
Harris 和 Firth 分别在 1954 年和 1957 年提出了分布式假设(distributional hypothesis):
对于语义词表示学习而言,具有相似分布的的语言对象具有相似的含义。
也就是说,如果两个词具有相似的分布,那么它们的语义也具有相似性。这个假设为后来的分布式词表示法奠定了基础。
Salton 等人于 1975 年提出向量空间模型(Vector Space Model),该模型最初是为了在信息检索中对文档进行建模,但是随着它的成功应用,逐渐扩展到其他领域。向量空间模型将词表示成一个连续向量,向量空间表示语义空间。
比如,[desk, table, apple, orange] 我们可以表示成:
1 | desk: [0.1, 0.2, 0.5] |
这样做的好处是:
- 我们可以就算两个向量之间的距离,用于表示语义相似性;
- 向量维度可以大大降低;
- 由于是连续性分布,所以不存在稀疏性问题。
早期的向量空间模型主要是基于词频统计(共现矩阵)的方法,比如布朗聚类(Brown Cluster),潜在语义分析(Latent Semantic Analysis)等方法。然而这些方法通常会存在参数量过大以及需要某种程度的降维等问题。因此仍然具有一定的局限性。
2.2.4 词嵌入表示法
Word Embedding 通常翻译为词嵌入,实际上也属于 distributed representation,这里特指使用神经网络训练得到的词向量。
随着神经网络技术的发展,深度学习掀起了机器学习的革命风潮,词向量的研究也迎来了新的转机。谷歌于 2013 年发表的 Word2Vec 模型可以说是词嵌入的里程碑式模型。它能够从大量的语料中高效的学习到词向量。Word2Vec 几乎解决了以上提到的所有问题。
在介绍 Word2Vec 之前,我们先回顾一下词向量的发展。
- FFNNLM
词向量通常是在训练语言模型的时候得到的副产物。前面我们在介绍 FFNN 语言模型的时候说过,词向量最初就是在训练在该模型中第一次通过神经网络训练得到的。
在 FFNN 语言模型中,有一个 $C$ 矩阵,该矩阵就是词向量。开始训练之前,将矩阵中的参数随机初始化,利用梯度下降对模型进行训练,模型训练结束的时候也表明,$C$ 矩阵得到了充分的训练,即词向量训练完成。
- SENNA
Ronan Collobert 和 Jason Weston 在 2008 年提出了一种新的词向量训练方法,并开源了他们的方法——SENNA。实际上最初他们并不是想训练一份好的词向量,甚至不想训练语言模型,而是想要去完成 NLP 中的各种任务,比如词性标注、命名实体识别、语义角色标注等。
SENNA 的训练思路是对一个窗口中的 $n$ 个连续的词进行打分,而不是预测下一个词的概率。这实际上是直接尝试近似求解 $p(w_{t-n+1}, …, w_{t-1}, w_t)$,打分越高说明越接近正常的话,打分越低说明越不像一句正常的话。有了这个假设,就可以定义目标函数:
其中 $\mathcal{X}$ 为训练接中素有连续 $n$ 元短语,$\mathcal{D}$ 表示整个词表。 第一个求和相当于选取训练语料中的所有 $n$ 元短语作为正样本,第二个求和相当于随机选择词表中的词构建负样本,构建方法就是将短语 $x$ 最中间的词替换为 $w$,即$x^{(w)}$。这样构建负样本的好处是,通常情况下,一个正常的 $n$ 元短语被替换掉中间的词之后确实会变成负样本,这样保证负样本的可靠性,即使出现替换掉之后仍然是正样本的情况,也属于少数情况,不影响大局;另一方面,由于负样本仅仅是修改了正样本中的一个词,不会让正负样本距离太大影响分类效果。最后希望正样本的打分要比负样本的打分至少高 1 分。
SENNA 模型的整体结构与 FFNNLM 类似,但是由于 SENNA 最后的输出是一个分数而不是下一个词的概率分布,因此输出层只有一个节点,这样大大降低了计算复杂度。
- HLBL
HLBL 是 “Hierarchical Log-BiLinear” 的简称,该模型是 Andriy Mnih 和 Geoffrey Hinton 于 2007 年和 2008 年连续两年致力于神经网络语言模型和词向量训练的研究成果。从最基本的受限玻尔兹曼机(RBM)逐步发展出来的模型。
2007 年的文章 《Three new graphical models for statistical language modelling》 提出 Log-Bilinear 模型:
通常我们将形如 $x^TWy$ 的模型称之为 “Bilinear”,上式中 $C(w)$ 表示词向量。
我们仔细看这个模型会惊喜的发现,这不就是注意力机制吗?$H_i$ 相当于是注意力权重,计算结果就是 $w_i$ 和 $w_j$ 的相似度。(关于注意力机制的介绍可以看这里)
受限于当时计算机的内存和算力,最终模型只考虑了 3-5 个词的上下文,然后通过最后的 softmax 得到下一个词的概率分布。
由于这个模型最后做预测的时候还是用的 softmax 获得下一个词的概率分布,计算复杂度仍然很高。因此, Andriy Mnih 和 Geoffrey Hinton 在 2008 年又发表一篇论文 《A scalable hierarchical distributed language model》引入层级结构做最后的预测,该层级结构将 softmax 的 $O(|\mathcal{V}|)$ 复杂度降为 $O(\log_2(|\mathcal{V}|))$,大大提升了预测效率。
Goodman 在 2001 年的时候提出了一种加速预测下一个词的方法——基于分类的思想。简单来说,假设我们词表中有 10000 个词,在传统的方法是在这 10000 个词上做 softmax 获得每个词的概率分布,然后取出概率最大的词,这样我们需要计算 10000 次。如果我们将这 10000 个词进行分类,假设分成 100 个类别,每个类别 100 个词。这个时候我们的计算过程是,先用一个 softmax 计算下一个词是属于什么类别,然后再用一个 softmax 计算概率最大的类别中的词的概率分布,这样我们只需要两个 100 次的计算量,计算速度直接提升 50 倍。
基于这个思想,Frederic Morin & Yoshua Bengio 于 2005 年提出使用平衡二叉树来构建这种分类关系,能够将计算复杂度降到 $O(\log_2(|\mathcal{V}|))$。但是在他们的模型中分类使用的是 WordNet 中的 IS-A 关系,最后虽然达到了加速预测的效果,但是模型效果较差。
Andriy Mnih 和 Geoffrey Hinton 希望从语料中学习并能自动构建一棵平衡二叉树。他们采用 bootstrapping 的方法,从随机树开始,根据分类结果不断调整迭代,最后得到一棵平衡二叉树。
值得一提的是,在他们的模型中,同一个词可能出现在多个不同的叶节点上,这实际上表示一词多义现象。歧义是自然语言处理中的一个非常重要的问题,也是早期限制预训练技术在自然语言处理领域发挥作用的重要阻碍。但是Mnih 和 Hinton 并没有重视模型中的这一细节。
- MWP
Bengio 2003 年的论文最后提到了多义词的问题,Eric H. Huang 等人在其 2012 年的论文《Improving Word Representations via Global Context and Multiple Word Prototypes》 中给出了一种解决方案。从论文题目我们可以看出,作者主要有两个贡献,首先是改进了 SENNA 模型,从局部信息扩展到全局信息,得到了更好的词向量,这一部分不过多介绍。另一个更重要的工作是创新的使用多个词向量来表示多义词。
他们提出的方法是将每个词的上下文各取 5 个词,对这 10 个词的词向量使用 idf 做加权平均,然后对得到的平均向量做 k-means 聚类,根据聚类的结果给每个词打上标签,不同类别中的同一个词当成不同词,然后重新训练词向量。思想很简单,但是最后的效果还不错。
- Word2Vec
时间来到 2013 年,Mikolov 等人发表两篇开山之作—— Distributed Representations of Words and Phrases and their Compositionality 和 Efficient estimation of word representations in vector space 宣告着 Word2Vec 的到来。相比于之前的工作,Word2Vec 极大的降低了计算复杂度,从而使我们能够在超大规模的语料上学习更高维的词向量。
Word2Vec 提出了两种新的模型架构:CBOW 和 Skip-Gram。CBOW 的核心思想是从一个窗口中将中间的词扣掉,然后利用这个词的前后几个词来预测中间的词;Skip-gram 正好相反,利用中间的词来预测两边的词。
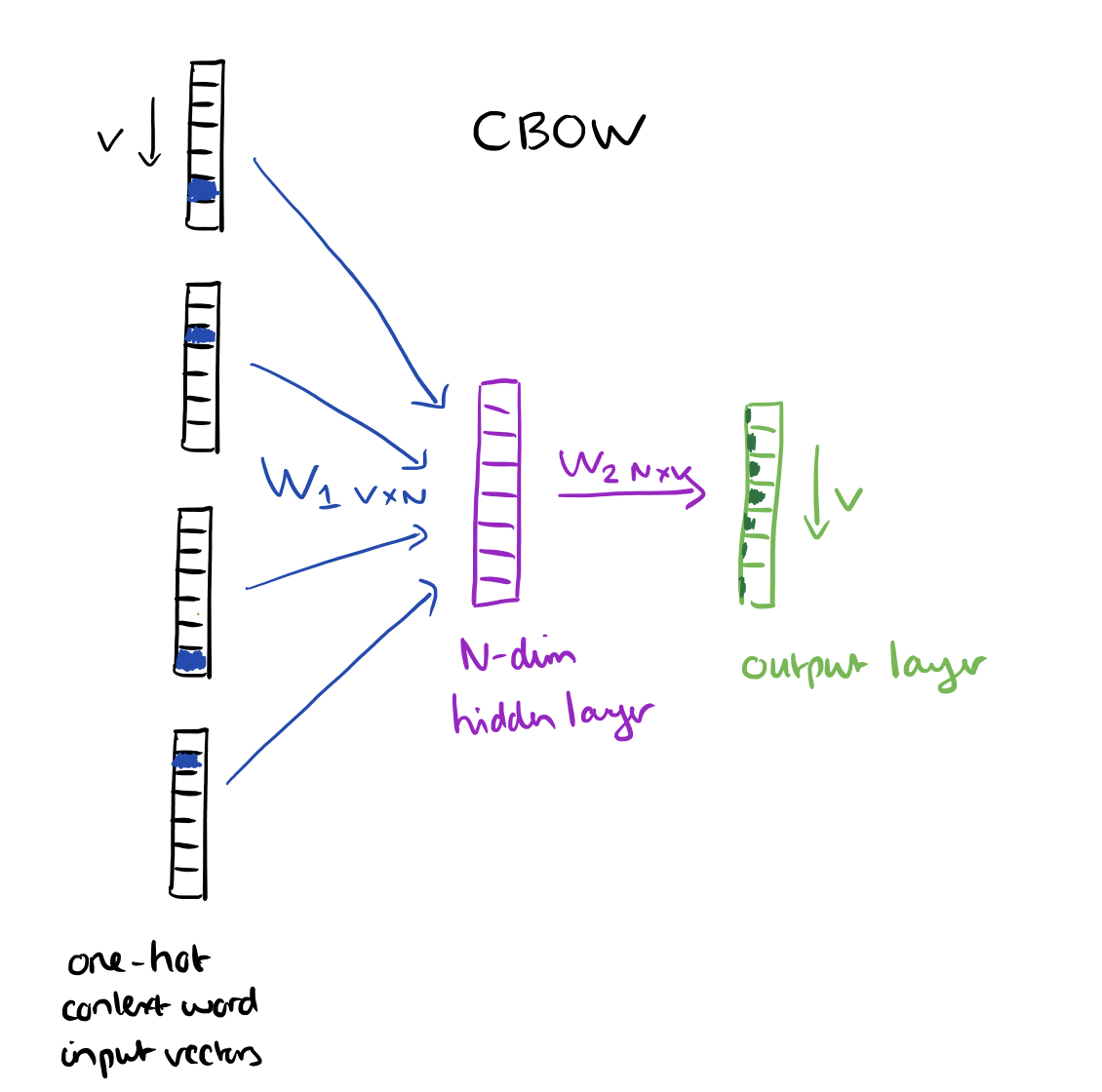 |
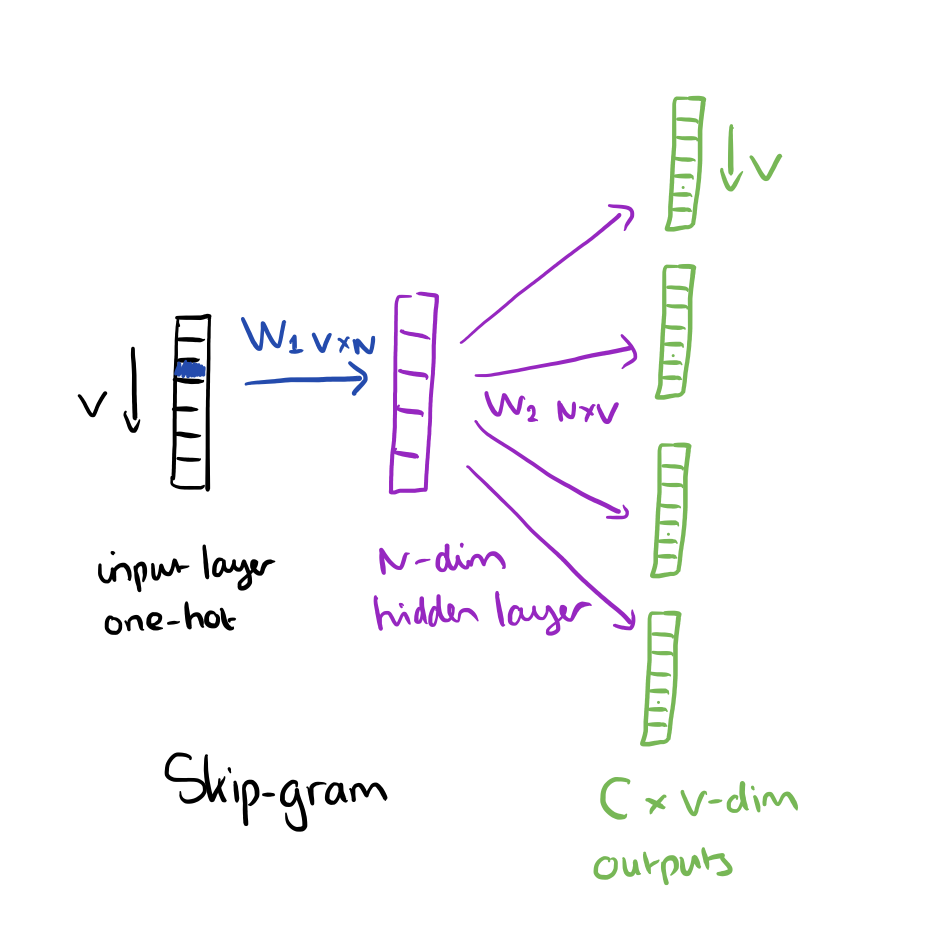 |
模型结构和 FFNN 语言模型的结构类似,不同点在于,FFNN 语言模型是利用上文预测下文,对于 FFNN 语言模型来说,词向量只是一个副产物,但对于 Word2Vec 来说,词向量才是主产物。
如之前讨论的那样,直接对预测输出使用 softmax 计算,计算复杂度非常高,因此,作者提出两种优化方案:层级 softmax(Hierarchical softmax) 和负采样(Negative Sampling)。关于 word2vec 的公开资料非常丰富,这里就不再赘述。
2.3 词向量怎么用?
我们前面花了很大篇幅介绍了词向量,那么词向量和预训练有什么关系呢?实际上,对于 NLP 来说(至少在 2018 年之前)词向量对应 ImageNet 预训练的底层权重。

以分类任务为例,如果我们要从头开始训练一个分类模型,那么模型中的参数都是随机初始化的,模型的泛化能力很大程度上取决于数据量。如果我们能从海量的语料中学习一套词向量,在做分类任务的时候,使用预训练好的词向量对输入端的词向量矩阵做初始化,相当于我们在模型中注入了一定的先验知识。然后在后续的模型训练过程中,词向量矩阵不参与训练。这样有两个好处:1. 减少可训练参数,加快训练速度;2. 知识的迁移使得模型更具有泛化能力。
这个过程其实就是 NLP 中的预训练,与图像领域的预训练基本是一致的,只是 word embedding 只能初始化第一层,更高层就无能为力了,但通常 NLP 模型的深度也都比较浅。
既然采用的是基本相同的预训练方法,为什么在图像领域就取得巨大的成功,而在自然语言处理领域,不能说没有帮助,但是帮助非常有限呢?很显然,问题出在 word embedding 上。回想我们之前在介绍 Huang 等人提出的训练词向量的方法,一个非常重要的任务就是解决一词多义的问题。
在通常的 NLP 任务中,每个词对应的只有一个词向量,也就是只有一个语义。但一词多义在自然语言中是非常常见的现象,只用一个词向量是无法表达多个语义的。虽然 Huang 的方法是一个词训练多个词向量用来解决一词多义的问题,但是这种做法在 NLP 中并不常见,原因也很简单:1. 通常为了避免(缓解)OOV 问题,模型需要一个较大的词表,一般情况下,词向量的维度我们会选择 100-300 维。这样的话,单单是在词向量矩阵这部分就包含了几百上千万的参数,如果再考虑一个词对应多个词向量,那么这个数字还要大上几倍;2. 即使我们采用了一个词对应多个词向量的方法来解决一词多义的问题,那么每个词在具体的句子中要使用哪一个词向量呢?这也是一个问题。如果再在模型层面解决词向量选取的问题,那我们会发现,一个简单的分类模型的重点反而成了解决歧义问题,整个模型就显得头重脚轻。
2.4 Sentence Embedding
既然词可以变成向量,那么句子是不是也可以变成向量呢?如果我们把句子变成向量是不是就不需要考虑词的多义性问题了呢?
2.4.1 Paragraph vector
2014 年,Mikolov 在提出 word2vec 不久之后就提出 paragraph vector 的设想,从论文题目《Distributed Representations of Sentences and Documents》就不难看出,他是想将句子和篇章也表达成固定维度的分布式向量。文章中他借鉴了 CBOW 和 Skip-gram,提出 PV-DM 和 PV-DBOW。
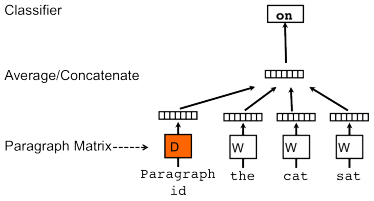 |
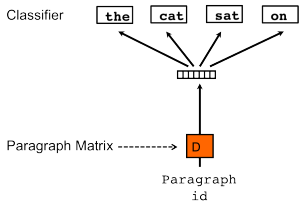 |
| PV-DM | PV-DBOW |
- PV-DM
PV-DM(Distributed Memory Model of Paragraph Vectors),通过上文预测下一个词,但是在输入层的时候不仅输入上文的词,还需要输入一个文档的 id,然后模型预测下一个词。由于输入多了一个文档 id, 因此我们还需要另外维护一个文档表(look-up table),用于通过 id 查找到对应的向量。训练结束后,对于现有的文档,便可以直接通过查表的方式快速得到该文档的向量,而对于新的一篇文档则需要将重新分配一个 id 给他,添加到 look-up table 中。然后重新训一遍模型,此时其他参数是固定的,只需要更新 look-up table 即可,收敛后便可以得到新文档对应的向量了。
- PV-DBOW
PV-DBOW(Distributed Bag of Words version of Paragraph Vector)是通过文档来预测文档中的词。首先先随机选取一个文档片段,然后随机从片段中选取一个词,然后让模型去预测这个词。和上面一样,如果此时有一个新的文档,要想获得它的向量,我们需要重新跑一遍模型。
由于上面两种方法都需要重新训练来获得新的文档向量,因此这两种方法并没有得到广泛应用。
2.4.2 Skip-thoughts
2015 年,Kiros 等人借鉴 Skip-gram 的思想提出 Skip-thoughts 方法。Skip-gram 是根据一个词去预测它的上下文,这里的基本单位是词,而 Skip-thought 的基本单位是句子。具体来说就是,利用当前的句子预测前一句和后一句。

首先利用 RNN 对当前句子进行建模,然后再用一个 RNN 来生成上一个句子和下一个句子。本质上这其实就是 encoder-decoder 结构的 seq2seq 模型,只不过 Skip-thoughts 有两个 decoder。
2.4.3 Quick-thoughts
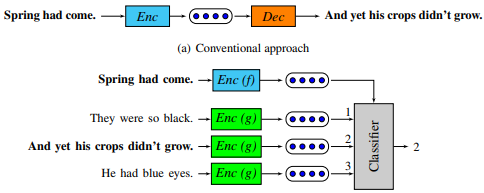
2018 年,Logeswaran 等人觉得 Skip-thoughts 的 decode 效率太低,且无法在大规模的语料上很好的训练。所以,他们把预测上下句的生成任务变成了分类任务,提出了 Quick-thoughts。具体来说就是,选取一个窗口,把窗口内的句子标记为正例,窗口外的句子标记为负例,将这些句子输入模型,让模型判断这些句子是否是同一个窗口的句子。(几个月后的 BERT 也借鉴了这一思路)
2.4.4 InferSent
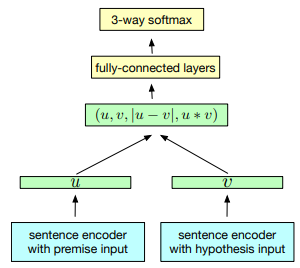
除了上述的无监督任务,研究人员还在监督学习任务上进行了尝试。比如 Conneau 等人提出 InferSent 模型,基本思想是先在 SNLI (Stanford Natural Language Inference)数据集上训练一个特征提取器,然后利用这个特征提取器将句子转化成向量,再将句子向量应用于分类任务上,以此来判断句向量的质量。
2.4.5 General Purpose Sentence Representation
除了单任务的预训练,Subramanian 等人在 2018 年还提出使用多任务来预训练模型。他们在 2018 年发表的论文《Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning》提出使用多任务联合学习来对模型进行预训练。论文中包含四种任务:Natural Language Inference, Skip-thougts, Neural Machine Translation 以及 Constituency Parsing,作者希望通过不同侧重点的任务,而不是特定任务来学习句子表征,达到 general 的目的。
具体的做法还是先在以上四个任务上做联合预训练,预训练好的模型保持不变,顶层添加一个全连接层作为分类器,然后训练一个新的分类器。在训练分类器的过程中,原来预训练的部分不参与训练,只训练顶层的全连接层。最后的实验结果也表明这种训练方式的有效性。
2.4.6 Universal Sentence Encoder
同样在 2018 年,Daniel Cer 等人提出了和 General Purpose Sentence Representation 相同的方法,只是将其中的网络替换成了 Transformer。最后结果发现,利用 Transformer 作为特征提取器效果更好。
2.5 小结
直到此时我们会发现,人们对于应该如何在 NLP 上进行预训练还是没有一个清晰的认知。比如,采用什么网络结构,在什么任务上进行预训练,怎样使用预训练的模型等等问题都还是处在一个摸索的阶段。我们也应该看到,虽然没有形成统一的认识,但是一个大致的发展脉络已经隐约可见了,从最初的只使用词向量,到后来开始考虑上下文,再到直接使用预训练模型进行特征抽取;从最初使用简单的 DNN,到后来使用 RNN 或 LSTM,再到 Transformer 的尝试等等,都逐渐呈现拨开云雾见光明的趋势。虽然经历了在不同的任务上进行预训练,但是在语言模型上的尝试也在快速发展,接下来就是预训练语言模型的舞台了。
3. 预训练语言模型
在这部分,我们先简单介绍预训练语言模型的发展历史,随着预训练语言模型的发展,产生了不同的技术流派,我们也将对这些技术流派进行简单的梳理。
3.1 预训练语言模型发展简史
首先我们将预训练语言模型的发展分成几个时期:
- 2015 年至 2017 年:技术探索期
- 2017 年至 2018 年:技术成长期
- 2018 年:技术爆发期
- 2019 年至今: 百家争鸣期
3.1.1 技术探索期
2015 年,Andrew M. Dai 和 Quoc V. Le 首次尝试先使用语言模型在大规模无标注语料上进行预训练,然后以整个语言模型来初始化下游的分类模型的方法。
他们的提出两种预训练方法:
使用 LSTM 训练一个标准的语言模型,即根据上文预测下一个词;
使用 LSTM 作为序列自编码器,将整个序列输入到模型中,将序列编码成一个固定维度的向量,然后根据这个向量去预测输入序列本身。
然后使用训练好的 LSTM 权重去初始化一个 LSTM 分类模型,发现上述两种预训练方法不仅提升了模型的分类效果,而且在更多的相关数据集上进行预训练可以极大的提升泛化能力。
2017 年 4 月, AllenAI 研究小组提出了一个模型——TagLM,如下图所示:
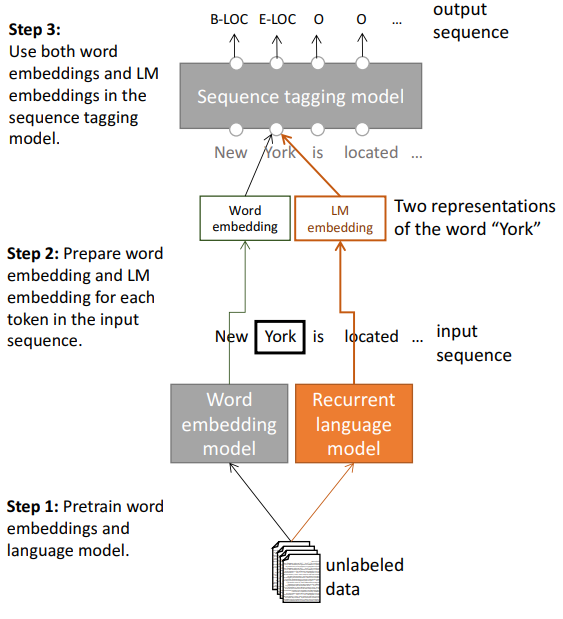
可以看到,模型采用两段式训练方法(虽然写了三个步骤):① 从无标记的数据中学习词向量和语言模型,② 将句子作为输入传递给训练好的语言模型,然后将语言模型的输出与 RNN 第一层输出拼接在一起作为序列标记任务模型的输入传递给下游序列标记模型,然后训练下游模型。这个思路与后来的 ELMO 模型是基本一致的,而且由于 ELMO 也是 AllenAI 小组的研究成果,因此我们可以认为 TagLM 模型是 ELMO 的一次初探。
2017 年 8 月,McCann 等人从机器翻译角度出发,训练了一个两层 Bi-LSTM 的 seq2sqe 翻译模型。然后,将训练好的 encoder 部分拿出来作为预训练的权重用于分类任务。
2018 年 1 月,Howard 等人提出的 ULMFiT 开始对 NLP 中的预训练方法展开了另一次新的尝试:
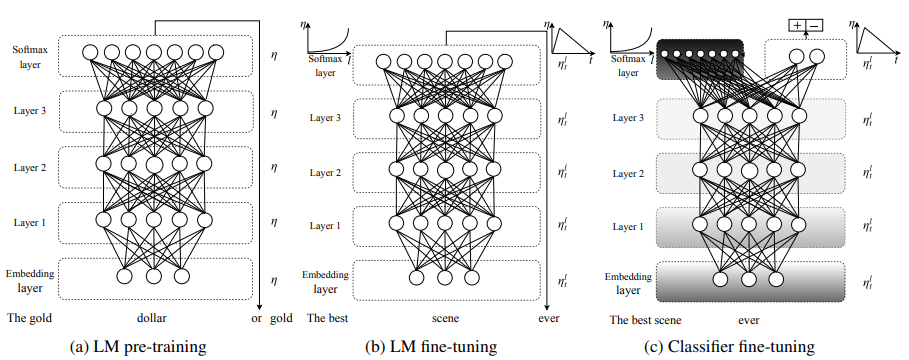
该模型采用的是三段式训练方法:① 在通用语料上训练词向量和语言模型;② 在专业领域语料上对词向量和语言模型进行 fine-tuning;③ 将训练好的语言模型作为句子特征提取器应用于下游分类任务。
可以看到,以上这些工作已经初现了现在的预训练方法:① 多段式训练,先在相关的数据上预训练一个模型,然后在具体任务数据上进行微调;② 不再只是单纯的使用预训练的词向量,而是开始考虑使用上下文。
这个时期的预训练更多的是尝试性的工作,比如应该如何训练语言模型,预训练的模型该怎么应用到下游任务等等。随着各种技术尝试的开展,从最开始的发散式尝试,逐渐开始有了一些技术聚焦点:从语言模型角度进行更多的尝试,采用双向 LSTM 网络结构,预训练方法在分类和序列标注任务上都有不俗的表现,这些都为后来的技术成长做好了铺垫。
3.1.2 技术成长期
- EMLo
ELMo 全称 “Embedding from Language Models”,其核心点在于它的论文名《Deep contextualized word representations》,即根据上下文(动态)生成词向量。比如:“我喜欢吃苹果”和“我喜欢苹果手机”,这两句话中的“苹果”分别表示两种含义,他们的词向量应该是不同的,那么 ELMo 可以根据这两句话表达的语义给“苹果”生成两个不同的词向量。
ELMo 是一个两段式训练模型:先在语料上训练一个语言模型,然后利用训练好的语言模型去动态生成词向量,应用于下游任务。第一阶段训练语言模型使用的是双向 LSTM 网络,所谓双向 LSTM 就是一个前向 LSTM 和 一个后向 LSTM,前向 LSTM 通过给定的前 $k-1$ 个词预测第 $k$ 个词,后向 LSTM 就是通过给定的反向的 $k-1$ 个词预测第 $k$ 个词。
假设模型有 $L$ 层双向 LSTM,那么我们可以得到 $2L+1$ 个向量:前向和后向各一个向量,加上输入层的词向量。
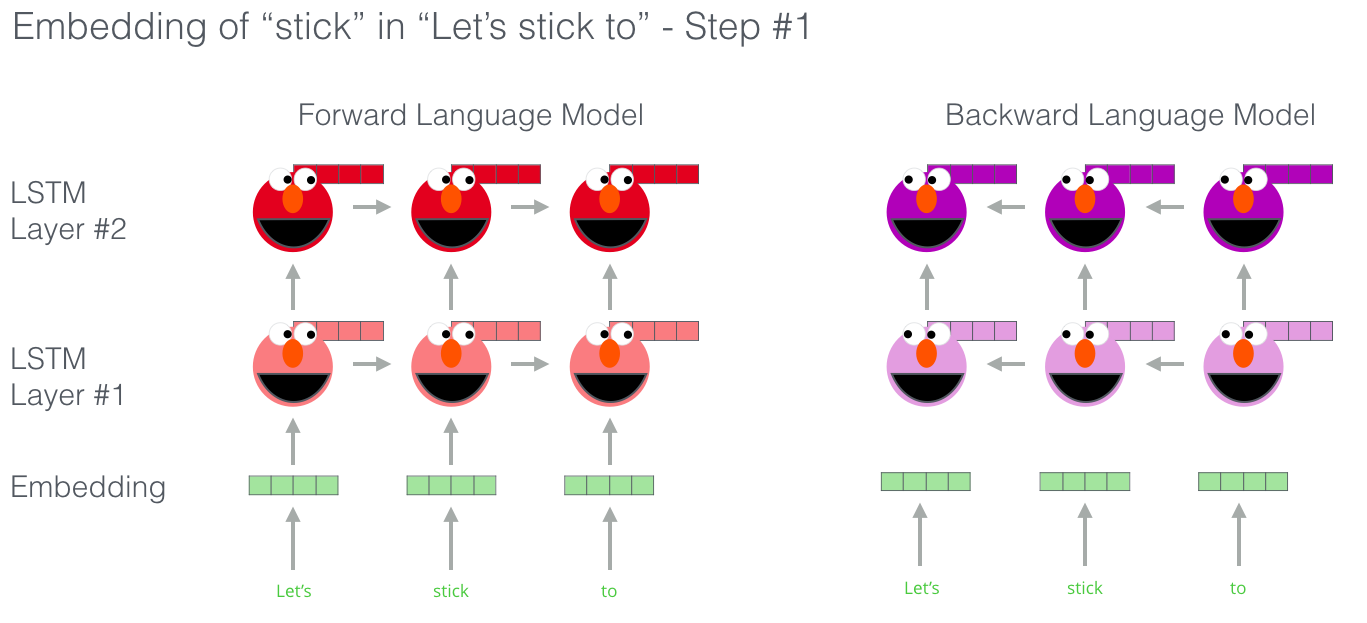
语言模型预训练好以后,在下游任务中我们怎么用这 $2L+1$ 个向量呢?首先是将每层的前向和后向的向量拼接在一起,然后对每层的向量进行加权求和,每层的权重可以通过学习得到。求和之后再进行一定程度的缩放,将缩放后的向量与输入层的词向量再进行加权求和。这样我们就将 $2L+1$ 个向量整合成了一个向量,然后将这个向量作为下游任务的输入,训练下游任务模型。
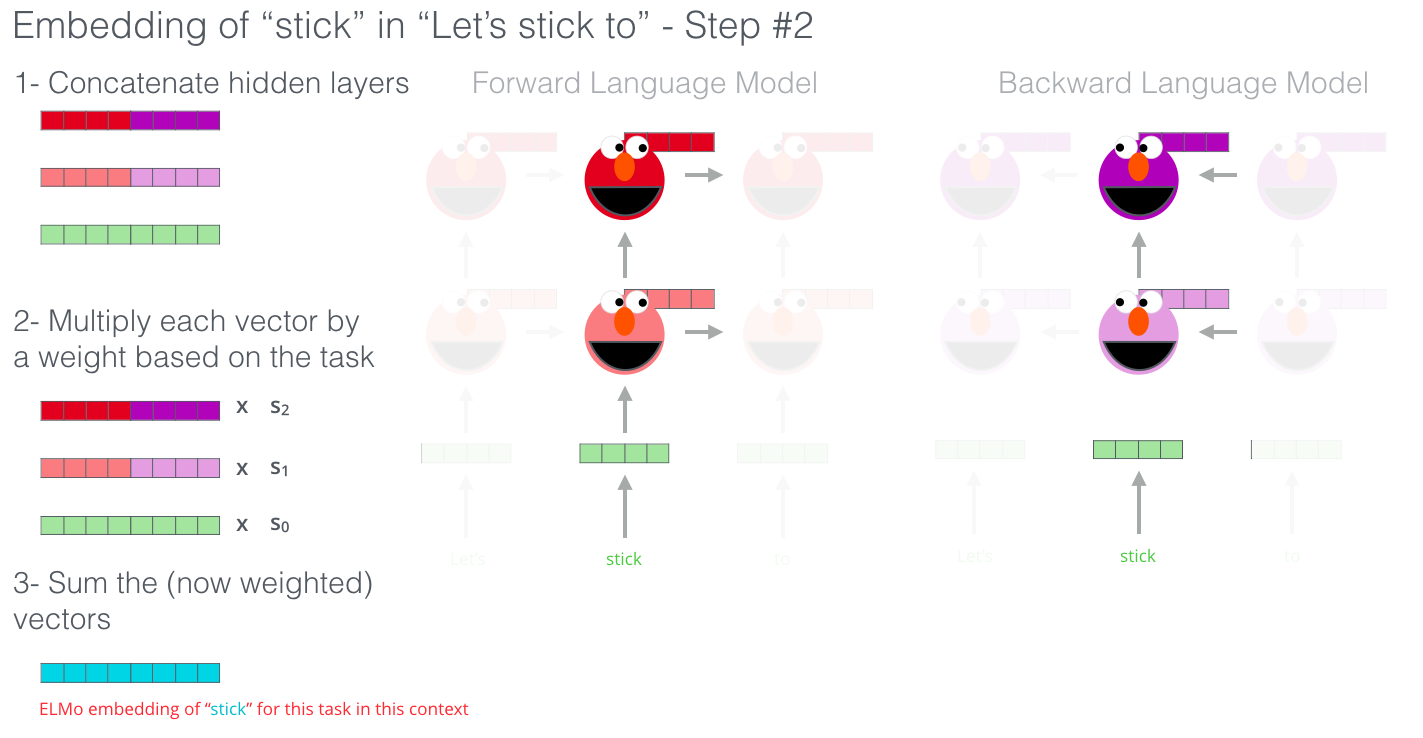
在实验中,作者使用的是两层的双向 LSTM,第一层学习到语法信息,第二层学习语义信息。从上面我们可以看到,ELMo 相比于之前的工作,并没有本质上的创新,基本上是对前人工作的引申和扩展,但是他的效果又是如此的惊艳,在 2018 年初的时候横扫了 NLP 中 6 大任务的最好结果。
那么 ELMo 有什么缺点呢?
- 2017 年谷歌提出了 Transformer 模型,很多研究表明 Transformer 的特征提取能力是要强于 LSTM 的,比如我们上面提到的 Universal Sentence Encoder;
- ELMo 采用的特征融合方法还是比较传统的拼接加权求和等方式,相比于后来的 BERT 的一体化融合方式,融合能力弱了一些。
- ELMo 是基于特征融合的方式来影响下游任务的,而从 ImageNet 的角度来看,也许 fine-tuning 的方式更适合下游任务(知识迁移)。
- GPT
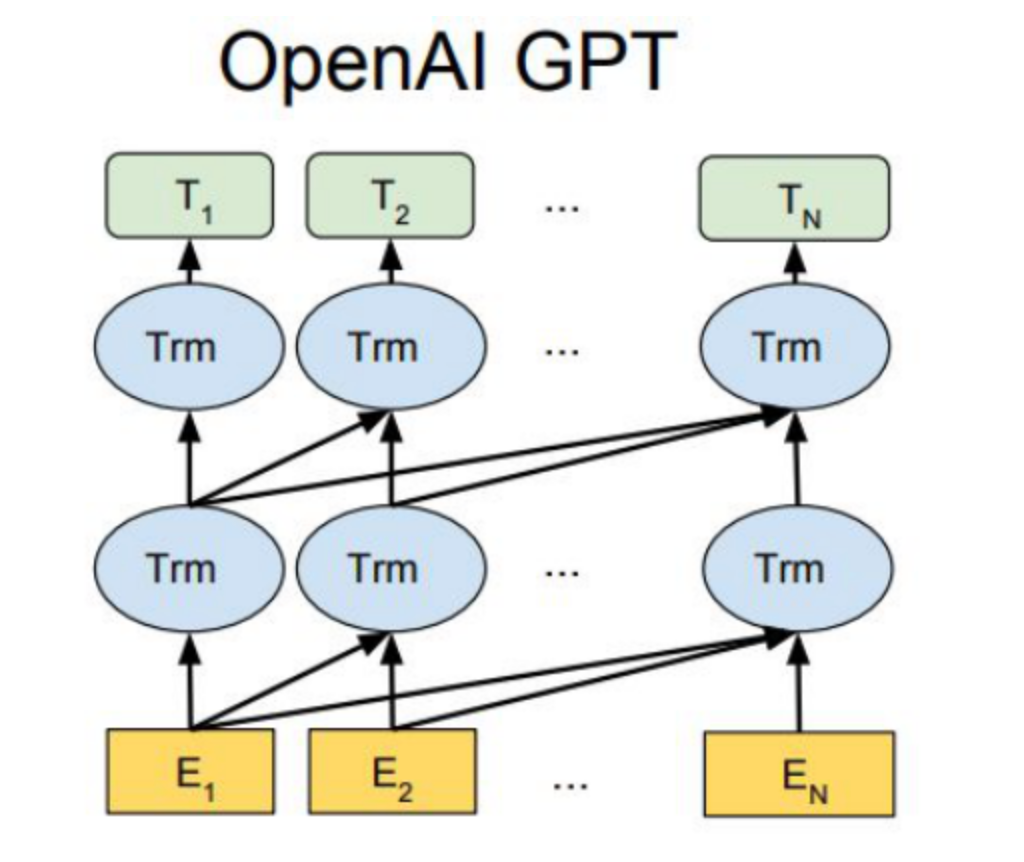 |
GPT 全称 Generative Pre-Training,模型的大致结构如上图左侧所示。GPT 与之前的预训练模型一样,首先是预训练一个语言模型,然后将语言模型应用到下游任务。它与 ELMo 的不同点在于:
- 采用 Transformer 作为特征抽取器;
- 采用的是单向的语言模型;
- 将预训练和 fine-tuning 的结构进行统一,不再需要特征融合。
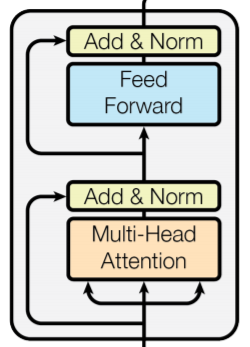
其中 Transformer 部分是经过改造的 decoder 层,如上图右侧所示。由于原始的 Transformer 是 encoder-decoder 结构的机器翻译模型,在 decoder 部分需要与 encoder 语义融合所以多了一个 multi-head attention 层,而在语言建模时,不需要语义融合,因此可以将其去掉。(更多关于 Transformer 的内容可参见【1】、【2】、【3】、【4】、【5】、【6】)
预训练好语言模型以后,怎么用到下游任务呢?以前的预训练语言模型在做下游任务的时候,可以任意设计自己的网络结构,而预训练语言模型只作为一个特征抽取器而已,在训练下游任务模型的时候,预训练的语言模型参数固定不变,只更新下游任务模型的参数。但是 GPT 说,我不要做配角,我要做主角!所以在利用 GPT 做下游任务的时候,我们需要把下游任务的网络结构设计成 GPT 的样子,利用预训练好的 GPT 初始化下游模型参数,然后利用任务数据对整个模型进行 fine-tuning。这样做的好处是,一来不需要特征融合(设计特征融合的方式也加入了过多的人工干预);二是和 ULMFiT 一样的思路,先在通用领域的是语料上预训练语言模型,在下游任务 fine-tuning 的时候相当于在训练下游任务的同时,也在利用领域语料 fine-tuning 语言模型,相比于 ULMFiT,GPT 更加简洁明了。
那么问题来了, NLP 的各种任务花样百出,怎么改造才能靠近 GPT 的网络结构呢?
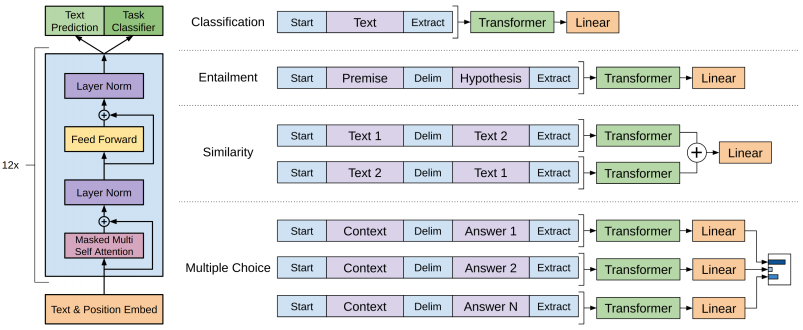
论文给出的改造方案也很简单:
- 分类问题:直接在文本前后加上开始和结束符号;
- 判断句子关系问题:在两个句子之间添加一个分隔符即可;
- 文本相似性问题:将两个句子顺序颠倒做出两个输入,句子间仍然添加分隔符,之所以做成两个输入主要是告诉模型,句子的顺序不重要;
- 多选问题:制作多路输入,每一路是将文章和答案选项使用分隔符拼接在一起即可。
从图中我们可以看出,不同 NLP 任务的改造并不困难,只需要修改输入部分即可。而输出部分也是一个简单的全连接层。
GPT 最终的效果也是相当的惊艳,在实验涉及到的 12 项任务中,9 个达到了最佳效果!
但是,由于 GPT 采用的是单向语言模型,使得 GPT 存在语言建模过程中信息不健全的固有缺陷,而正是这一缺陷给了后来者 BERT 的可乘之机。
3.1.3 技术爆发期
时间来到 2018 年 10 月 11 日,这是一个本来平凡到不能再平凡的日子,一切都很平静。但是随着 Jacob Devlin 及其合作者在 Arxiv 上悄悄的放了一篇他们的最新论文 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,犹如一声惊雷彻底打破了宁静。首先是在 Twitter 上引发了巨大的浪潮,随后中文各大社区包括但不限于微信公众号、微博等几乎被刷屏。狂揽 11 项 NLP 任务的最佳效果,彻底宣告预训练语言模型的王者降临。
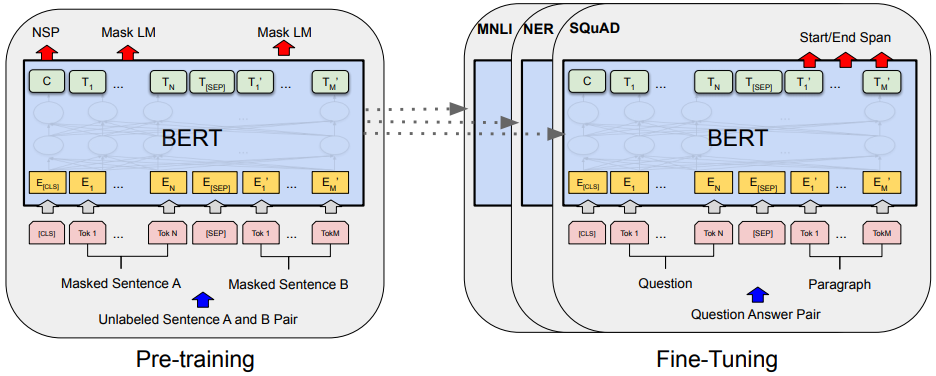
BERT 采用和 GPT 完全一致的两个阶段训练方式。与 GPT 最大的不同是采用了双向语言建模,为了防止双向语言建模时发生泄密,BERT 采用的是 Mask Language Model 方式训练语言模型。另外,BERT 还借鉴了 Skip-thoughts 的思想,通过预测下一个句子来获取句子信息(Next Sentence Prediction, NSP)。
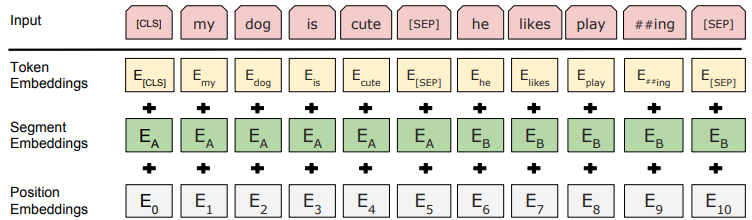
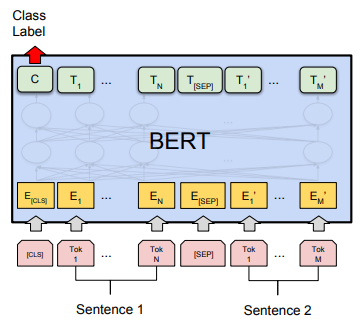
- 输入层
BERT 的输入包含三种 Embedding:Token Embedding, Segment Embedding, Position Embedding。其中 Token Embedding 和 Position Embedding 分别对应词向量和位置向量,这个不难理解。那个 Segment Embedding 是用于区分两种句子的向量,正如我们上面说的, BERT 不仅是从语言模型中得到信息,还有一个 NSP 任务。BERT 对 NSP 任务的处理方式和 GPT 类似,将两个句子用一个分隔符拼接在一起,如下图所示。
- Transformer Encoder
前面我们说,BERT 采用的是双向语言建模。我们知道 transformer encoder 是采用的自注意力机制,是一个并行结构,而不是像 LSTM 那样的串行结构。对于串行结构来说,我们将句子中的词按照正向顺序输入网络就得到正向模型,按照反向顺序输入模型就得到反向模型,将正向和反向的模型结合在一起就是双向模型。而对于并行结构来说,句子中的所有词是一起输入到模型中,并没有一个先后顺序,此时我们应该怎么理解 BERT 中的”双向“这个概念呢?
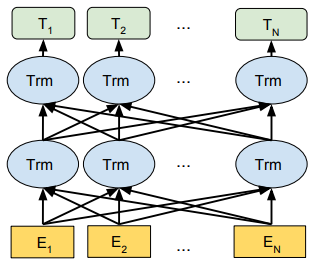 |
 |
如上左图,自注意力机制是将一句话中的每个词分别于其余的词计算点积(注意力权重),比如“我 爱 北京 天安门 。”,对于“北京”来说,当计算它与“我”、“爱”的注意力权重的时候即为前向,与“天安门”、“。”计算注意力权重的时候为后向。其实就是正常的自注意力的计算过程,被论文作者换了一个名字。
但是这里有一个问题,无监督的训练神经网络语言模型通常是使网络通过上文或者下文去预测当前的词,GPT 之所以用的是 Transformer decoder 很大程度考虑的也是通过 Mask multi-head attention 掩盖掉下文,避免下文信息泄露。而 BERT 直接采用 encoder 是对句子中的所有词都进行自注意力计算,这样就无可避免的会存在一个下文信息泄露。为了解决这个问题,Devlin 等人提出 Masked Language Model, 其核心思想就是随机将一些词替换成 “[Mask]” ,然后在训练过程中让模型利用上下文信息去预测被替换掉的词。其实它的本质和 CBOW 是一致的,只是说这里我们只预测 “[Mask]”。
但是这里会有一个问题:在训练的时候,训练数据中包含了大量的 “[Mask]”,但是在预测的时候,数据中是不包含 “[Mask]” 的,相当于认为地使在训练数据和真实数据产生了分布上的偏差,会使得模型在使用过程中出现问题。为了避免这个问题,BERT 的做法是:
随机挑选 15% 的词;
将选中的词中的 80% 替换成 [Mask];
将选中的词中的 10% 随机替换成其他的词;
将选中的词中的 10% 不变。
将 80% 的词替换成 [Mask] 是为了防止泄密,这个正如我们上面所说的。将 10% 的词随机替换成其他词,这样做的目的是使模型不知道哪些词被 [Mask] 了,迫使模型尽量学习每一个词的全局表征,使得 BERT 能更好的的获得上下文相关的词向量。将 10% 的词不做替换,是为了使模型得到一定程度的 bias,相当于是额外的奖励,将模型对于词的表征能够拉向词的真实表征。
- 输出层
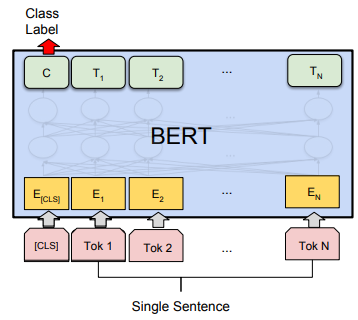
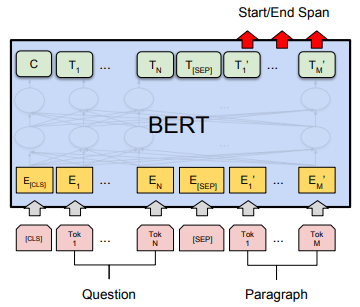
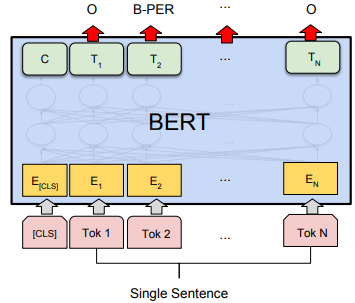
BERT 的下游任务主要有四种:句子关系分类、单句分类、阅读理解和序列标注。为了能适配这四种任务,BERT 设计了相应的输出层:
- 句子关系分类:输出序列的第一个位置后面链接一个 softmax 层用于分类;
- 单句分类:输出序列的第一个位置后面链接一个 softmax 层用于分类;
- 阅读理解:输出序列中每个词的分类,并将起始和终止位置中间的词取出即可;
- 序列标注:输出序列中每个词的分类,将对应列类别取出即可。
 |
 |
 |
 |
其实通过上面的介绍我们可以看出,BERT 本身的创新型并不强,算是一个前人工作的一个集大成者,类似于 Transformer 之于注意力。比如双向语言建模的特性是 Transformer encoder 自带的能力,Masked Language Model 实际上借鉴了 CBOW 的思想,而 NSP 则是借鉴 Skip-thoughts,在输出层的多任务适配更是借鉴了 GPT 的操作。
但是 BERT 的诞生也是具有划时代意义的:
- 明确了 NLP 的一个发展方向,两段式训练,双向语言模型,自注意力机制等都在后来的工作中大放异彩;
- 给了 NLP 一个做知识迁移的优雅的解决方案,单单是这一点就足以使 BERT 成为与计算机视觉中 ImageNet 相媲美的里程碑式成就,甚至可能比 ImageNet 更有意义,因为 BERT 预训练用的是无监督学习,无需人工标注,而 ImageNet 仍然是标注数据;
- 将 NLP 的发展推向了一个新的高度。在此之后,预训练语言模型迎来了爆发式的大发展,同时预训练语言模型也进入了百家争鸣的时代。
3.1.4 百家争鸣期
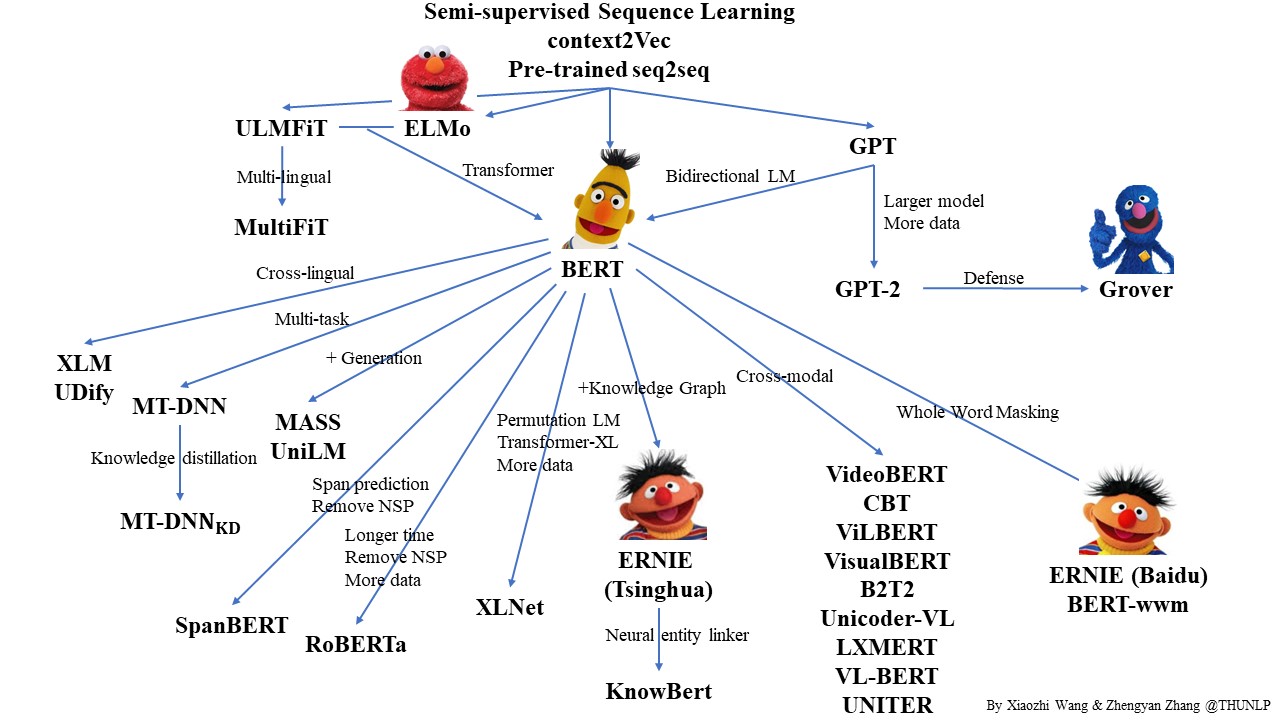
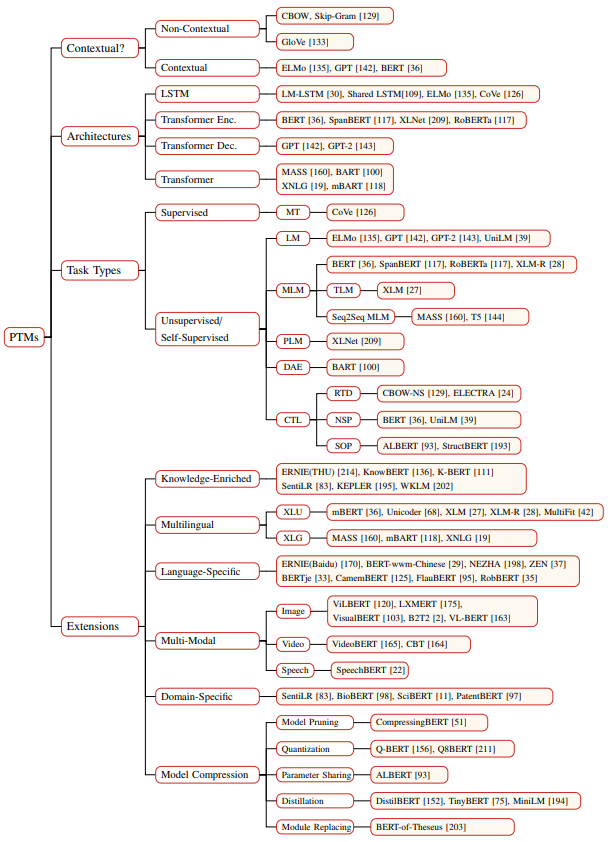
BERT 诞生以后,彻底掀起了预训练语言模型的研究热潮,有针对性 BERT 的各种改进版,有提出新思路的创新版。在短短两年的时间内,预训练语言模型已经发展成了一个大家族,为了厘清家族成员之间的关系,复旦大学的邱锡鹏老师小组对两年来预训练语言模型进行了一下梳理,并根据不同视角将预训练语言模型进行了分类:
- 根据向量表示法将模型分成:上下文相关模型和非上下文相关模型;
- 根据模型结构将模型分成:使用 LSTM 模型;使用 Transformer encoder 模型;使用 Transformer deocder 模型;使用 Transformer 模型
- 根据预训练任务类型将模型分成:Language Model;Masked Language Model;Permuted Language Model;Denoising Autoencoder;Contrastive Learning;
- 根据模型的外围扩展:知识增强型;多语言型;特定语言;多模态;特定领域以及压缩模型等。
3.2 小结
预训练语言模型在 NLP 各领域的强大能力令人兴奋,从 BERT 的提出到现在(2020.10.30)满打满算也不过两年的时间。预训练语言模型的发展也处于百花齐放的阶段,如同预训练技术在 NLP 的发展一样,经历了各种尝试,最后才发现了语言模型这条道路。预训练语言模型也一样,虽然现在每隔一段时间就会有一个新的模型出来刷榜,但是什么样的模型架构,以什么样的形式训练语言模型等等都还在处于探索阶段。在更高一层来看,目前的预训练语言模型并不能真正解决语言的认知能力问题。预训练语言模型的发展还远远没有达到成熟的阶段,但是基于这两年的发展,我们仍然能总结一些规律,也许能够使我们在往更强的模型发展上有迹可循。
首先,在保证数据质量的前提下,数据量越大,模型容量越大,训练越充分,预训练的模型效果越好;
其次,训练方式从传统的两段式扩展到四段式能达到更好的效果:
- 在大规模通用数据集上预训练大模型;
- 在预训练好的通用领域模型上利用领域数据再训练一个领域预训练模型;
- 在任务数据上,去掉标签,进行一次任务预训练;
- 最后再在具体任务上进行微调
再次,基于 Transformer 的架构往往能取得最佳效果,未来能否有新的架构取而代之我们拭目以待。
而目前预训练语言模型也存在着一些问题,比如有些新模型宣称能达到比 BERT 更好的效果,但实际上我们不能确定是因为新模型的模型结构在起作用还是由于它比 BERT 训练的更充分在起作用。也就是说,我们应该如何找到一个模型的能力上限是一个很重要的问题。另外,现在的预训练语言模型越来越大,训练数据越来越多,越来越考验计算硬件的能力,会将研究中心集中在一些资金充裕的地方,严重约束它的发展。
无论如何,预训练语言模型的成功使我们离 AI 更近了一步,目前存在的问题只有在一点一点的尝试、研究中去解决。
4. 为什么是语言模型?
我们回过头来看,NLP 有众多任务分支:阅读理解、机器翻译、语法分析、自然语言推理、语言模型等等,为什么最后是语言模型成了 NLP 的 ImageNet?
为了预测句子中下一个最可能的词,语言模型不仅需要学习到语法知识,还需要了解句子的语义。就像 ELMo 成功的关键就在于,他能从浅层获得句法特征,然后从深层获得语义特征一样。不仅如此,一个好的模型还要能从语料中学习到一些常识,比如 “The service was poor, but the food was”,为了预测下一个词,模型必须具备以下能力:
- 知道下一个词是用来描述 “food” 的;
- 知道 “but” 表示语义转折,并且知道对应的词是 “poor” 的反义词;
- 知道 “poor” 的反义词都有哪些。
语言模型能够获得与下游任务相关的信息,比如长程依赖、层级结构、感情信息等等。相比于 Skip-thoughts 和 autoencoding 等无监督的任务,语言模型更能获得语法信息(Kelly et al. 2018)。
而对于其他比如分类,机器翻译等任务来说,语言模型是无监督的。这样,语言模型的训练预料可以认为是无穷无尽的,而又无需人工标注。这一点对于 NLP 来说是至关重要的,目前世界上超过 1000 人使用的语言有 4500 多种,其中绝大多数的语言都是小语种,无论是直接获取语料资源还是进行人工标注,对于 NLP 任务来书都是巨大的挑战。有了无监督的语言模型,我们可以先在一些容易获取的,资源丰富的语言上先进性预训练,然后再在那些低资源(low-resource)语言上进行微调,对于小语种 NLP 的发展具有重要的意义。
从实际的发展来看,也印证了我们上面的说法,从 ELMo 到 BERT 正式开启了 NLP 的预训练时代,而这正是归功于预训练语言模型的发展。
Reference
- 02. 语言模型(language Model)发展历史 crazysnailer
- Can artificial neural network learn language models? W. Xu and A. Rudnicky
- A Neural Probabilistic Language Model Yoshua Bengio, Réjean Ducharme, Pascal Vincent, Christian Jauvin
- NLP’s ImageNet moment has arrived Sebastian Ruder, Andrey Kurenkov, Eric Wang, and Aditya Ganesh
- Recurrent neural network based language model T. Mikolov, M. Karafiat, L. Burget, ´J. Cernocky, and S. Khudanpur
- LSTM neural networks for language modeling M. Sundermeyer, R. Schluter, and H. Ney
- RNN Language Models Chainer
- 迁移学习简明手册 王晋东
- Transfer Learning - Machine Learning’s Next Frontier Sebastian Ruder
- What is ImageNet and Why 2012 Was So Important GE Healthcare
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张俊林
- Embeddings in Natural Language Processing——Theory and Advances in Vector Representation of Meaning Mohammad Taher Pilehvar, Jose Camacho-Collados
- A synopsis of linguistic theory John R Firth
- Distributional structure Zellig S Harris
- Class-based n-gram models of natural language Peter F Brown, Peter V Desouza, Robert L Mercer, Vincent J Della Pietra, and Jenifer C Lai
- A vector space model for automatic indexing Gerard Salton, A. Wong, and C. S. Yang
- Representation Learning for Natural Language Processing Liu, Zhiyuan, Lin, Yankai, Sun, Maosong
- A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning Ronan Collobert, Jason Weston
- Natural Language Processing (Almost) from Scratch Ronan Collobert, Jason Weston, Leon Bottou, Michael Karlen, Koray Kavukcuoglu, Pavel Kuksa
- Three new graphical models for statistical language modelling Andriy Mnih, Geoffrey Hinton
- A scalable hierarchical distributed language model Andriy Mnih, Geoffrey Hinton
- Classes for fast maximum entropy training Goodman, J.
- Hierarchical probabilistic neural network language model Frederic Morin & Yoshua Bengio
- Improving Word Representations via Global Context and Multiple Word Prototypes Eric Huang, Richard Socher, Christopher Manning, Andrew Ng
- NLP的巨人肩膀(中) weizier
- Distributed Representations of Sentences and Documents Quoc Le, Tomas Mikolov
- Skip-Thought Vectors Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel, Antonio Torralba, Raquel Urtasun, Sanja Fidler
- AN EFFICIENT FRAMEWORK FOR LEARNING SENTENCE REPRESENTATIONS Lajanugen Logeswaran & Honglak Lee
- Supervised Learning of Universal Sentence Representations from Natural Language Inference Data Alexis Conneau, Douwe Kiela, Holger Schwenk, Loic Barrault, Antoine Bordes
- Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning Sandeep Subramanian, Adam Trischler, Yoshua Bengio, Christopher J Pal
- Universal Sentence Encoder Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St. John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, Yun-Hsuan Sung, Brian Strope, Ray Kurzweil
- Semi-supervised Sequence Learning Andrew M. Dai & Quoc V. Le
- context2vec: Learning Generic Context Embedding with Bidirectional LSTM Oren Melamud, Jacob Goldberger, Ido Dagan
- Semi-supervised sequence tagging with bidirectional language models Matthew E. Peters, Waleed Ammar, Chandra Bhagavatula, Russell Power
- Universal Language Model Fine-tuning for Text Classification Jeremy Howard, Sebastian Ruder
- 放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较 张俊林
- 乘风破浪的PTM:两年来预训练模型的技术进展 张俊林
- A Survey on Neural Network Language Models Kun Jing and Jungang Xu
- Pre-trained Models for Natural Language Processing: A Survey Xipeng Qiu, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai & Xuanjing Huang
- Deep Learning in NLP (一)词向量和语言模型 LICSTAR
- Neural Transfer Learning for Natural Language Processing Sebastian Ruder
- Adversarial Examples for Evaluating Reading Comprehension Systems Jia, R. and Liang, P. (2017)
- Synthetic and Natural Noise Both Break Neural Machine Translation Belinkov, Y. and Bisk, Y. (2018)
- Deep contextualized word representations Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer
- Language Modeling Teaches You More than Translation Does: Lessons Learned Through Auxiliary Task Analysis Kelly W. Zhang, Samuel R. Bowman
- Improving Language Understanding by Generative Pre-Training Alec Radford,Karthik Narasimhan,Tim Salimans,Ilya Sutskever
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
- 后 BERT 时代的那些 NLP 预训练模型 李理